Did you know that:
- you can implement more of your data model directly in the database?
- you can easily share this info with your applications?
- it’s not just for tables and views, but also duality views?
Well, you should have a hint now that we’ve put a good amount of work to make this possible today in our 23ai Database.
Disclosure: I am using 23ai FREE edition, version 23.5 to demonstrate.
Teach yourself with a ‘Hands On’ approach
One of our database product managers, Killian!, put a huge amount of time building this comprehensive Oracle 23ai Database tutorial.
I’m not going to talk much about VECTORs in this post, but Killian does cover that in his tutorial. These tutorials can easily be followed along in a database you borrow from us in the LiveLabs environment, or you can run it yourself, which I’ve been doing in our 23ai VirtualBox appliance using our SQL Developer Extension for VS Code.
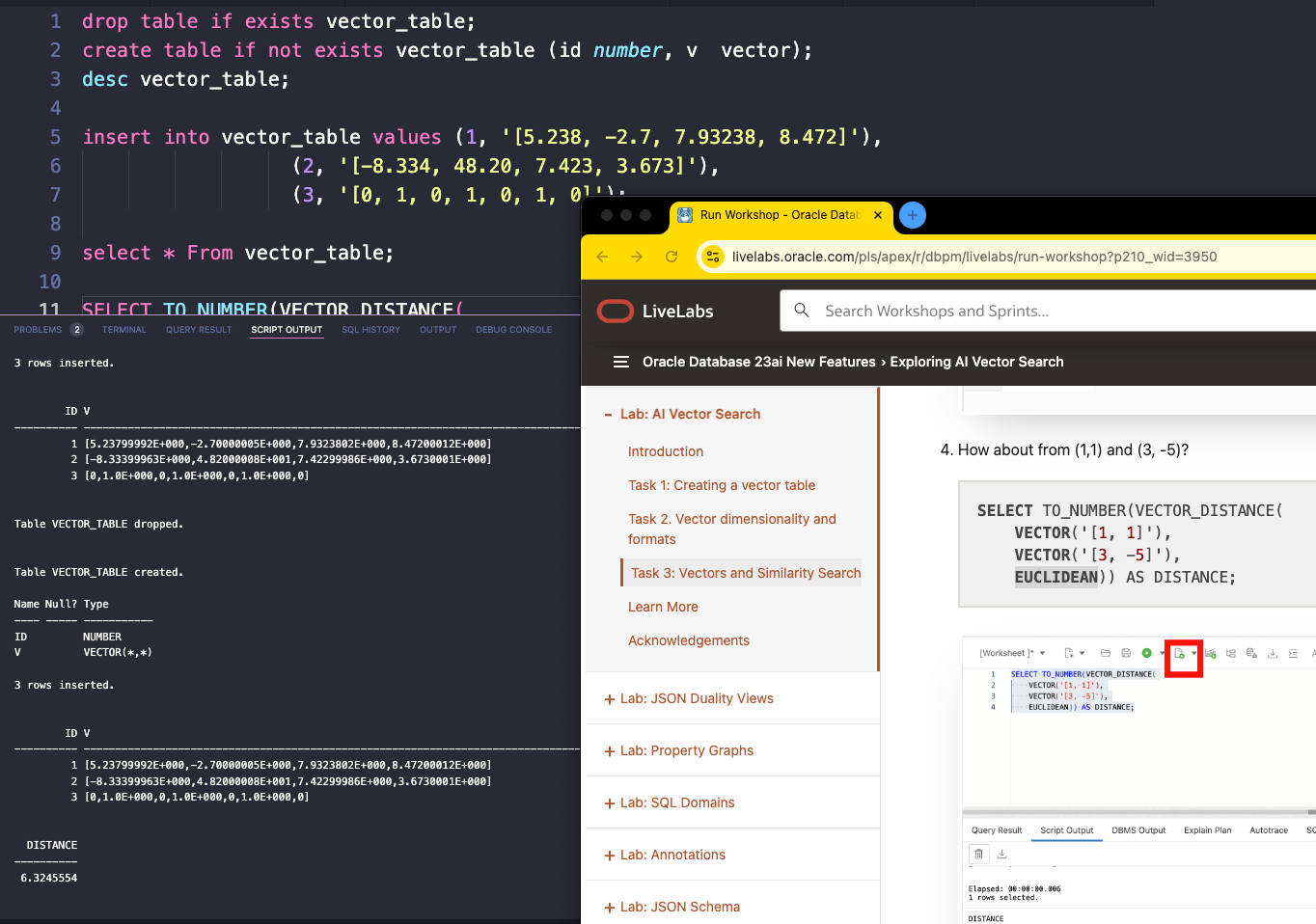
Ok, back to the ‘living, breathing data model’
Traditionally you would sit down and put together your data model on paper, or maybe using something like Erwin ($$$$$) or SQL Developer Data Modeler (Free!)
