
Two major updates for the JSON feature in Database Actions version 21.2 are available, creating indexes and creating relational views.
Today I’ll take you through the BASICS of this new feature, and specifically on how to quickly create a FUNCTIONAL INDEX covering one or more JSON Attributes in your SODA Collection.
When using the SODA filtering interface, you’re effectively adding a WHERE clause to the SQL that the database engine uses to go through your JSON Documents.
And what’s the most well known ways to optimize SQL? That’s right, adding indexes. This is also possible for your JSON Collections, and now we have a very nice user interface, directly in the JSON page for Database Actions.
Note: this interface update is coming to Oracle Autonomous Database in the Oracle Cloud over the next few days…
Let’s run a ‘query’ first.
Finding Tweets where I’ve replied to @krisrice
For my ‘TWEETS‘ collection, this is pretty easy as it’s a top-level attribute.
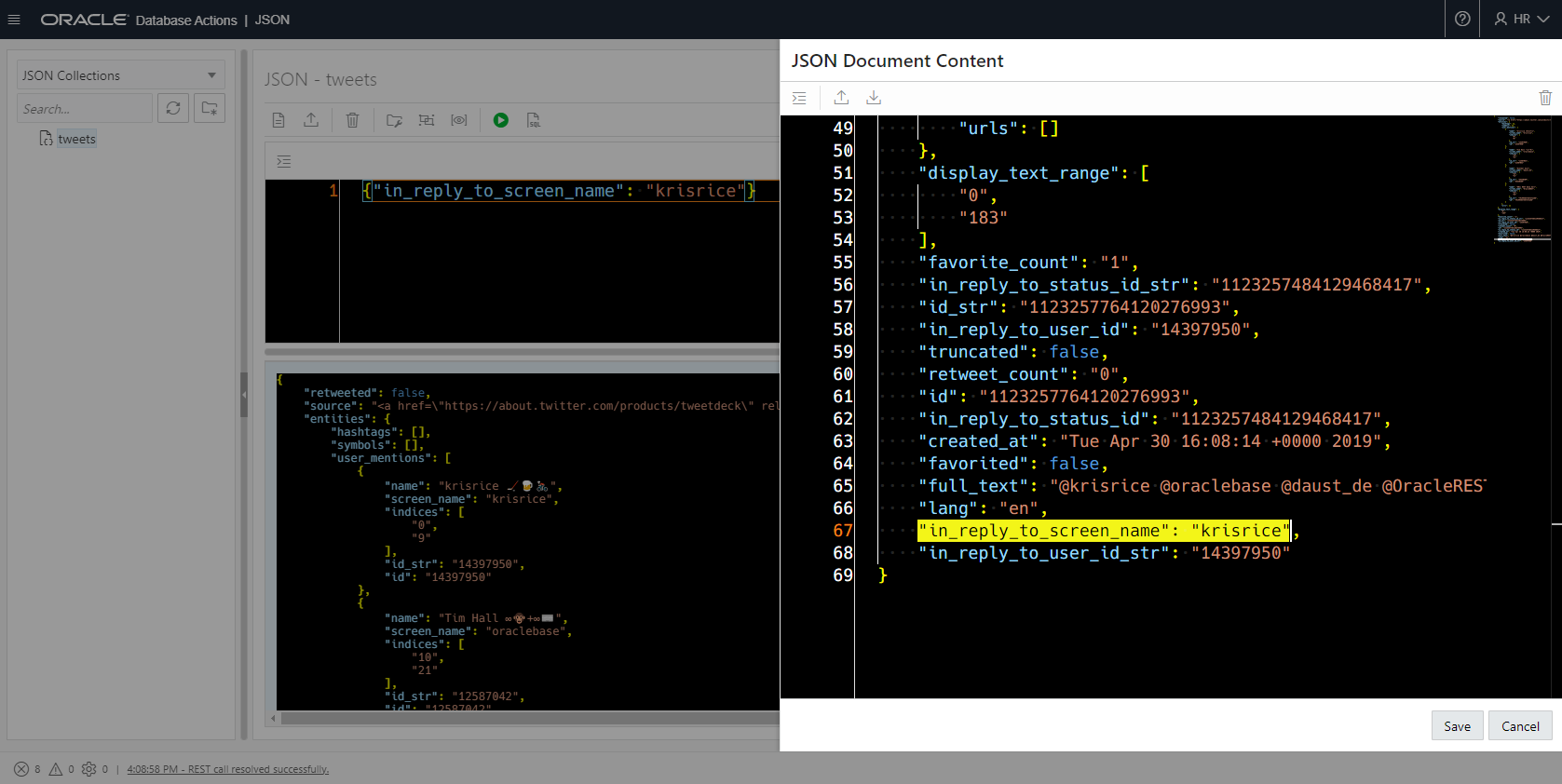
While we’re looking at our JSON ‘filter’ for our collection, I might want to go look at the underlying SQL. This is pretty easy, just hit the SQL button on the main toolbar –
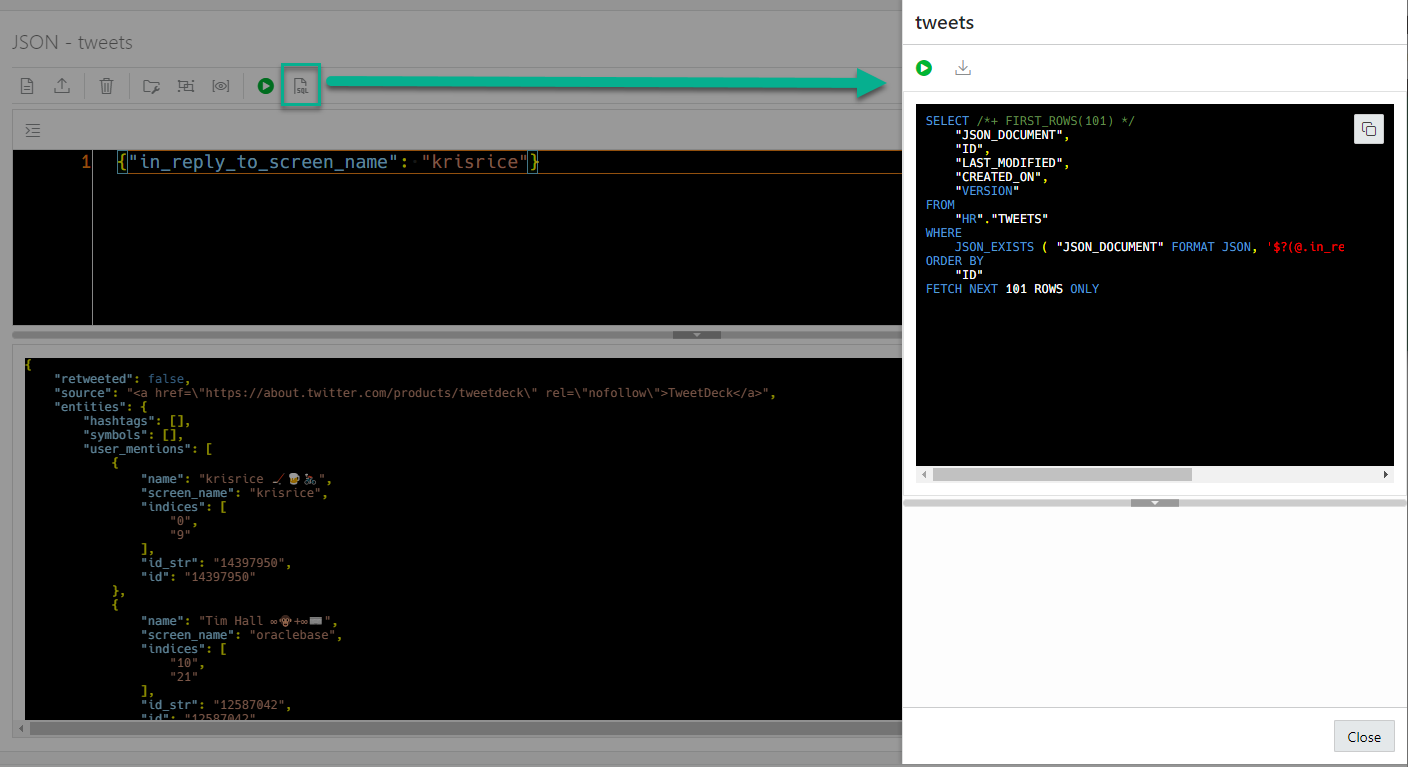
Now that I know the SQL, I can use my usual SQL skills to see what’s happening from the optimizer’s perspective. Hint: Getting the execution plan and perf stats for the query.
I copy my SQL and paste it into a SQL worksheet.
