

Updated February 2021
Signing up for an Autonomous Database is easy. You can have an instance up and running in just a few minutes. And now, you can even have one for FREE.
But one of the first things you’re going to want to do is shove some TABLEs into your schema, or just load some data.
We’re working on making this even easier, but let’s quickly recap what you can already do with our tools.
A Saucerful of “Secrets” Ways to Load Data to the Cloud with our DB Tools
- Data Pump to Cloud
- Cart to Cloud
- Database Copy to the Cloud
- Drag and Drop to Cloud
- SQL Developer Web, CSV, Excel Imports
Taking Advantage of AUTO TABLE and ORDS
If you already have a TABLE in your schema, and you want to create a REST API for accessing said table, we make that easy.
It’s a right-click in SQL Developer Web, or Desktop
In the SQL card in Database Actions (formerly known as SQL Developer Web –
Or you could of course just run this very simple PL/SQL block –
BEGIN ORDS.ENABLE_OBJECT(p_enabled => TRUE, p_schema => 'JEFF', -- your schema here (has to be YOUR schema) p_object => 'HOCKEY_STATS', -- your table here p_object_type => 'TABLE', -- or view or plsql p_object_alias => 'hockey_stats', -- how the object will be named in the URI p_auto_rest_auth => TRUE); -- PROTECT! COMMIT; END;
Another quick aside, if you need to catch up on these topics, I’ve talked about creating your application SCHEMA and REST Enabling it for SQL Developer Web access.
And, I’ve talked about using the CSV Load feature available with the ORDS AUTO Table mechanism.
My TABLE
I have a HOCKEY_STATS table, that I want to load from some CSV data I have on my PC. It’s an 8MB file (35000 rows, 70 columns).
Now, I could use the Import from CSV feature in SQL Developer (Desktop) to populate the TABLE…
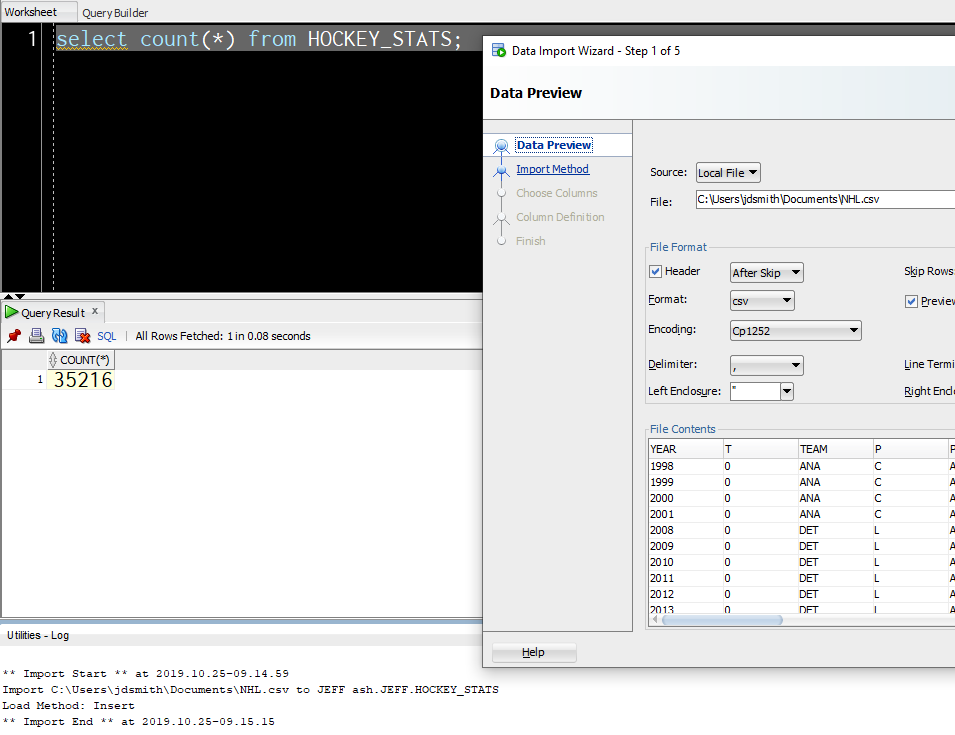
That’s not super quick, but it was super easy.
And yes, you can do all of this in your browser as well!