And in that model, you might have taken advantage of the DOMAINs feature.
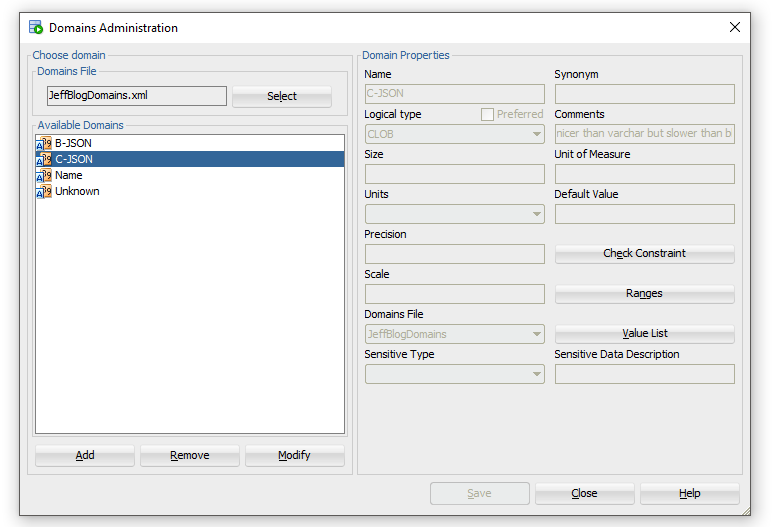
Think of a common attribute or column you have in your data model, say…a CREDIT CARD or an EMAIL ADDRESS.
Now, think of all the different ways you could implement these fields. Maybe a custom type, maybe a VARCHAR2 with a check constraint, maybe…
The beauty of the DOMAIN is that it allows us to define the type of data ONCE, with all its business rules, in a single object. But now instead of being defined in a data model, it can go straight into the database!
Let’s look at a quick example for emails.
create domain emails as varchar2(100)
constraint email_chk check (regexp_like (emails, '^(\S+)\@(\S+)\.(\S+)$'))
display lower(emails)
order lower(emails)
annotations (Description 'An email address with a check constraint for name @ domain dot (.) something');Now, when I go to create a new table, and I know I want to store an email address, I can simply use ‘EMAILS’ for the data type.
create table person (
id integer,
names varchar2(100),
personal_email emails
);‘EMAILS’ isn’t a data type, but it IS a defined DOMAIN that maps to a VARCHAR2, with the check constraint attached.