AutoTrace, Before the INDEX
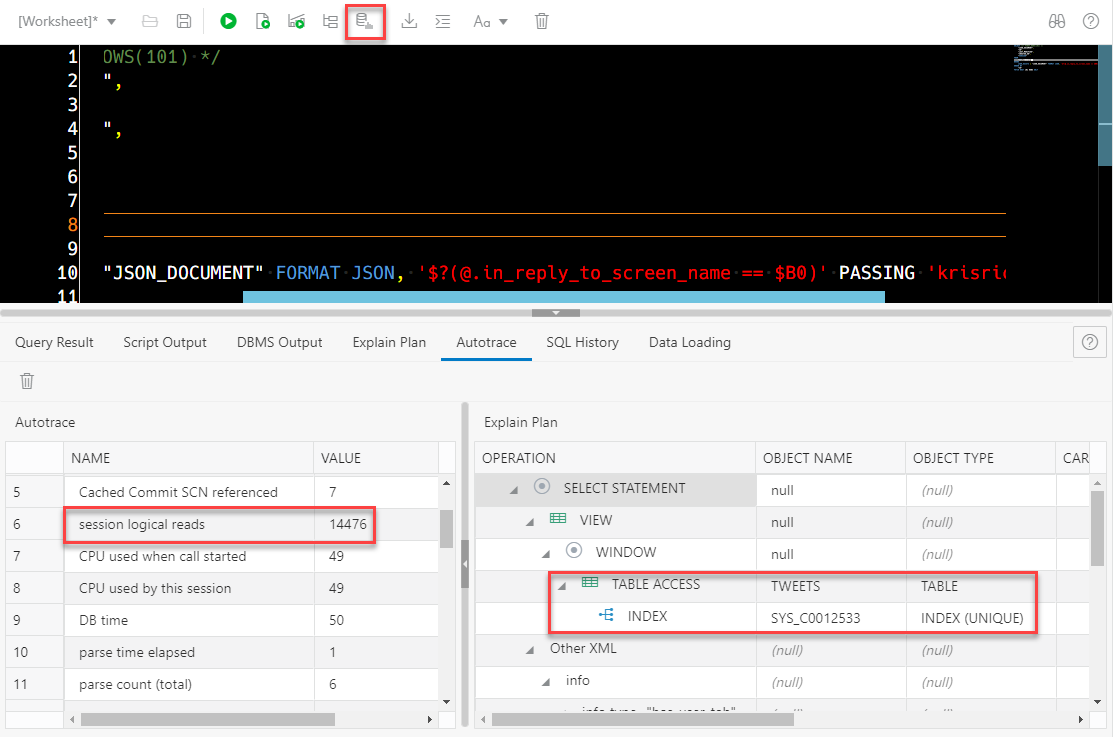
This index is a default index on my SODA (JSON) Collection – it only indexes the ID for each document in our collection.
Creating our Index
I want to give the optimizer a direct ‘peek’ at the column I’m querying.
Right-click on my collection in the JSON interface, and select ‘Indexes.’
This will bring up a list of existing indexes, or prompt me to create a new one.
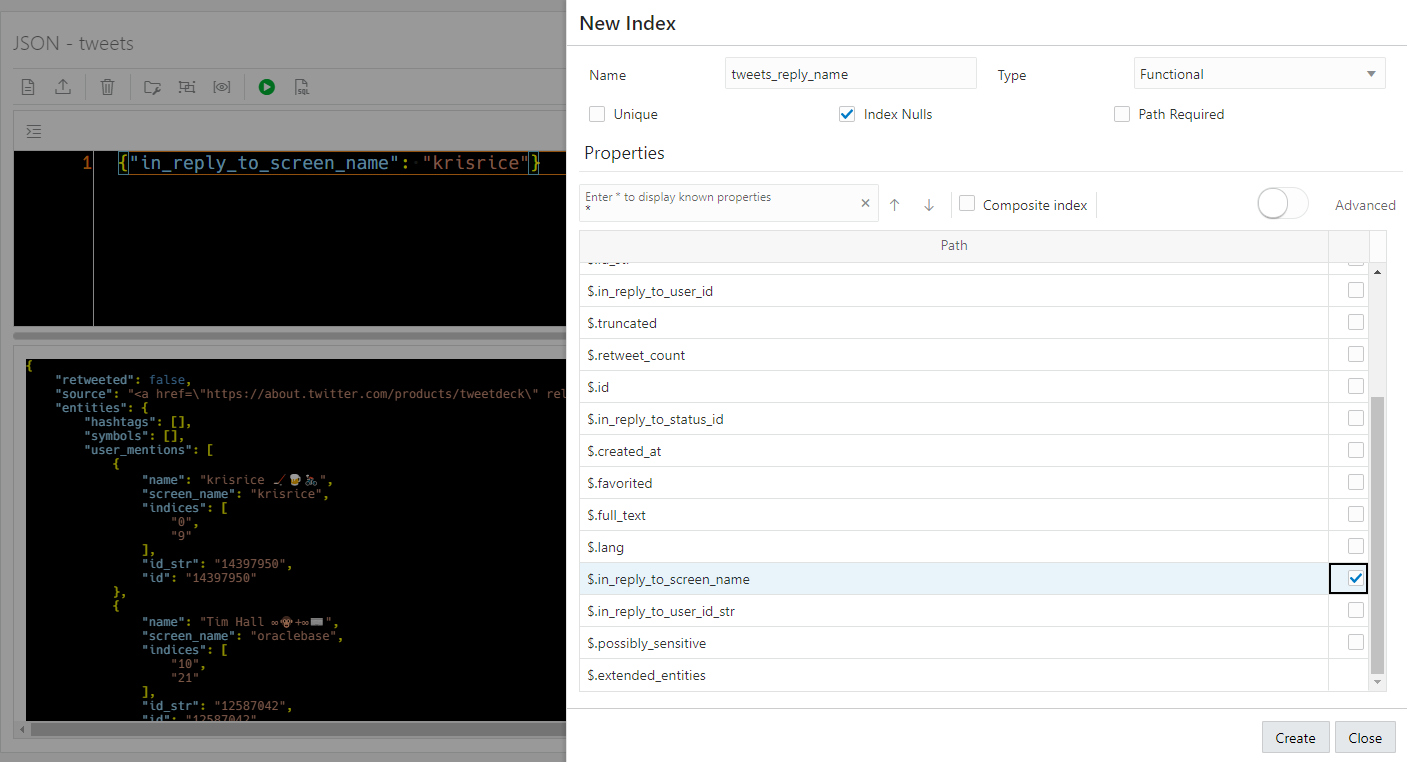
Obviously my INDEX needs a NAME. I’m going to do up a FUNCTIONAL (B-TREE) INDEX (Docs), although we can also help you with SPATIAL and SEARCH INDEXES.