But what if I need a process that can be automated? And my API du jour is HTTPS and REST?
Let’s POST up my CSV to the TABLE API
Let’s find the URI first. Go into your REST workshop page in Database Actions
From there we’ll see what we have available for RESTFul Web Services in our schema.
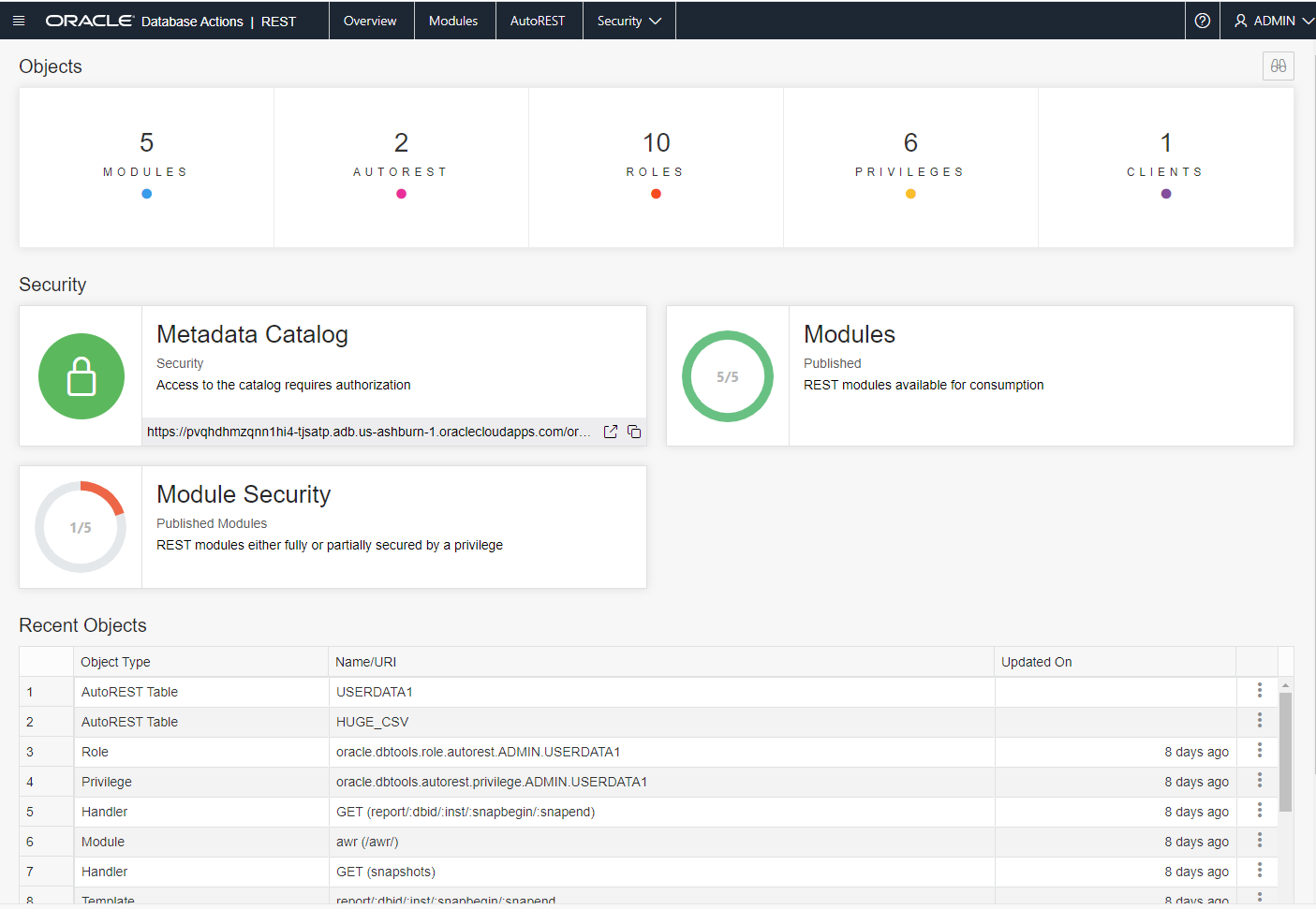
AUTOREST
I can immediately see the tables and views I want to work with, and I can filter those, but I only have two at the moment. If I click on the button in the corner of the card, I can ask for the cURL information for all of the CRUD REST API endpoints – including BATCH LOAD.