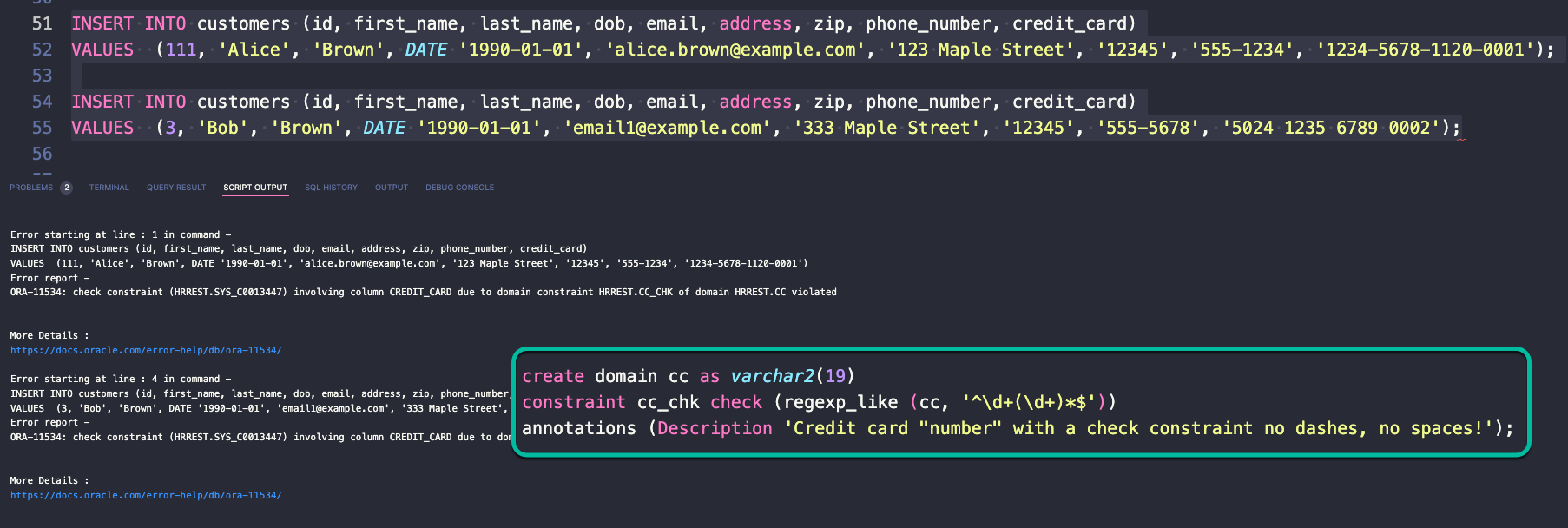
Here’s a similar look at a domain with credit cards, and trying to insert data that violates the domain check constraint.
Even more metadata
Another way to communicate information from our model is the ANNOTATIONS feature.
The easiest way to describe these is an an extension to object or column comments, but that’s not quite doing it justice. So let’s look at what the Database Docs have to say –
Annotations are a lightweight declarative facility for developers to centrally register usage properties for database schema objects. Annotations are stored in dictionary tables and are available to any application looking to standardize behavior across common data in related applications. Annotations are not interpreted by the database in any way. They are custom data properties for database metadata – included for table columns, tables, and indexes, that applications can use as additional property metadata to render user interfaces or customize application logic.
https://docs.oracle.com/en/database/oracle/oracle-database/23/adfns/registering-application-data-usage-database.html#GUID-DF156923-19A2-4B8C-8134-8CBC3039F72D
Our tools are applications
To give better support, to make things easier, etc. imagine if we (the database tools team) used Annotations to mark objects or tables as something of interest for our REST APIs? We could setup ORDS then to see these in a schema and set them up with AUTOREST APIs.
Your applications could do similar things with your objects based on how interesting or creative you got with your annotations.
* Note, we’re kicking around this specific idea, but nothing has been put in stone, yet.
An annotation could also communicate to someone building a front-end that the data they’re about to encounter has sensitive or PII data, so act accordingly!
Tip: looking for a better, more human explanation of annotations? Check out Oracle ACE Director Oracle-Base’s annotations article with a full example.
