I originally titled this “Tips on Importing Excel to your Database and “Data Modeling,”‘ but SEO and stuff led me to shorten the post. Hence this next awkward opening.
Why did I put Data Modeling in quotes? Because ingesting an excel file to your database and having a table created ‘as is’ IS NOT data modeling! Unless that Excel spreadsheet was the end result of a data modeling exercise, but let’s not kid ourselves.
But this post isn’t meant to soley be a rant, I want to HELP YOU be successful!
I’ve found certain problems arise more often than others when I have an occasion to grab some data off the innerwebs or someone sends me their ‘problematic’ Excel file that they want ‘sucked into the database.’
Today’s post was largely inspired by @krisrice sending me this link. A redditor did a survey of 5,000+ developers, and I decided to put that into my DB for giggles, and to also do some regression testing on SQLDev, Database Actions, ORDS, and SQLcl.
The cruelest joke is that after you dump through all these hoops to get your data into Oracle, at the end of the day know that someone else will suck it right back out to Excel.
Anyways, I figured after fixing up this spreadsheet, you might enjoy seeing all of the different things I pay attention to so that I don’t waste time trying to get data loaded. Helping 200,000+ people import their data from Excel to Oracle Database has trained my brain to be very particular about certain things…
Note that these tips may or may NOT be specific to SQL Developer or the tools.
1. Use the Right Data Types
If you’re importing data to a NEW table, that is, you’re using the CSV or Excel file to define the table properties, bring in DATEs as DATE columns. Or TIMESTAMPs.
Our tooling will try to help you interogate the text that represents a DATE so it can be correctly inserted into a DATE field.
If we’re not able to decipher it, you’ll need to provide it. And you can get quite creative in supplying the Date/Time formats fed to the TO_DATE() function. I will spend more than a few minutes experimenting and checking out the Docs if it’s an odd pairing of whitespace, delimiters, and date jumbling…
Not sure if you should go CLOB or just ‘big’ VARCHAR2s? Use VARCHAR2 until you can’t.
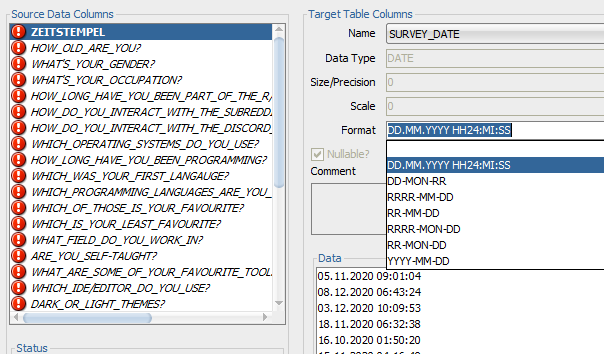
2. Tip on Dates: VALIDATE_CONVERSION
Yes, I know storing dates as text is utter rubbish, BUT, what if you can’t figure out the correct DATE format model when doing an IMPORT?
— Jeff Smith 🍻 (@thatjeffsmith) March 10, 2020
I can now have a go at it with validate_conversion() until I get it JUST righthttps://t.co/y7X1Ujcl3V pic.twitter.com/HQHFolPlLn
You can use a simple query through the DUAL table using this function to see if you’ve got it just right for the data you’re about to import.
3. Or Don’t Worry about it, bring everything in as VARCHAR(4000/32000)
The quickest way to success is don’t define anything really other than your table and column names. Then once the data is in the database, use SQL or more DDL to ‘fix it up, proper.’
I will tell you that I’ve personally found it easier to do the ‘futzing around’ on the client side. Once it comes into the database, I’m likely to forget about making it ‘good.’
If it’s really-real data, I’ll do actual data modeling. That is, ask critical questions – what does this data represent, how will it be used, is it related to anything else, should be be normalized – broken down into separate tables, etc.
I’ll then go CREATE that schema, and then use the tools to simply import the data into the proper places.
Are you the ONLY one who will ever see this code? Is performance not a big deal because it’s a few measly thousand rows? Then maybe this is OK. But don’t let this shortcut make it’s way into anything close to your code and regular processes.
