
Please tell me if you find these sorts of posts useful. This one’s a bit windy, but it does lead somewhere, I promise!
What I wanted: a simple HTML dashboard (static HTML, no need for React/node.js – yet), that would summarize my ThatJeffSmith.com wordpress data. I have a hard time finding what I’m looking for there, so I want to vectorize the COMMENTS people leave on my posts, and build a similarity search around that.
How I built it: I basically vibe-coded the whole thing, in pieces. I’ll share the prompts and generate code, below.
Ingredients
What I used to cook this delicious dish:
- Oracle AI Database 26ai Free, required for AI Vector search feature
- Visual Studio Code
- Oracle SQL Developer extension for VS Code
- Oracle SQLcl, MCP Server for Oracle [AI] Database
- WordPress CMS MySQL Export of WP_POSTS and WP_COMMENTS tables
- Cline extension for VS Code
- Oracle Code Assist (OCI) and associated LLMs (grok4-fast-reasoning)
- An AI agent and subscription that rhymes with Maude
These components should be interchangeable with your preferred Agent and LLM, the main requirement is an Agent that’s well suited for doing development work.
Pre-work work
I took a JSON export of WP_COMMENTS and with the assistance from Cline, generated a python program to load it into my Oracle table – multiline comments are a real pain, so this was handy.
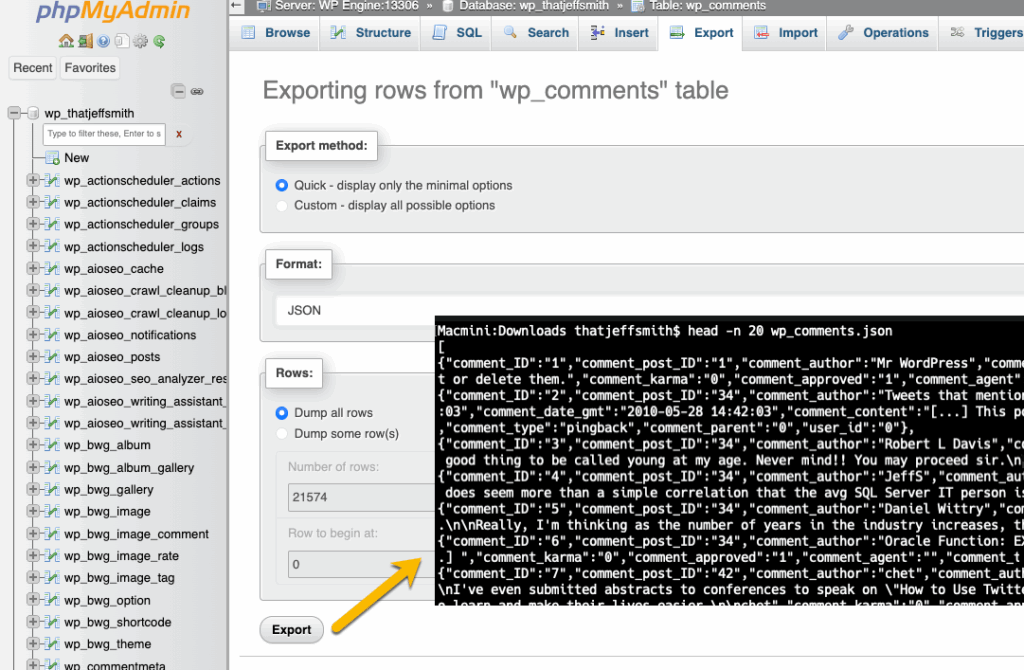
JSON means multi-line comments will be preserved
I used this prompt –
for the currently attached file, treat each row in the array as a row in a my wp_comments table in our Oracle Database, using our Raptor connection.
use the oracle database python driver to conenct to our database and do database work, create a python program to conenct to our database and load the data into the table
i will handle the connectivity details, you just help me transposing the json array items to new rows and the attributes to the columns
our for loop should issue a COMMIT every 500 rows processed
Cline happily generated this file, and even help me setup my env.
#!/usr/bin/env python3
"""
WordPress Comments JSON to Oracle Database Loader
This script reads the wp_comments.json file and loads the data into
the WP_COMMENTS Oracle table using batch processing with commits every 500 rows.