Duality Views are built on top of tables which can be defined and augmented with Domains & Annotations
Putting these topics together, we can now build even more powerful applications against our JSON objects via JSON Relational Duality Views –
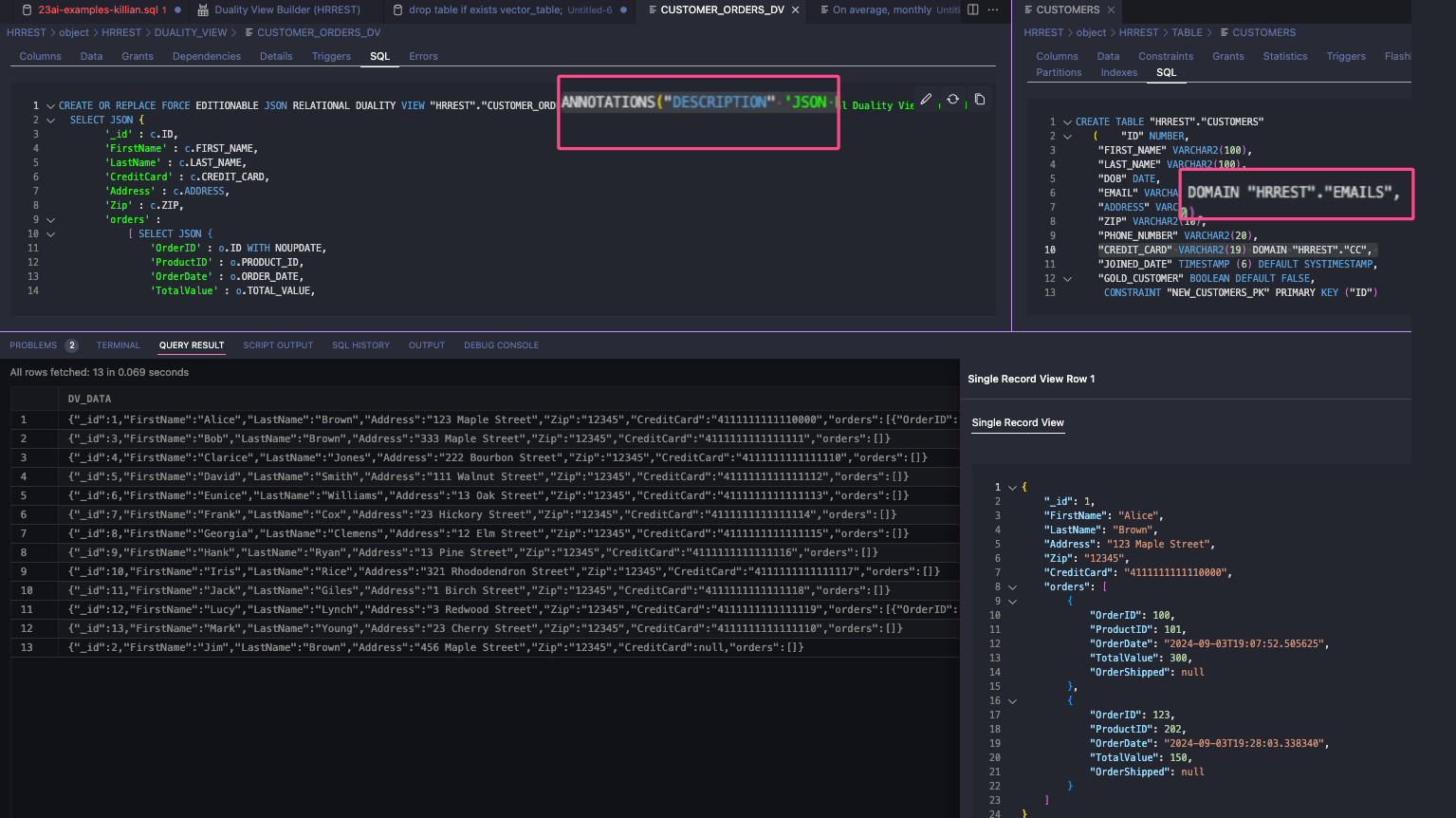
Annotating the Duality View
The ANNOTATION goes at the beginning of the DUALITY VIEW definition, unlike a TABLE where you’ll see it at the end.