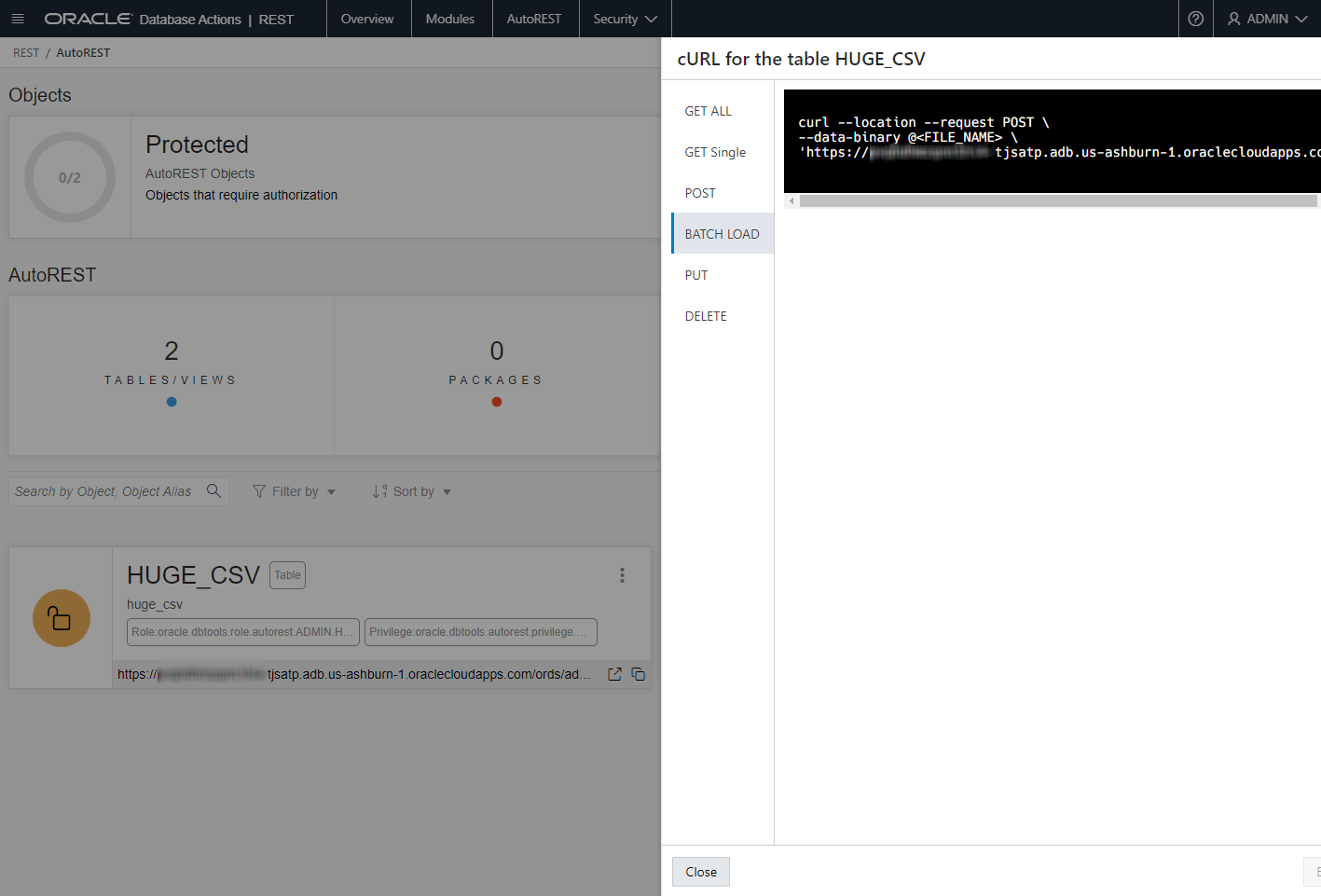
I’m going to take this string and fix it up a bit…
https://ABCDEFGHIJK0l-somethingash.adb.us-ashburn-1.oraclecloudapps.com/ords/tjs/hockey_stats/batchload?batchRows=1000
The ‘/batchload?batchRows=1000’ at the end tells ORDS what we’re doing with the TABLE, and how to do it. This is documented here – and you’ll see there’s quite a few options you can tweak.