Requirements:
- pip install oracledb
"""
import json
import oracledb
from datetime import datetime
import html
import logging
import os
from dotenv import load_dotenv
# Set up logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
def parse_wordpress_date(date_string):
"""
Parse WordPress date format (YYYY-MM-DD HH:MM:SS) to Python datetime
"""
try:
return datetime.strptime(date_string, '%Y-%m-%d %H:%M:%S')
except ValueError:
logger.warning(f"Could not parse date: {date_string}")
return None
def clean_html_content(content):
"""
Clean HTML entities and excessive HTML from comment content
"""
if not content:
return None
# Unescape HTML entities
content = html.unescape(content)
return content
def load_wp_comments_data(json_file_path, connection):
"""
Load WordPress comments from JSON file into Oracle database
Args:
json_file_path (str): Path to the wp_comments.json file
connection: Oracle database connection object
"""
# SQL INSERT statement
insert_sql = """
INSERT INTO WP_COMMENTS (
COMMENT_ID, COMMENT_POST_ID, COMMENT_AUTHOR, COMMENT_AUTHOR_EMAIL,
COMMENT_AUTHOR_URL, COMMENT_AUTHOR_IP, COMMENT_DATE, COMMENT_DATE_GMT,
COMMENT_CONTENT, COMMENT_KARMA, COMMENT_APPROVED, COMMENT_AGENT,
COMMENT_TYPE, COMMENT_PARENT, USER_ID
) VALUES (
:comment_id, :comment_post_id, :comment_author, :comment_author_email,
:comment_author_url, :comment_author_ip, :comment_date, :comment_date_gmt,
:comment_content, :comment_karma, :comment_approved, :comment_agent,
:comment_type, :comment_parent, :user_id
)
"""
cursor = connection.cursor()
try:
# Load JSON data
logger.info(f"Loading JSON data from {json_file_path}")
with open(json_file_path, 'r', encoding='utf-8') as file:
comments_data = json.load(file)
logger.info(f"Found {len(comments_data)} comments to process")
# Process comments in batches
batch_size = 500
total_processed = 0
errors = 0
for i in range(0, len(comments_data), batch_size):
batch = comments_data[i:i + batch_size]
batch_data = []
for comment in batch:
try:
# Parse dates
comment_date = parse_wordpress_date(comment.get('comment_date'))
comment_date_gmt = parse_wordpress_date(comment.get('comment_date_gmt'))
# Clean and prepare data
row_data = {
'comment_id': int(comment.get('comment_ID', 0)),
'comment_post_id': int(comment.get('comment_post_ID', 0)),
'comment_author': comment.get('comment_author')[:255] if comment.get('comment_author') else None,
'comment_author_email': comment.get('comment_author_email')[:255] if comment.get('comment_author_email') else None,
'comment_author_url': comment.get('comment_author_url')[:500] if comment.get('comment_author_url') else None,
'comment_author_ip': comment.get('comment_author_IP')[:45] if comment.get('comment_author_IP') else None,
'comment_date': comment_date,
'comment_date_gmt': comment_date_gmt,
'comment_content': clean_html_content(comment.get('comment_content')),
'comment_karma': int(comment.get('comment_karma', 0)),
'comment_approved': comment.get('comment_approved', '1')[:20],
'comment_agent': comment.get('comment_agent')[:500] if comment.get('comment_agent') else None,
'comment_type': comment.get('comment_type', 'comment')[:50],
'comment_parent': int(comment.get('comment_parent', 0)),
'user_id': int(comment.get('user_id', 0))
}
batch_data.append(row_data)
except (ValueError, TypeError) as e:
logger.error(f"Error processing comment ID {comment.get('comment_ID', 'unknown')}: {e}")
errors += 1
continue
# Execute batch insert
if batch_data:
try:
cursor.executemany(insert_sql, batch_data)
connection.commit()
total_processed += len(batch_data)
logger.info(f"Processed batch: {total_processed} rows committed")
except oracledb.Error as e:
logger.error(f"Database error in batch {i//batch_size + 1}: {e}")
connection.rollback()
errors += len(batch_data)
logger.info(f"Data loading complete!")
logger.info(f"Total rows processed: {total_processed}")
logger.info(f"Total errors: {errors}")
# Verify the load
cursor.execute("SELECT COUNT(*) FROM WP_COMMENTS")
row_count = cursor.fetchone()[0]
logger.info(f"Total rows in WP_COMMENTS table: {row_count}")
except FileNotFoundError:
logger.error(f"JSON file not found: {json_file_path}")
except json.JSONDecodeError as e:
logger.error(f"Error parsing JSON file: {e}")
except Exception as e:
logger.error(f"Unexpected error: {e}")
connection.rollback()
finally:
cursor.close()
def main():
"""
Main function - loads environment variables for database connection
"""
# Load environment variables
load_dotenv()
# Get database connection details from environment variables
db_user = os.getenv('DB_USER')
db_password = os.getenv('DB_PASSWORD')
db_host = os.getenv('DB_HOST')
db_port = os.getenv('DB_PORT', '1521')
db_service = os.getenv('DB_SERVICE')
db_dsn = os.getenv('DB_DSN')
# Create connection
try:
if db_dsn:
# Use DSN if provided
connection = oracledb.connect(
user=db_user,
password=db_password,
dsn=db_dsn
)
elif all([db_user, db_password, db_host, db_service]):
# Build DSN from components
dsn = f"{db_host}:{db_port}/{db_service}"
connection = oracledb.connect(
user=db_user,
password=db_password,
dsn=dsn
)
else:
logger.error("Database connection not configured. Please create a .env file with your connection details.")
logger.error("See .env.template for the required variables.")
return
logger.info("Successfully connected to Oracle database")
except oracledb.Error as e:
logger.error(f"Failed to connect to database: {e}")
return
try:
# Path to your JSON file
json_file_path = "/Users/thatjeffsmith/Downloads/wp_comments.json"
# Load the data
load_wp_comments_data(json_file_path, connection)
except Exception as e:
logger.error(f"Error in main execution: {e}")
finally:
if connection:
connection.close()
logger.info("Database connection closed")
if __name__ == "__main__":
main()Running it had the following output.