GraphQL version:
CREATE OR REPLACE JSON RELATIONAL DUALITY VIEW customer_orders_dv
annotations (Description 'JSON Relational Duality View sourced from CUSTOMERS and ORDERS')
AS
customers
{
_id : id,
FirstName : first_name,
LastName : last_name,
Address : address,
Zip : zip,
orders : orders @insert @update @delete
...SQL/DDL version
CREATE OR REPLACE JSON RELATIONAL DUALITY VIEW CUSTOMER_ORDERS_DV
annotations (Description 'JSON Relational Duality View sourced from CUSTOMERS and ORDERS')
AS SELECT JSON {
'_id' : c.ID,
'FirstName' : c.FIRST_NAME,
'LastName' : c.LAST_NAME,
'CreditCard' : c.CREDIT_CARD,
...Note you may see in the Duality View docs that the ‘@insert @update @delete’ directives are also referred to as ‘annotations’, however that’s a completely different concept. It’s more accurate to think of them as ‘tags.’
While the Duality View doesn’t reference a domain directly, it CAN bring in a relational column from a table, which has been defined using a domain – in this case, the ‘CreditCard’ attribute.
The Code
Let’s have some fun! See how many new 23ai features are utilized in the following script. I got up to about 9, and then I started losing count as I don’t have enough fingers to keep going.
I probably don’t need to empty the recycle bin as I normally use the ‘PURGE’ keyword on my DROP TABLE commands, however if you’ve created any tables using said domains, and they’re still around, you won’t be able to drop of those DOMAINs.
In a production instance, the RECYCLE BIN can keep you from disaster, so use the PURGE commands with the care and caution that our data requires.
PURGE RECYCLEBIN;
drop domain if exists emails;
drop domain if exists cc;
create domain emails as varchar2(100)
constraint email_chk check (regexp_like (emails, '^(\S+)\@(\S+)\.(\S+)$'))
display lower(emails)
order lower(emails)
annotations (Description 'An email address with a check constraint for name @ domain dot (.) something');
create domain cc as varchar2(19)
constraint cc_chk check (regexp_like (cc, '^\d+(\d+)*$'))
annotations (Description 'Credit card "number" with a check constraint no dashes, no spaces!');
DROP TABLE if exists orders CASCADE CONSTRAINTS purge;
DROP TABLE if exists customers CASCADE CONSTRAINTS purge;
-- Create a table to store order data
CREATE TABLE if not exists orders (