If I enter a ‘*’ and hit ENTER in the properties dialog, the available list of document attributes will pop up. I see what I need, ‘$.in_reply_to_screen_name’ – and I check the appropriate check box on the right. Now, if I want a composite INDEX (2 or more ‘columns’), I’ll need to check the ‘Composite index’ box up top first.
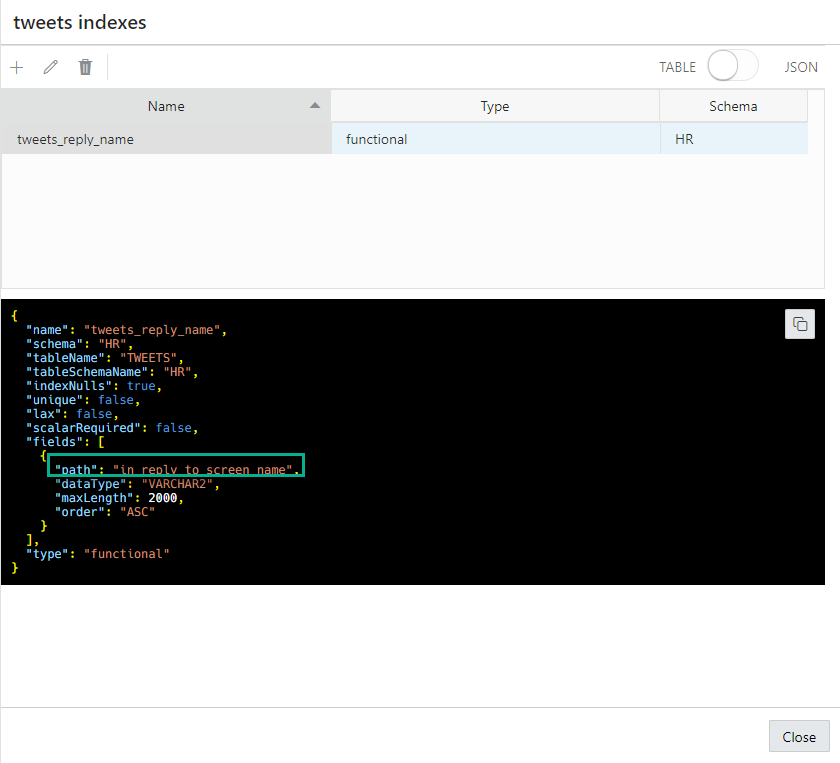
The Index Panel has created and executed for me, this DDL –
create index "tweets_reply_name" on "HR"."TWEETS" (JSON_VALUE("JSON_DOCUMENT" format json,'$.in_reply_to_screen_name' returning VARCHAR2(2000) ERROR ON ERROR NULL ON EMPTY) ASC,1)
Once the index has been created, the Indexes panel shows me what I have:
If you want to reserve less space for the indexed column, I could use the Advanced view of the INDEX wizard, and I can manually say it’s ONLY 15 characters.