(venv) bash-3.2$ /Users/thatjeffsmith/blog-stuff/.venv/bin/python load_wp_comments.py
2025-11-04 10:14:34,820 - INFO - Successfully connected to Oracle database
2025-11-04 10:14:34,820 - INFO - Loading JSON data from /Users/thatjeffsmith/Downloads/wp_comments.json
2025-11-04 10:14:35,311 - INFO - Found 22620 comments to process
2025-11-04 10:14:35,704 - INFO - Processed batch: 500 rows committed
2025-11-04 10:14:35,918 - INFO - Processed batch: 1000 rows committed
2025-11-04 10:14:36,026 - INFO - Processed batch: 1500 rows committed
2025-11-04 10:14:36,097 - INFO - Processed batch: 2000 rows committed
2025-11-04 10:14:36,202 - INFO - Processed batch: 2500 rows committed
2025-11-04 10:14:36,295 - INFO - Processed batch: 3000 rows committed
2025-11-04 10:14:36,476 - INFO - Processed batch: 3500 rows committed
2025-11-04 10:14:36,612 - INFO - Processed batch: 4000 rows committed
2025-11-04 10:14:36,732 - INFO - Processed batch: 4500 rows committed
2025-11-04 10:14:36,839 - INFO - Processed batch: 5000 rows committed
2025-11-04 10:14:36,905 - INFO - Processed batch: 5500 rows committed
2025-11-04 10:14:36,977 - INFO - Processed batch: 6000 rows committed
2025-11-04 10:14:37,053 - INFO - Processed batch: 6500 rows committed
2025-11-04 10:14:37,169 - INFO - Processed batch: 7000 rows committed
2025-11-04 10:14:37,273 - INFO - Processed batch: 7500 rows committed
2025-11-04 10:14:37,489 - INFO - Processed batch: 8000 rows committed
2025-11-04 10:14:37,595 - INFO - Processed batch: 8500 rows committed
2025-11-04 10:14:37,725 - INFO - Processed batch: 9000 rows committed
2025-11-04 10:14:37,831 - INFO - Processed batch: 9500 rows committed
2025-11-04 10:14:37,902 - INFO - Processed batch: 10000 rows committed
2025-11-04 10:14:37,965 - INFO - Processed batch: 10500 rows committed
2025-11-04 10:14:38,044 - INFO - Processed batch: 11000 rows committed
2025-11-04 10:14:38,165 - INFO - Processed batch: 11500 rows committed
2025-11-04 10:14:38,266 - INFO - Processed batch: 12000 rows committed
2025-11-04 10:14:38,380 - INFO - Processed batch: 12500 rows committed
2025-11-04 10:14:38,479 - INFO - Processed batch: 13000 rows committed
2025-11-04 10:14:38,587 - INFO - Processed batch: 13500 rows committed
2025-11-04 10:14:38,711 - INFO - Processed batch: 14000 rows committed
2025-11-04 10:14:38,781 - INFO - Processed batch: 14500 rows committed
2025-11-04 10:14:38,858 - INFO - Processed batch: 15000 rows committed
2025-11-04 10:14:38,952 - INFO - Processed batch: 15500 rows committed
2025-11-04 10:14:39,113 - INFO - Processed batch: 16000 rows committed
2025-11-04 10:14:39,329 - INFO - Processed batch: 16500 rows committed
2025-11-04 10:14:39,489 - INFO - Processed batch: 17000 rows committed
2025-11-04 10:14:39,734 - INFO - Processed batch: 17500 rows committed
2025-11-04 10:14:39,938 - INFO - Processed batch: 18000 rows committed
2025-11-04 10:14:40,076 - INFO - Processed batch: 18500 rows committed
2025-11-04 10:14:40,151 - INFO - Processed batch: 19000 rows committed
2025-11-04 10:14:40,325 - INFO - Processed batch: 19500 rows committed
2025-11-04 10:14:40,477 - INFO - Processed batch: 20000 rows committed
2025-11-04 10:14:40,597 - INFO - Processed batch: 20500 rows committed
2025-11-04 10:14:40,699 - INFO - Processed batch: 21000 rows committed
2025-11-04 10:14:40,790 - INFO - Processed batch: 21500 rows committed
2025-11-04 10:14:40,883 - INFO - Processed batch: 22000 rows committed
2025-11-04 10:14:40,981 - INFO - Processed batch: 22500 rows committed
2025-11-04 10:14:41,059 - INFO - Processed batch: 22620 rows committed
2025-11-04 10:14:41,059 - INFO - Data loading complete!
2025-11-04 10:14:41,059 - INFO - Total rows processed: 22620
2025-11-04 10:14:41,059 - INFO - Total errors: 0
2025-11-04 10:14:41,108 - INFO - Total rows in WP_COMMENTS table: 22620
2025-11-04 10:14:41,125 - INFO - Database connection closed
(venv) bash-3.2$ And I did something similar with my WP_CONTENT table, it’s a simple CSV export, but with just metadata, not the actual post content. I’ve shown this before:
- Loading CSV data via CLI commands
- Having your Agent do it for you via our MCP Server / run-sqlcl MCP tool
The real work begins: my web console, V1
I learned this trick from Kris. Vibe coding generally will have a lot of back and forth between you and your agent. When you’re done, ask it to tidy things up with a singular prompt that could be used to re-create your work.
connect to my raptor database, build a dashboard that gives an overview of my wordpress content, use the number of comments on a post to measure engagement/popularity
include a listing of the top 25 posts and include the total comments for each, add hover text to the title to include a post summary if available
start with a static html page, that looks very nice and modern, and gives an overview of my content over time, with popularity measured by the amount of feedback, via comments
Ensure responsive layout, create as ‘dashboard.html’. The theme should adopt a dark mode environment.