id NUMBER,
product_id NUMBER,
order_date TIMESTAMP,
customer_id NUMBER,
total_value NUMBER(6,2),
order_shipped BOOLEAN,
warranty INTERVAL YEAR TO MONTH
);
-- Create a table to store customer data
CREATE TABLE if not exists customers (
id NUMBER,
first_name VARCHAR2(100),
last_name VARCHAR2(100),
dob DATE,
email emails,
address VARCHAR2(200),
zip VARCHAR2(10),
phone_number VARCHAR2(20),
credit_card cc,
joined_date TIMESTAMP DEFAULT SYSTIMESTAMP,
gold_customer BOOLEAN DEFAULT FALSE,
CONSTRAINT new_customers_pk PRIMARY KEY (id)
);
-- Add foreign key constraint to new_orders table
ALTER TABLE orders ADD (CONSTRAINT orders_pk PRIMARY KEY (id));
ALTER TABLE orders ADD (CONSTRAINT orders_fk FOREIGN KEY (customer_id) REFERENCES customers (id));
INSERT INTO customers (id, first_name, last_name, dob, email, address, zip, phone_number, credit_card)
VALUES (1, 'Alice', 'Brown', DATE '1990-01-01', '[email protected]', '123 Maple Street', '12345', '555-1234', '4111111111110000'),
(3, 'Bob', 'Brown', DATE '1990-01-01', '[email protected]', '333 Maple Street', '12345', '555-5678', '4111111111111111'),
(4, 'Clarice', 'Jones', DATE '1990-01-01', '[email protected]', '222 Bourbon Street', '12345', '555-7856', '4111111111111110'),
(5, 'David', 'Smith', DATE '1990-01-01', '[email protected]', '111 Walnut Street', '12345', '555-3221', '4111111111111112'),
(6, 'Eunice', 'Williams', DATE '1990-01-01', '[email protected]', '13 Oak Street', '12345', '555-4321', '4111111111111113'),
(7, 'Frank', 'Cox', DATE '1990-01-01', '[email protected]', '23 Hickory Street', '12345', '555-9876', '4111111111111114'),
(8, 'Georgia', 'Clemens', DATE '1990-01-01', '[email protected]', '12 Elm Street', '12345', '555-1111', '4111111111111115'),
(9, 'Hank', 'Ryan', DATE '1990-01-01', '[email protected]', '13 Pine Street', '12345', '555-2222', '4111111111111116'),
(10, 'Iris', 'Rice', DATE '1990-01-01', '[email protected]', '321 Rhododendron Street', '12345', '555-3333', '4111111111111117'),
(11, 'Jack', 'Giles', DATE '1990-01-01', '[email protected]', '1 Birch Street', '12345', '555-4444', '4111111111111118'),
(12, 'Lucy', 'Lynch', DATE '1990-01-01', '[email protected]', '3 Redwood Street', '12345', '555-5555', '4111111111111119'),
(13, 'Mark', 'Young', DATE '1990-01-01', '[email protected]', '23 Cherry Street', '12345', '555-6665', '4111111111111110')