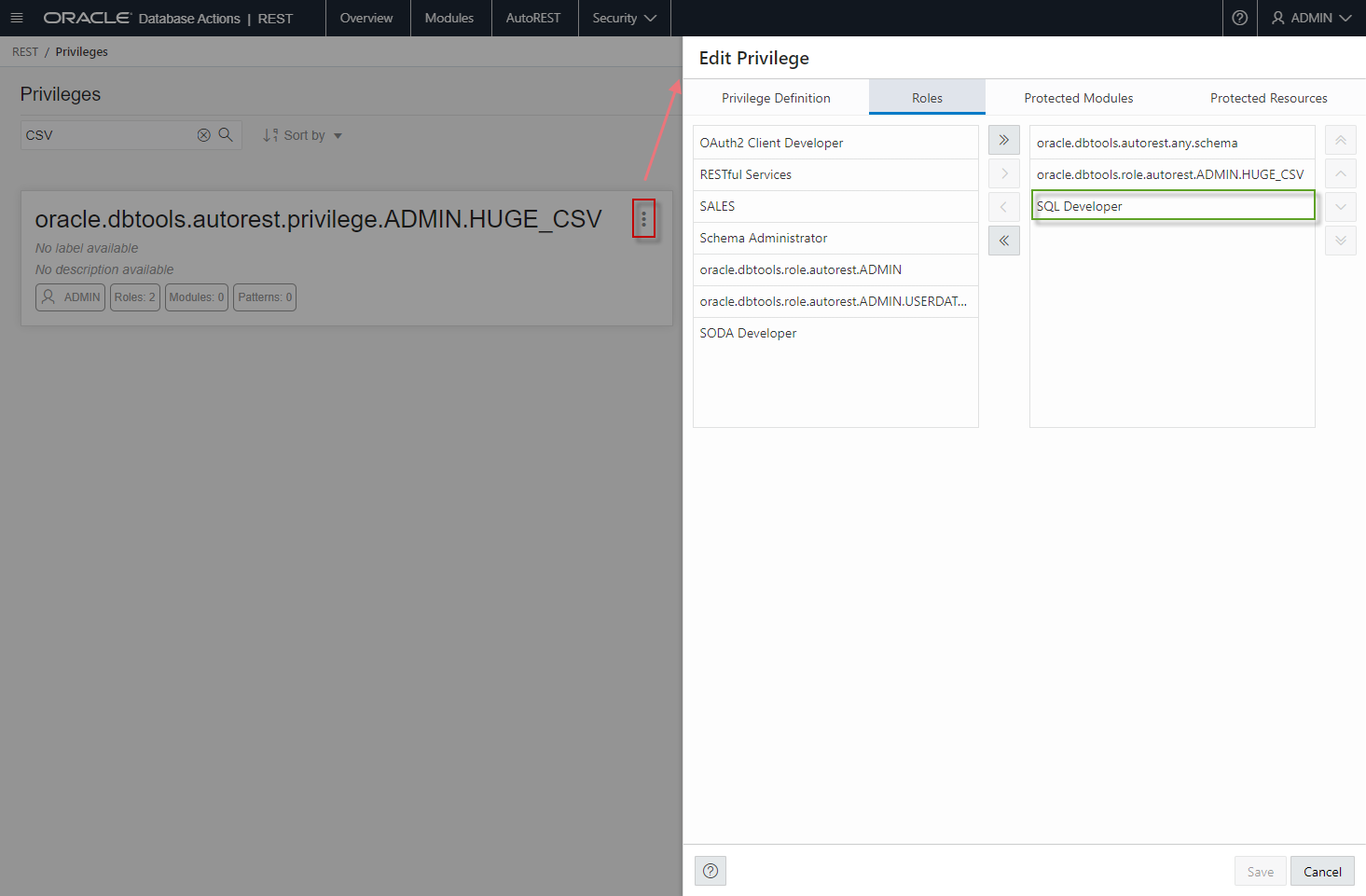
If you want to protect these endpoints (and you almost always will), you’ll need to assign the table privilege to the ‘SQL Developer’ role – then you can use your database username/password with the cURL command.
That’s done on the Security page for the REST workshop.