Here’s what V1 looks like –

Noet: This looks prettier than what I can generally do on my own. Any sort of ‘web development’ or ‘web mockups’ is where I’m going to lean harder on an AI to assist me.
All of this data is static, the LLM generated SQL, executed it via our MCP Server, and hard-coded the content into the HTML file. More on this, later.
Readying the ‘backend’ for the Vector Search
I’ve talked about this before:
- loading the hugging face model onnx file to your database
- vectorizing a column
- indexing it
- bumping up the vector memory space
- search away!
That code basically boiled down to this –
--download the onnx model zip, and extract to $ORACLE_HOME/onnx
create or replace directory vector_model_dir as '/opt/oracle/product/26ai/dbhomeFree/onnx';
grant db_developer_role, create mining model to hr;
grant read on directory vector_model_dir to hr;
grant write on directory vector_model_dir to hr;
alter system set vector_memory_size = 512M scope=spfile;
--bounce the db
update wp_comments
set
comment_vector = vector_embedding(all_minilm_l12_v2
using dbms_lob.substr(comment_content, 2000, 1) as data
)
where comment_content is not null;
-- wait :)
It took nearly an hour (on my 2018 hardware running a VM with 4GB of RAM) to vectorize those 22,000 comments – the first 2000 characters at least as some exceed 4k characters and are definitely multi-byte.
Here’s what that looked like in terms of a SQL Monitoring report in SQL Developer for VS Code:

To limit resources, I nuked all of the vectors older than 3 years, to save memory for the index, which I created here:
CREATE VECTOR INDEX blog_comments_hnsw_idx ON WP_COMMENTS (comment_vector) ORGANIZATION INMEMORY NEIGHBOR GRAPH
DISTANCE COSINE
WITH TARGET ACCURACY 80;Having this index loaded into memory, is what allows for FAST searches. You can skip this, or change up the type of index or the accuracy. Instead of 95%, I decided let’s try 80 instead and see if it mattered (it did not).
Building the backend (PL/SQL and REST APIs)
My prompt (I did not write this prompt, I vibe coded over a session of 12 or so back-and-forths, and the agent built this prompt for me) :
Context: I have an Oracle 26ai database (version 23.26.0.0.0) with a table called
WP_COMMENTSthat contains blog comments. The table has aCOMMENT_VECTORcolumn of type VECTOR with 384 dimensions, which stores vector embeddings of the comment content. The database has theALL_MINILM_L12_V2embedding model available for generating 384-dimensional vectors.Table Structure:
- Table Name:
WP_COMMENTS- Key Columns:
COMMENT_ID(NUMBER) – Primary keyCOMMENT_CONTENT(CLOB) – The actual comment textCOMMENT_VECTOR(VECTOR) – 384-dimensional vector embeddingCOMMENT_AUTHOR(VARCHAR2)COMMENT_DATE(DATE)COMMENT_POST_ID(NUMBER)Requirements: Create a PL/SQL stored procedure that:
- Takes a search string as input (VARCHAR2)
- Converts the input string to a vector embedding using the
VECTOR_EMBEDDINGfunction with theALL_MINILM_L12_V2model- Performs a similarity search against the
COMMENT_VECTORcolumn in theWP_COMMENTStable- Returns the top 10 most similar comments ordered by similarity (closest matches first)
- Uses Euclidean distance for the similarity calculation
- Returns results as a cursor with: comment_id, comment_author, comment_date, comment_preview (first 500 chars), comment_post_id, and similarity_distance
Expected Output:
- A stored procedure named
search_similar_commentswith parameters:
p_search_text IN VARCHAR2– the search queryp_results OUT SYS_REFCURSOR– the result set- Optionally, a wrapper function for easier testing
- The procedure should handle errors gracefully
Test Case: Test the procedure with the input:
'how do I build a rest api to work with user types'and verify it returns relevant comments about REST APIs, ORDS, and user management, ordered by vector similarity distance.Technical Notes:
The vector_memory_size parameter may be set to 0 (default), which means vector operations use regular SGA/PGA memory
The
VECTOR_EMBEDDINGfunction syntax in Oracle 23ai requires using a SELECT FROM DUAL statementUse
VECTOR_DISTANCEfunction with EUCLIDEAN distance metricUse
FETCH FIRST 10 ROWS ONLYfor limiting results
I have to say, the Agent that rhymes with Maude is MUCH better at reverse engineering a vibe coding session to a singular prompt you can reuse. Anyway, here’s the code it gave me.
I was bit a literal, I asked for a stored procedure, but a singular function would have sufficed.