;
INSERT INTO orders (id, customer_id, product_id, order_date, total_value, order_shipped, warranty)
VALUES
(100, 1, 101, SYSTIMESTAMP, 300.00, null, null),
(101, 12, 101, SYSTIMESTAMP-30, 129.99, true, interval '5' year)
;
CREATE OR REPLACE FORCE JSON RELATIONAL DUALITY VIEW CUSTOMERS_DV AS
customers @insert @update @delete
{
_id : id,
FirstName : first_name,
LastName : last_name,
DateOfBirth : dob,
Email : email,
Address : address,
Zip : zip
phoneNumber : phone_number
creditCard : credit_card
joinedDate : joined_date
goldStatus : gold_customer
};
INSERT INTO customers_DV values ('{"_id": 2, "FirstName": "Jim", "LastName":"Brown", "Email": "[email protected]", "Address": "456 Maple Street", "Zip": 12345}');
commit;
-- alternative GraphQL syntax
--CREATE OR REPLACE JSON RELATIONAL DUALITY VIEW customer_orders_dv
-- annotations (Description 'JSON Relational Duality View sourced from --CUSTOMERS and ORDERS')
-- AS
-- customers
-- {
-- _id : id,
-- FirstName : first_name,
-- LastName : last_name,
-- Address : address,
-- Zip : zip,
-- orders : orders @insert @update @delete
-- [
-- {
-- OrderID : id,
-- ProductID : product_id,
-- OrderDate : order_date,
-- TotalValue : total_value,
-- OrderShipped : order_shipped
-- }
-- ]
-- };
-- traditional DDL / SQL
CREATE OR REPLACE JSON RELATIONAL DUALITY VIEW CUSTOMER_ORDERS_DV
annotations (Description 'JSON Relational Duality View sourced from CUSTOMERS and ORDERS')
AS SELECT JSON {
'_id' : c.ID,
'FirstName' : c.FIRST_NAME,
'LastName' : c.LAST_NAME,
'Address' : c.ADDRESS,
'Zip' : c.ZIP,
'orders' :
[ SELECT JSON {
'OrderID' : o.ID WITH NOUPDATE,
'ProductID' : o.PRODUCT_ID,
'OrderDate' : o.ORDER_DATE,
'TotalValue' : o.TOTAL_VALUE,
'OrderShipped' : o.ORDER_SHIPPED
}
FROM ORDERS o
WITH INSERT UPDATE DELETE
WHERE o.CUSTOMER_ID = c.ID
]
}
FROM CUSTOMERS c;
UPDATE customer_orders_dv c
SET c.data = json_transform(
data,
APPEND '$.orders' = JSON {'OrderID':123, 'ProductID' : 202, 'OrderDate' : SYSTIMESTAMP, 'TotalValue' : 150.00}
)
WHERE c.data."_id" =1;
commit;
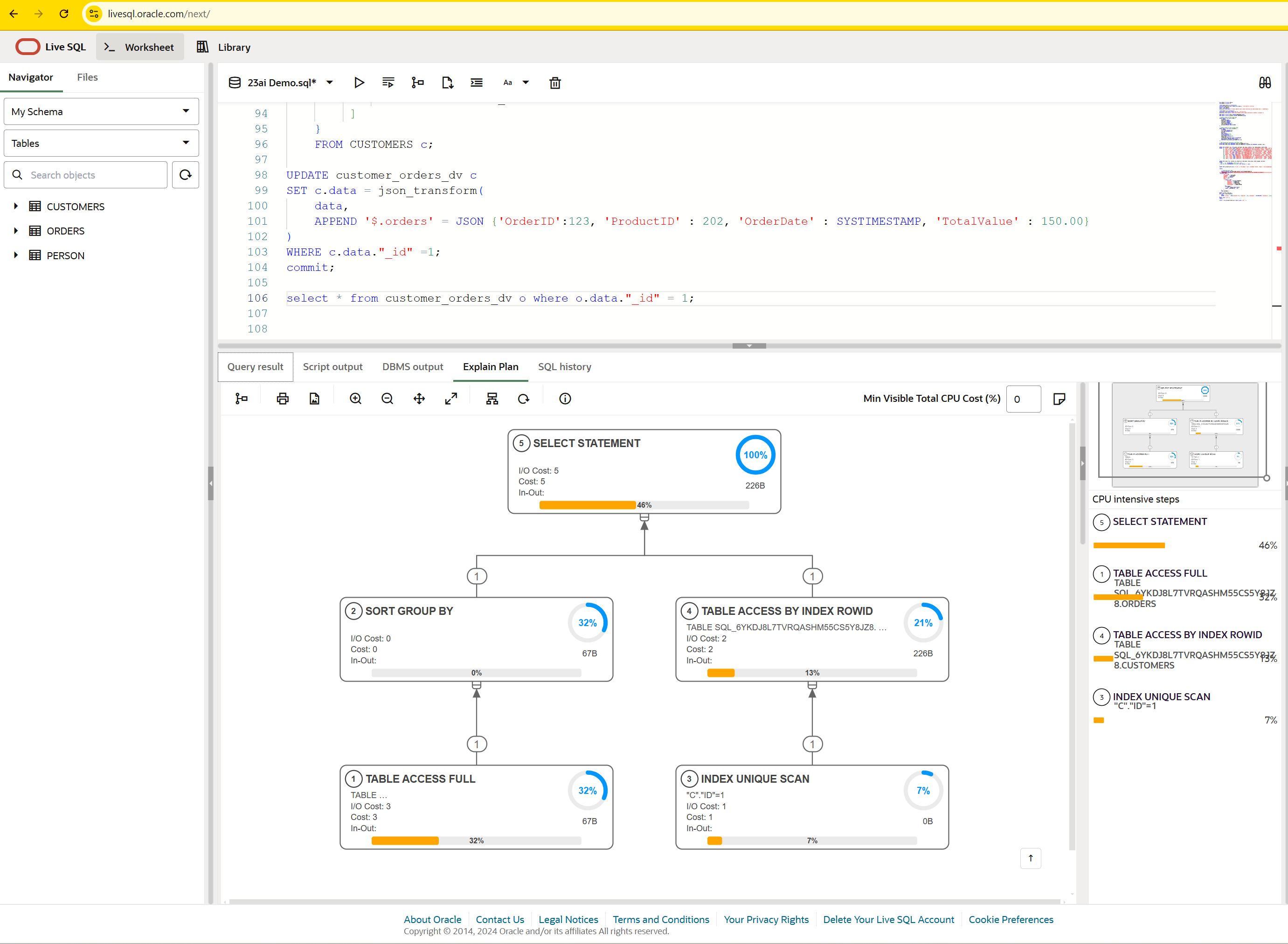
select * from customer_orders_dv o where o.data."_id" = 1;
Try this out on LiveSQL

Hit the code sample ‘copy’ button right above, and then tool over to https://livesql.oracle.com/next
Paste in the code, and run it!