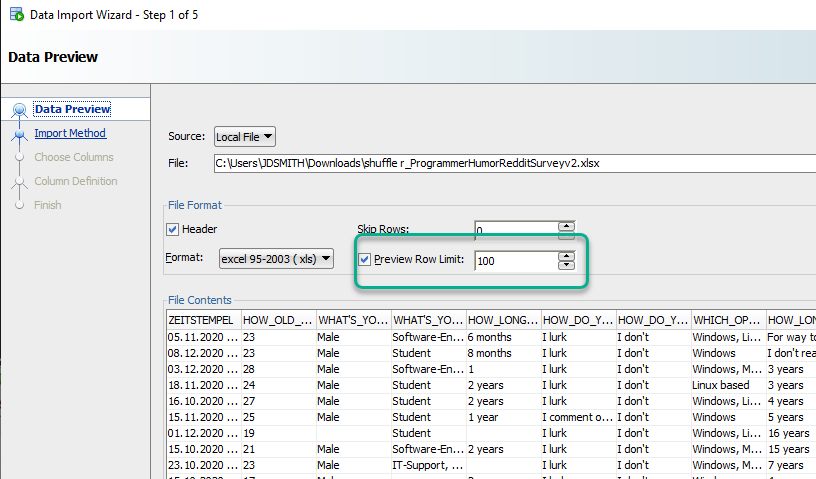
4. Set your preview window to ALL THE ROWS if…
…you’re not sure how wide to make the text columns.
By default our tools scan the first 100 rows of your data, looking to the width of the strings, and trying to determine if any of those strings are actually dates.
So when you go to run the scenario, some of your rows will fail. We’ll be nice and tell you which ones, so you can re-size, and run those failed INSERTs to bring in the ‘bad’ records.
But, it gets annoying.
So my advice?
Do the proper modeling – how wide should a zipcode be? This is a trickier answer than it appears, and if you think ZipCodes should be numbers, boy are you in for a surprise!
If you have no idea how wide they should be, or if there is no predetermined, logical reason to restrict the size, then go with the maximum (4000 or 32k). Just know that if you’re going to be indexing these columns, you may run into some restrictions later.
If I’m importing 5,000 records, then I’ll set the preview window to 5000, and let the tool pick my widths for me and be done with it.
If I’m importing 10,000,000 rows from CSV..well then, I don’t set the preview window to 10,000,000. I do some thinking or I set everything to the max.
5. Beware Excel Macros!
Just remove them all. Easiest way to do this? Select everything in the workbook, copy to clipboard, and then paste back in using the Paste Values option – macros don’t get copied to the Clipboard. Then save to a new file and move on.
6. Beware HUGE Excel Files!
I mean like tens or hundreds of megabytes. An excel file is actually a collection of archived (zipped!) XML files. Opening one and parsing it is a pain, and NOT cheap! So if you’re wondering why SQLDev is taking ‘forever’ to chunk through your Excel file, it’s because there’s a LOT of work to be done.
If it’s a HUGE Excel file, save it as a CSV, and import THAT. CSV are plain text files…MUCH easier to parse, scan, read into memory. And easier = faster.
If you go this route, be sure you’re not losing things like leadings 0’s on fields that look like numbers but should actually be strings, and make sure you don’t have strings that line-wrap, as a CR/LF generally indicates a new record in CSV.
Fighting strings with multiple lines in a field is the biggest pain with CSV…
7. Mind the NULLS and Blank Lines
If your table doesn’t have a PRIMARY KEY defined or any columns defined as a NOT NULL, then if your incoming CSV/Excel has blank lines/rows, you’ll see those same empty rows (ALL NULLS) when you’ve imported your data.
The fix is easy – add a Primary Key constraint, on either a ‘natural key’, something unique in your incoming data set or use a IDENTITY column, with the option to generate the value by default ON NULL.
If I want to have a new column in my table added, I’ll often put that in there and give it a DEFAULT value, then my import will run and the row will have what I want it to, even if the data’s not included in the originating CSV/Excel.
8. Detecting patterns…
Are you doing this on a regular basis? That should be screaming to the developer brain inside of each of us that there’s a probably a better way than this ad hoc point and click stuff.
Almost anything can be scripted. Including bringing in data from Excel and CSV. We’re putting ALL of this GUI power into SQLcl as commands. I’ll have more to say on this later this year.