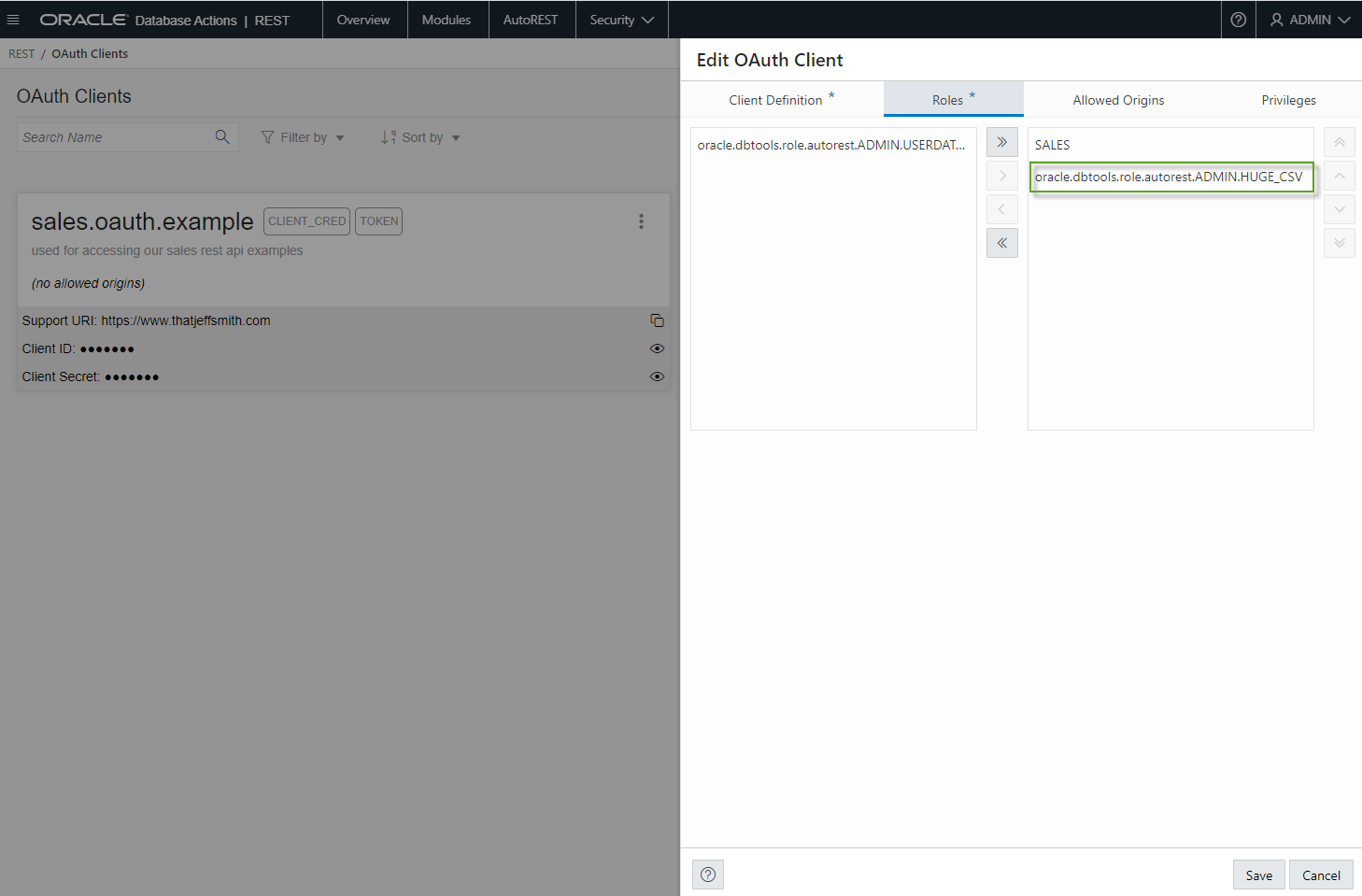
If using database credentials in your REST calls sounds ‘icky’ then you can also take advantage or our built-in OAUTH2 Client (example).
There’s also a full OAUTH2 UI in the REST Workshop as well –
Now, let’s make our call. I’m going to use a REST Client (Insomnia) but I could easily just use cURL.