Your domains, tables, duality views with annotations are all there! And you can query your data.
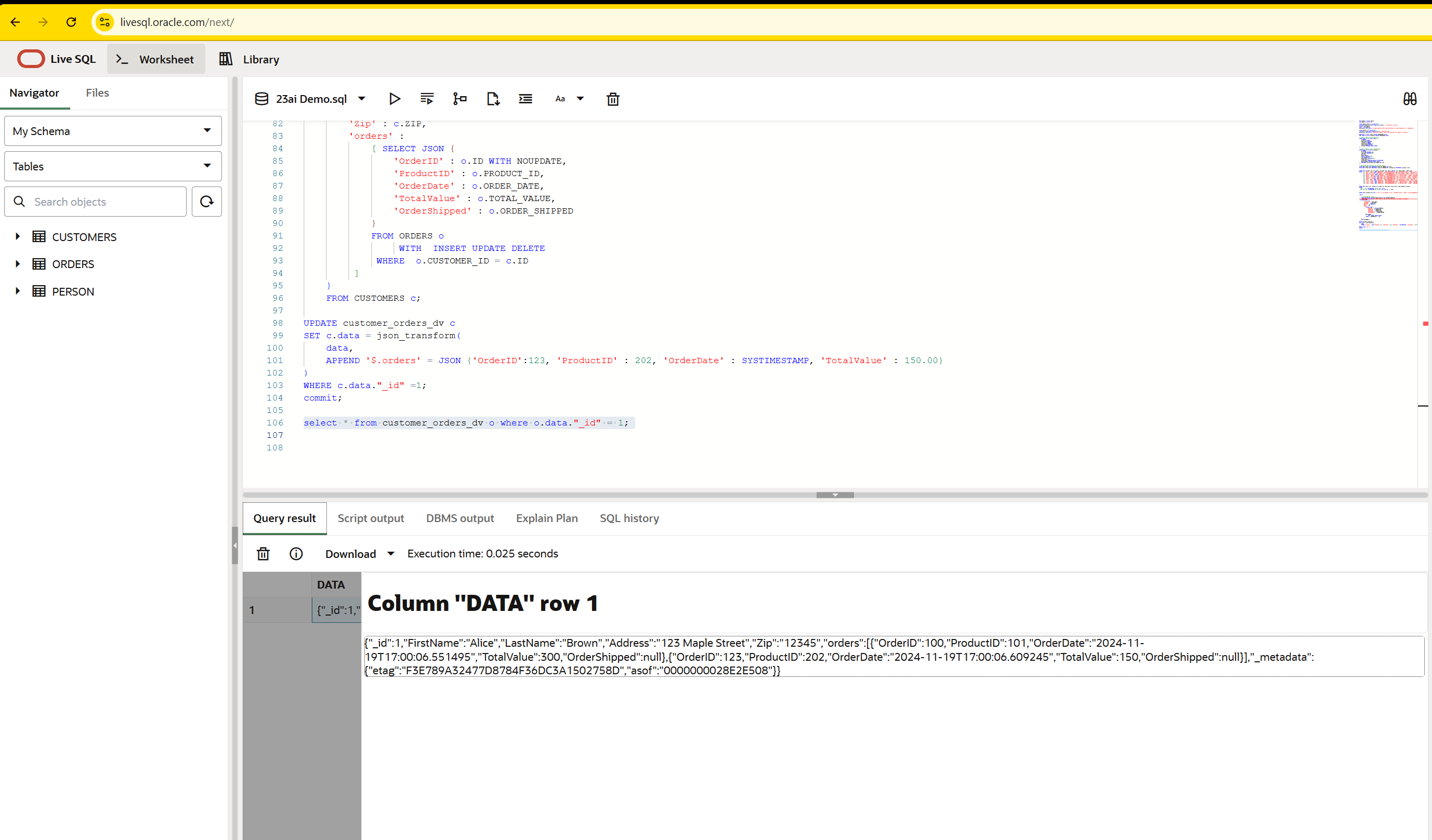
Or you can visualize an SQL plan when querying one of the duality views.