Testing the impact…
Since I’m NOT in autonomous, I’m going to collect stats on my table/index FIRST. Then I’m going to run my query again through the AutoTrace dialog.
By the way, AutoTrace takes a snapshot of your session stats, runs the query, takes another snapshot of your sessions stats – computes a DELTA of those two snapshots, and then grabs the XPLAN of your query.
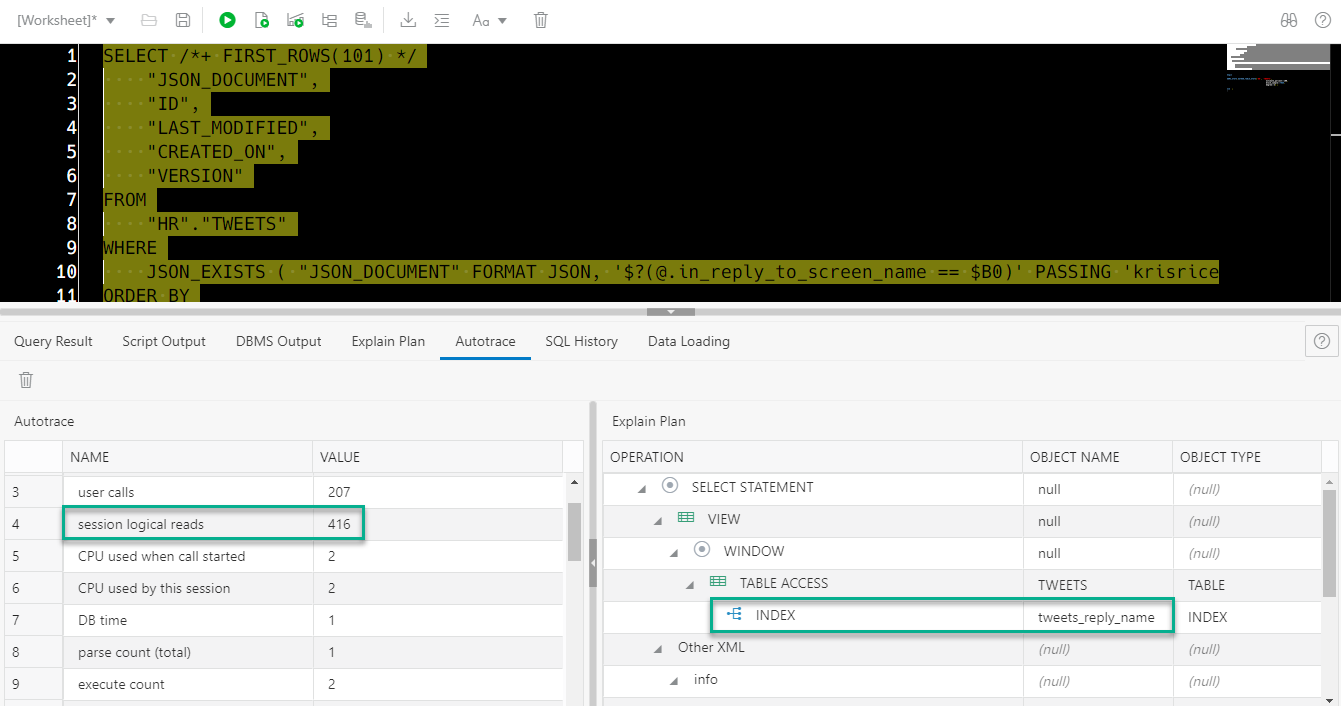
Is this a win? It would seems so, but of course one should perform the required load and functional testing before implementing these sorts of changes to production. More indexes doesn’t always lead to better outcomes.