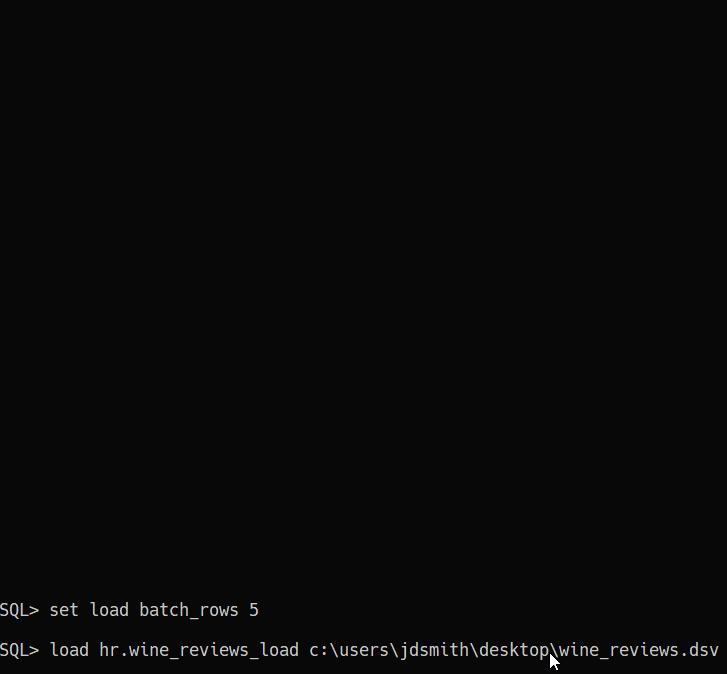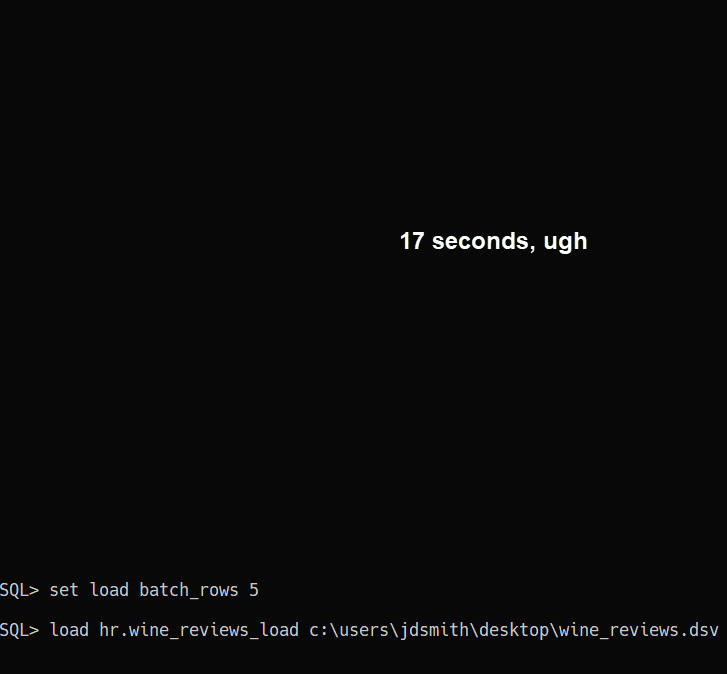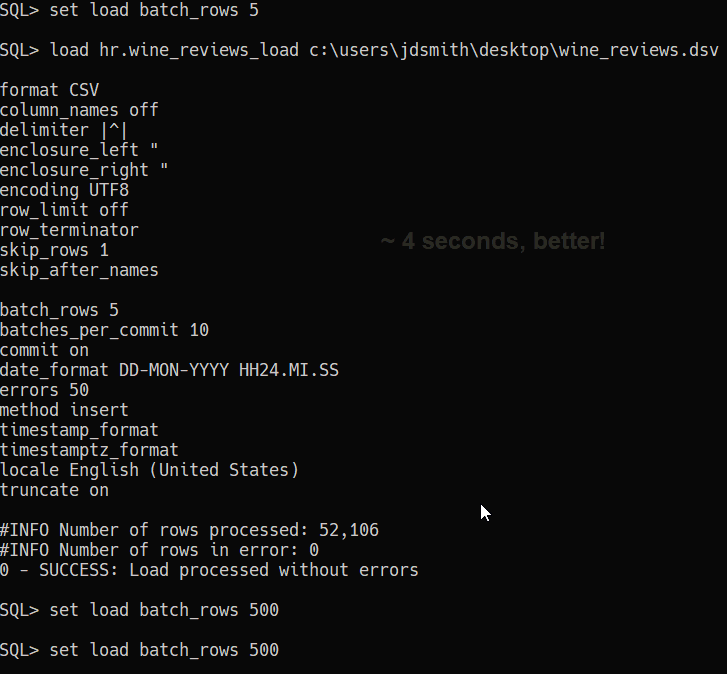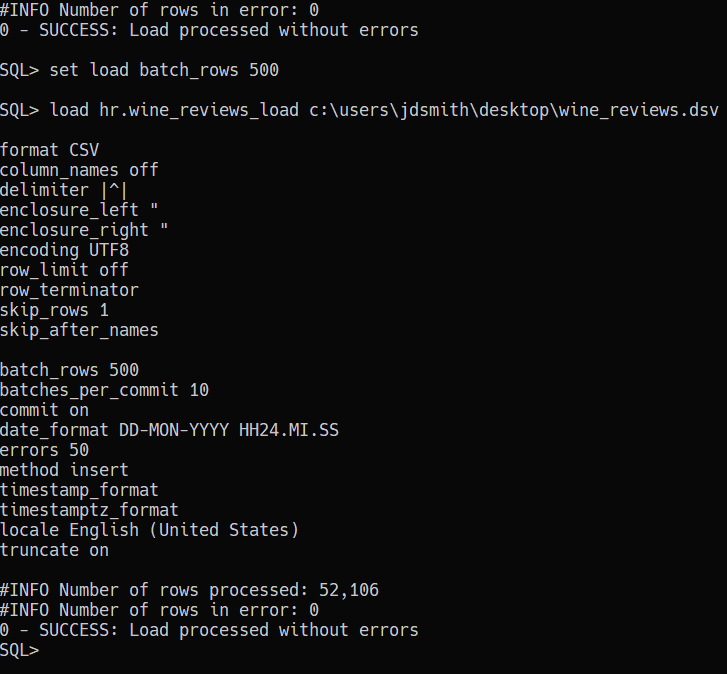
9. Don’t forget the RESTful Path
The ?batchload POST APIs on REST Enabled tables let you do the same CSV batch loading that SQLcl or SQL Developer offers in their CLI and GUIs. And it’s not terribly slow.
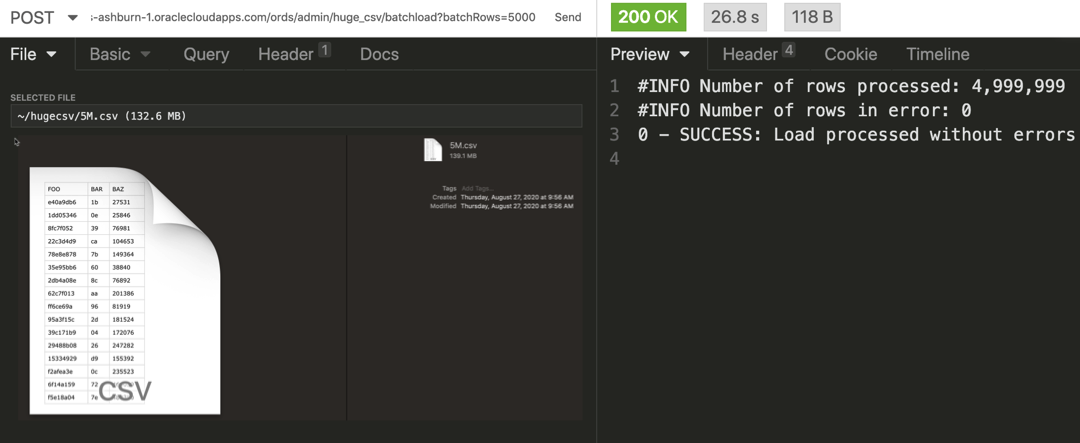
10. We’re doing this for a good reason
Once the data is in our database, we have a single source of truth, not 10 versions of an Excel file floating around. This is an EXCELLENT reason to build an APEX app around the Interactive Grid. But also, our data will be included in our backups, it’ll be easily accessed via SQL or any standard database tool.
Folks will always demand Excel, but at least make sure the data they’re grabbing is good at the moment it’s leaving home.
11. Almost forgot… “stupid column names”
DO NOT DO THIS. Do not punish your developers, your end users, your applications by being forced to support horrible object and column names just because they’re in your excel file.
Just because you can do things like CREATE TABLE “TaBLE” (“COLUMN” integer); … doesn’t mean you should. And in fact, almost never. If you’re migrating from say SQL Server and you don’t want to rewrite a ton of code, I’m happy to give you an exemption on this rule.