The main procedure:
CREATE OR REPLACE PROCEDURE /* LLM in use is claude-opus-4.1 */ search_similar_comments (
p_search_text IN VARCHAR2,
p_results OUT SYS_REFCURSOR
) AS
v_search_vector VECTOR;
BEGIN
-- Generate vector embedding for the input text using all-MiniLM-L12-v2 model
-- Correct syntax for VECTOR_EMBEDDING function
SELECT VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING p_search_text AS data)
INTO v_search_vector
FROM DUAL;
-- Open cursor with similarity search results
-- Using VECTOR_DISTANCE with L2 (Euclidean) distance and ordering by closest matches
OPEN p_results FOR
SELECT
comment_id,
comment_author,
comment_date,
SUBSTR(comment_content, 1, 500) AS comment_preview,
comment_post_id,
VECTOR_DISTANCE(comment_vector, v_search_vector, EUCLIDEAN) AS similarity_distance
FROM WP_COMMENTS
WHERE comment_vector IS NOT NULL
ORDER BY VECTOR_DISTANCE(comment_vector, v_search_vector, EUCLIDEAN)
FETCH FIRST 10 ROWS ONLY;
EXCEPTION
WHEN OTHERS THEN
-- Log error and re-raise
DBMS_OUTPUT.PUT_LINE('Error in search_similar_comments: ' || SQLERRM);
RAISE;
END search_similar_comments;
/It chose to create a wrapper function that would make testing, easier:
CREATE OR REPLACE FUNCTION /* LLM in use is claude-opus-4.1 */ get_similar_comments_table (