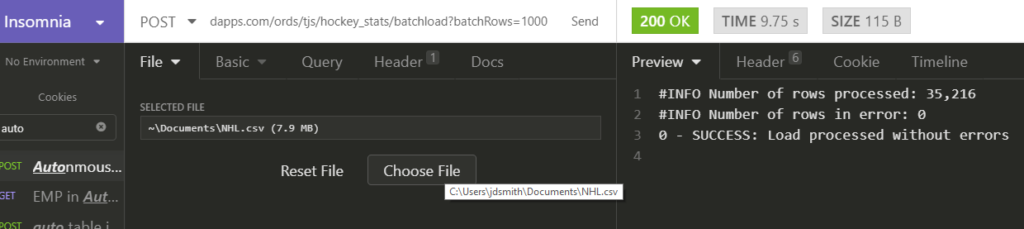
I could tweak the batchRows parameter, and see if I could get faster loads, I’m sure I could. But the whims of public internet latency and the nature of the data I’m sending up in 16 KB chunks will make this a fun ‘it depends’ tech scenario.
30 September 2020 Update – 5M Rows, ~27 sec!
I decided to throw a slightly larger scenario at ORDS in Autonomous.
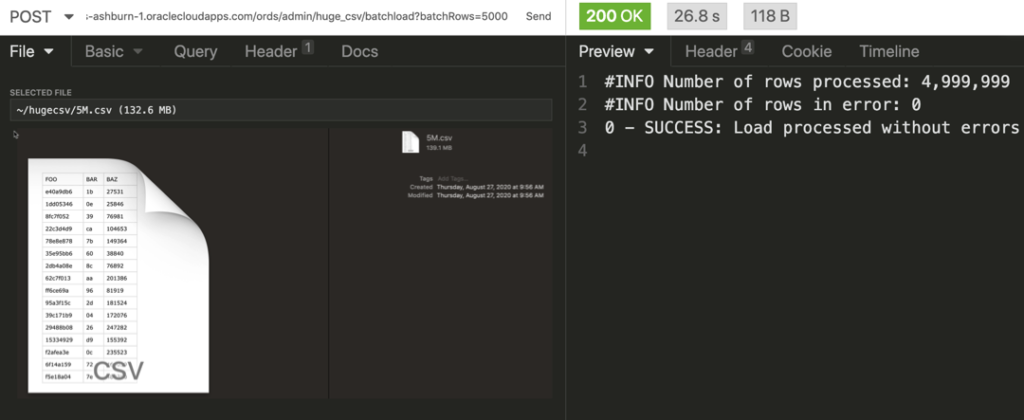
And our data…
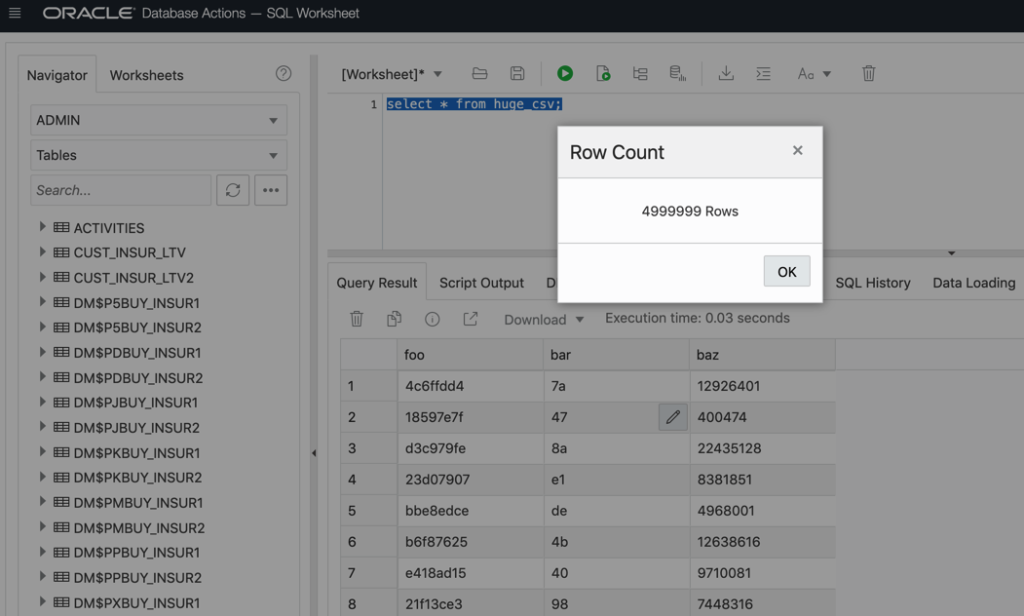
Note this scenario was also from Cary, NC to our Cloud Data Center in Virginia…and of course your results may vary based on current network loads.