p_search_text IN VARCHAR2
) RETURN SYS_REFCURSOR AS
v_cursor SYS_REFCURSOR;
BEGIN
search_similar_comments(p_search_text, v_cursor);
RETURN v_cursor;
END get_similar_comments_table;
/Those compiled, and I tested the function, myself.

Cool, it’s ready for my REST API, which I coded myself. Faster at the moment than training the LLM exactly how ORDS works. I expect that to change shortly as the newer LLMs end up consuming more and more content around ORDS.
-- Generated by ORDS REST Data Services 25.3.0.r2671248
-- Schema: HR Date: Wed Nov 05 01:36:04 2025
--
DECLARE
l_roles OWA.VC_ARR;
l_modules OWA.VC_ARR;
l_patterns OWA.VC_ARR;
BEGIN
ORDS.ENABLE_SCHEMA(
p_enabled => TRUE,
p_url_mapping_type => 'BASE_PATH',
p_url_mapping_pattern => 'hr',
p_auto_rest_auth => FALSE);
ORDS.DEFINE_MODULE(
p_module_name => 'comments',
p_base_path => '/comments/',
p_items_per_page => 25,
p_status => 'PUBLISHED',
p_comments => NULL);
-- this is a hack to allow my html page to call ords on my localhost:8080 instance running on the same machine, do not do this in the real world
ORDS.SET_MODULE_ORIGINS_ALLOWED(
p_module_name => 'comments',
p_origins_allowed => 'null');
ORDS.DEFINE_TEMPLATE(
p_module_name => 'comments',