I also increased the batchRows setting up to 5,000 from 1,000. I also tried 7,500 and 10,000 but didn’t see any additional performance improvements, but this also is NOT a scientific test.
Some more notes on settings (Docs).
batchRows – The number of rows to include in each bath – so we’re inserting/committing 5,000 rows at a time, for a total of 100 batches.
We could include additional settings…
errors and errorsMax in particular. You may want to set errorsMax to a reasonable number. In other words, do you want to give up on the load if say, more than 10% fail to be inserted. For debugging, I would suggest setting it to 1 or say 10 so your test ‘fails fast’ and doesn’t consume unnecessary server resources.
And of course, results may vary, but I got this to run as ‘fast’ as 25 seconds and as slow as 29 seconds.
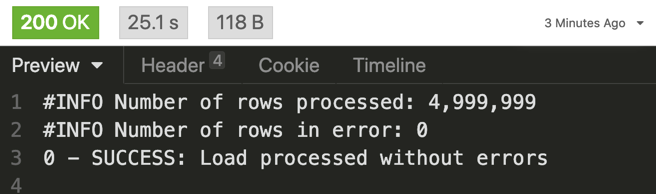
I ran this scenario 10x each, and also for 10M, and 20M rows of this same data. I found that running the loads at 5M row batches outperformed the larger ones. That is, I could kick off 2, 5M load requests and get it done MUCH faster than a single 10M load.
For example, running 10M rows, 10 times, my average load time was 90 seconds, vs 30 seconds for the 5M loads.
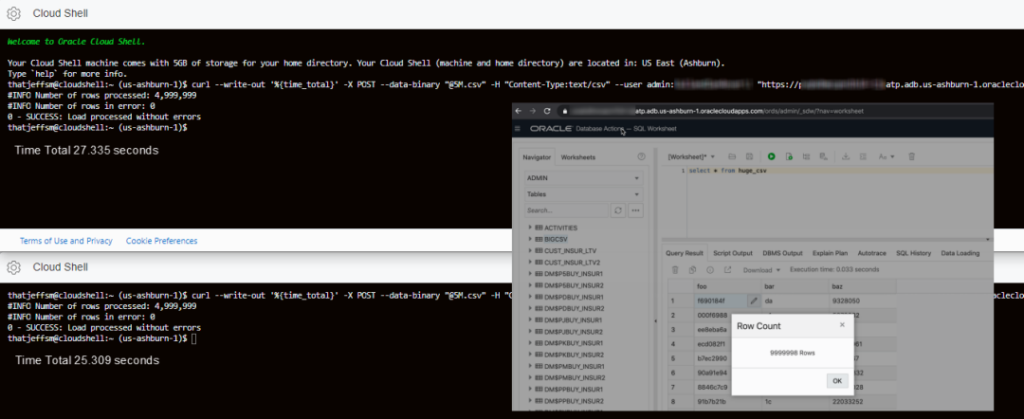
When I kicked off 2 5M runs concurrently, both were finished in less than 27.4 seconds!
The cURL
I hate cURL. It took me more than a few minutes, and ended up having to Zoom with @krisrice to finally get this JUST right…
curl --write-out '%{time_total}' -X POST --data-binary "@5M.csv" -H "Content-Type:text/csv" --user <user>:<password> "https://....adb.us-ashburn-1.oraclecloudapps.com/ords/<user>/huge_csv/batchload?batchRows=5000&errorsMax=20"
Don’t forget the Content-Type header! I was doing that and weird things were happening. Also had to hop to SO to figure out how to stream in the contents of the file, and then also learned a cool trick of pulling the HTTP response time in the call. I’m sharing this for ME, because I’ll forget it tomorrow.





2 Comments
Brilliant post as always Jeff , is there a way to load a CSV file automatically that is stored on a diff server ??
I’ve looked at buckets , data intergrator , ODI etc but i’m stuck !!
You could curl/get the file local and then post it as I show, for from the database itself you could use DBMS_CLOUD and read/stream it directly from the OCI Object Store, any any S3 bucket (I think)