p_pattern => 'search/:string',
p_priority => 0,
p_etag_type => 'HASH',
p_etag_query => NULL,
p_comments => NULL);
ORDS.DEFINE_HANDLER(
p_module_name => 'comments',
p_pattern => 'search/:string',
p_method => 'GET',
p_source_type => 'json/collection',
p_items_per_page => 25,
p_mimes_allowed => NULL,
p_comments => NULL,
p_source =>
'select GET_SIMILAR_COMMENTS_TABLE(:string)');
COMMIT;
END;Evolving v1 of my webpage to v2
I want to add a search component. Here’s my prompt:
copy to dashboard.html to dashboard-v2.html and update it:
add search panel above stats with input/button for ORDS API http://localhost:8080/ords/hr/comments/search/{term};
on search, fetch/parse
data.items[0][‘get_similar_comments_table(:1)’],
display results in collapsible
And here’s the resulting page –
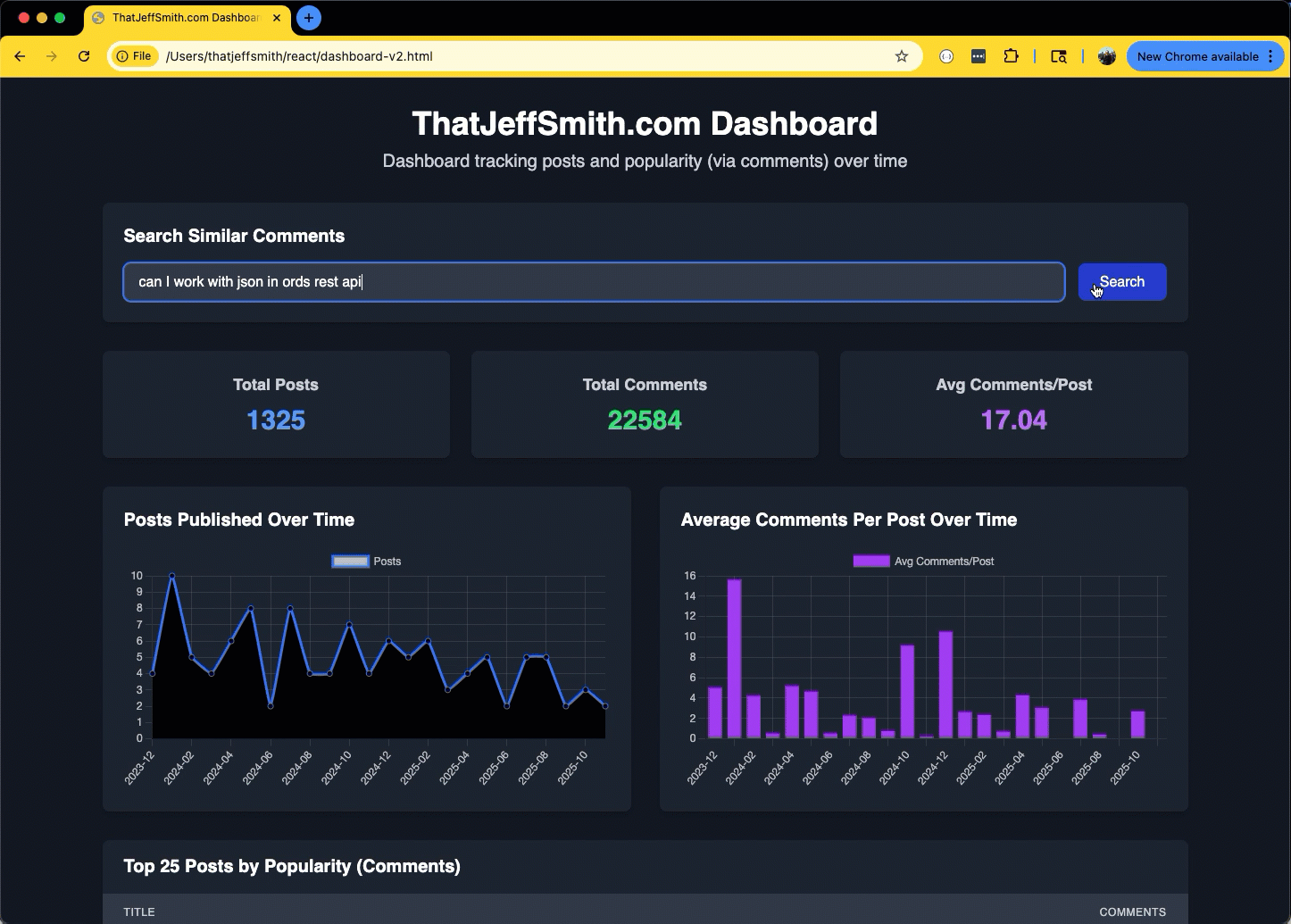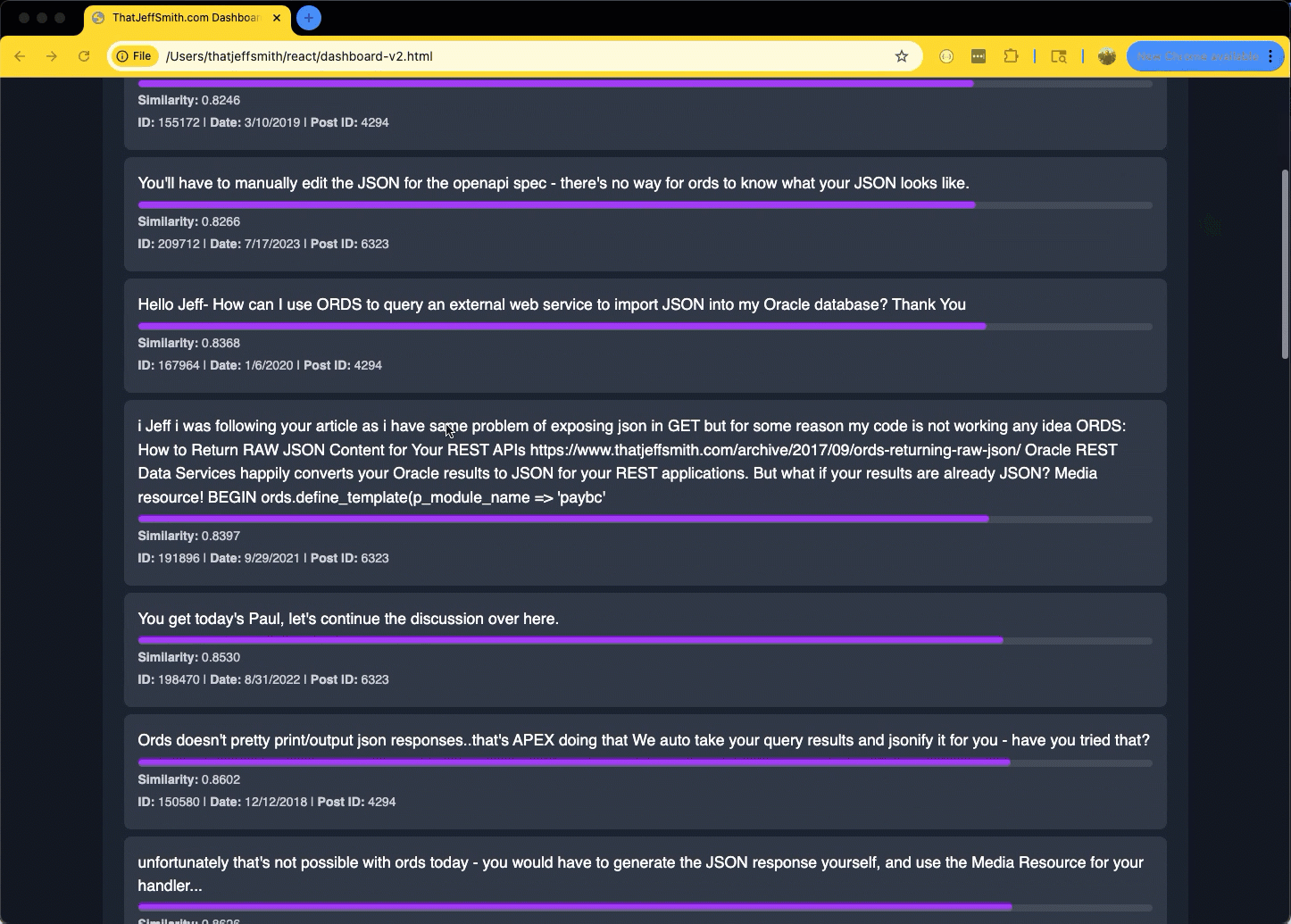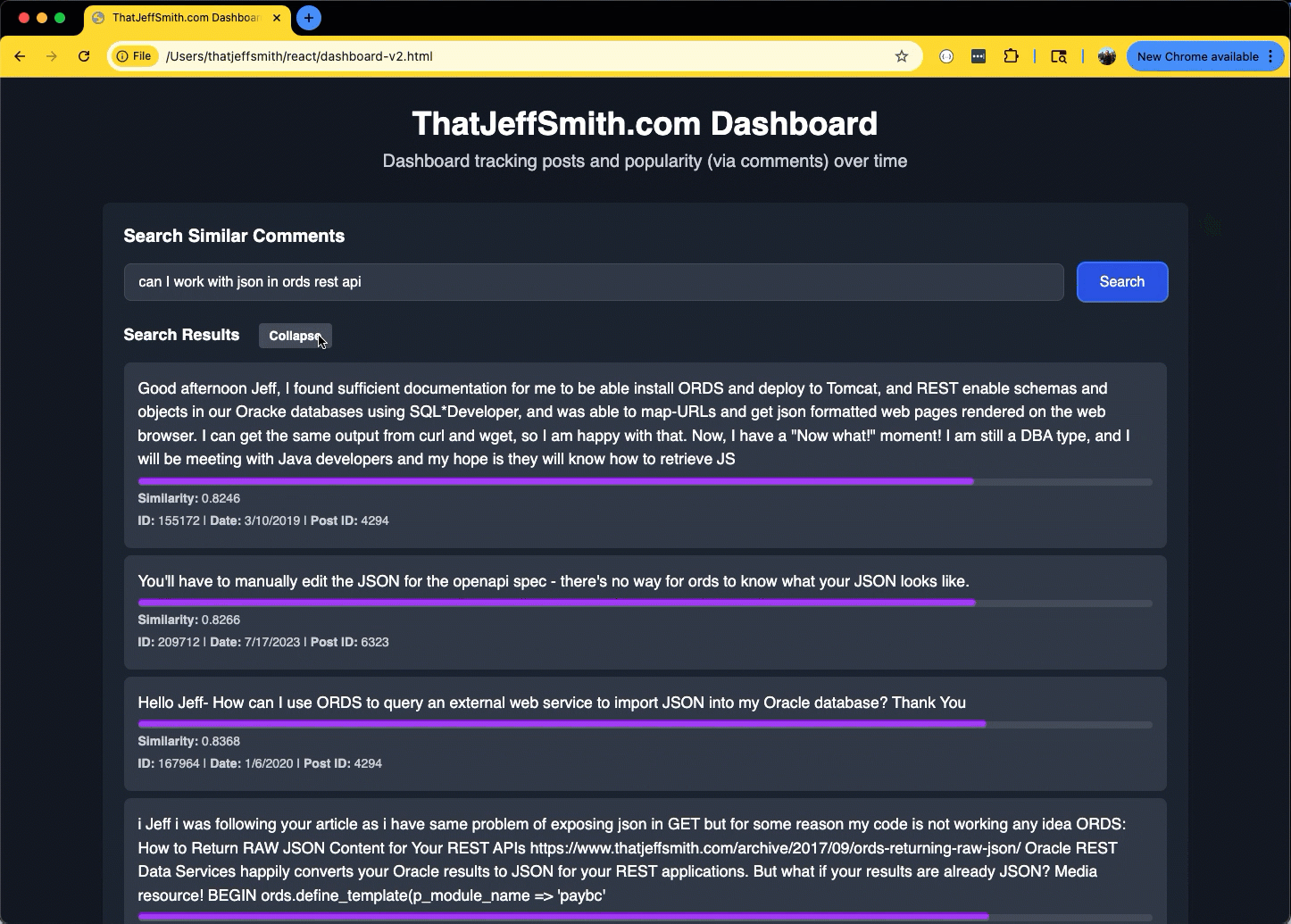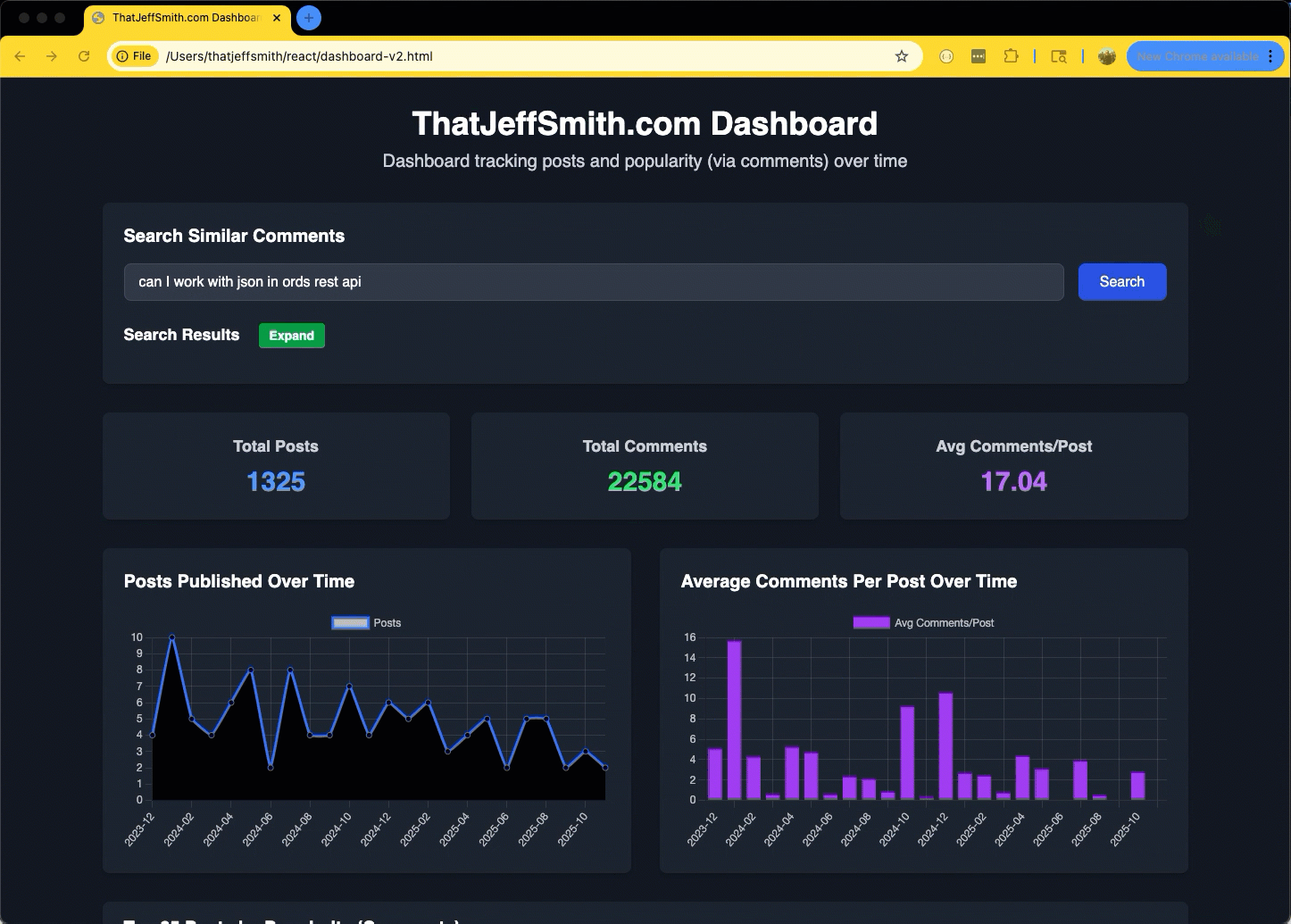
I have 26,000 comments on my blog. Finding the exact post I’m looking for (I have almost 1500 of those, too!) is hard, and I have a really bad memory. And sometimes the data I’m looking for is shared in the comments, vs the actual post! At least half the comments are my replies with answers to people’s questions…
This is going to be very helpful for me! I’ll eventually change up my app to include links in the search results that direct link to the POST and to the COMMENT.
But being able to search on a theme or idea or INTENT, vs doing literal matches or wildcard based searching will be a game changer for me.
This is cool and all, but I’d rather have a real, serious web app
You can easily use your agent and prompt engineer yourself a really nice React protoype app backed with real data, real queries, and real APIs. My colleagues are building some really nice demos, I’ve only scratched at the surface.
My next steps here would be to make this real-time vs hard coded page. That just means building a few more REST APIs having those used via some js fetch calls!
Takeaways
My MCP Server made it super easy for my agents and LLMs to poke around in my database, find the data structures, programs, and data they needed to build my report.
I spent a total of about an hour to do this. I could have gone quicker, but I changed my mind what I wanted it to be, and got distracted.
There were a total of 33 interactions between my agents and my Oracle Database using our MCP Server, logged as such:





