Our new JSON interface is now available in SQL Developer Web in your Oracle Autonomous (Shared) instances!
In an earlier post, I discussed this new feature in SQL Developer Web, our JSON workshop.
Quick Recap, you can access this feature, IF you have:
- a 19c or higher instance of an Oracle Database,
- a database user with the SODA_APP privilege,
- an instance of ORDS version 20.3 or higher.
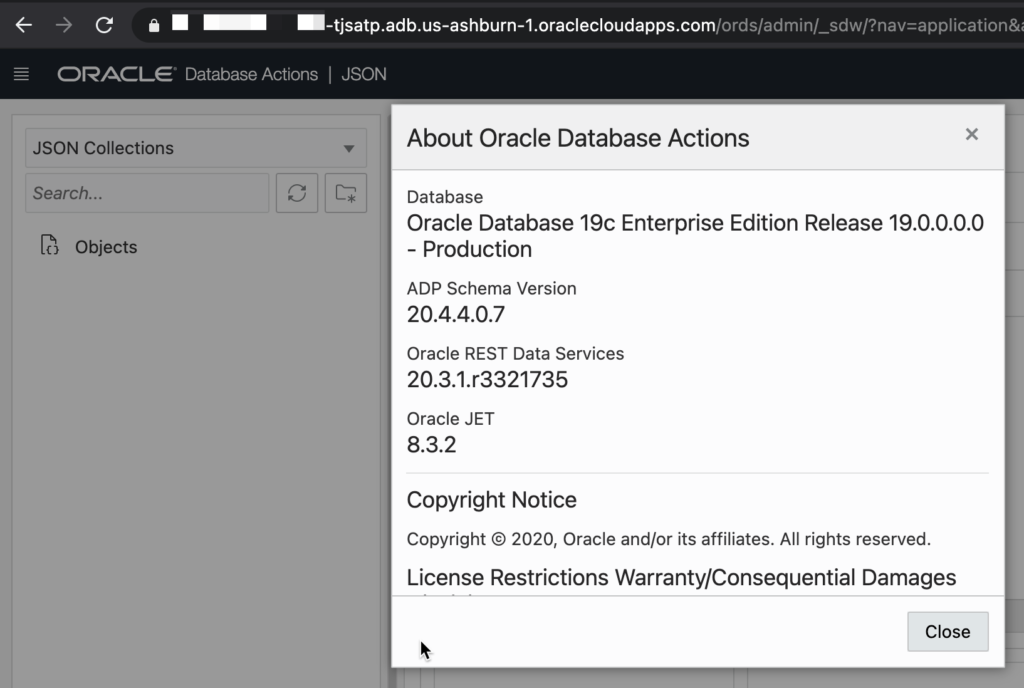
For the Oracle Cloud, the Autonomous Shared instances require ORDS 20.3.1 to activate the JSON interface.
That’s being deployed now, and here’s how that looks in of my Always Free ATP intance running out of the Ashburn data center:
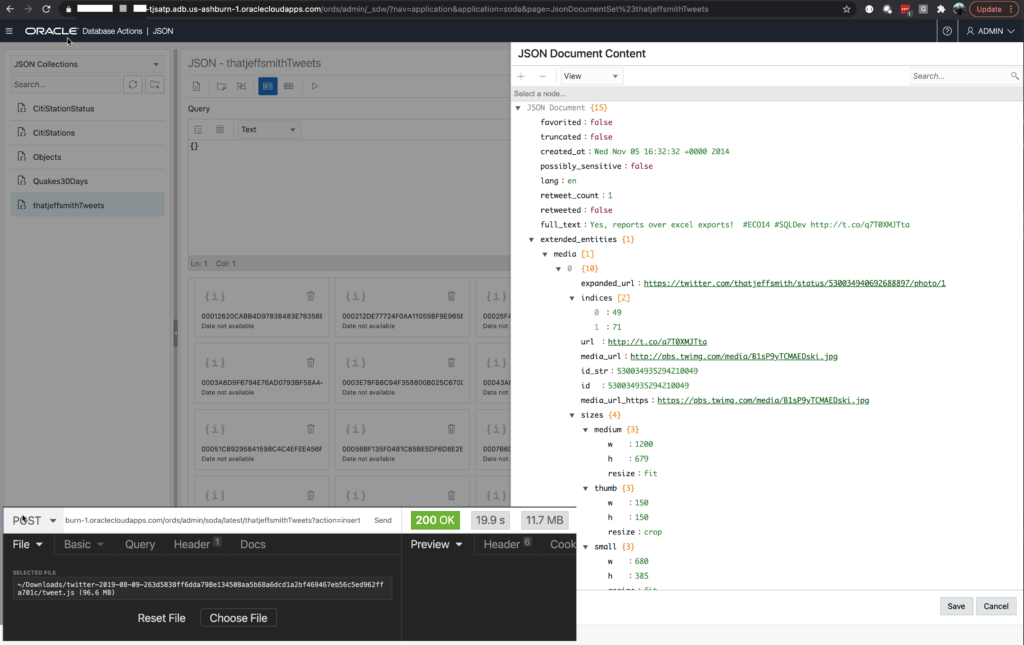
Instead of just talking about the feature AGAIN, I thought I’d take a second to show you how to use ORDS and HTTPS to bulk load data to Oracle Autonomous Database.
Bulk Loading Documents, via REST
I’ve talked about how quickly you can bulk load CSV as rows in a table over HTTPS using ORDS, but what about if that was JSON? And instead of rows in a table, we wanted documents in a collection?
Let’s do that now.
Step One: Building the JSON
My step one is contrived, I’m assuming most developers will already have loads of JSON documents they can play with. But I want to create a scenario where we’re starting from nothing.
We’re going to use SQLcl to spool the results of a query to a JSON file.
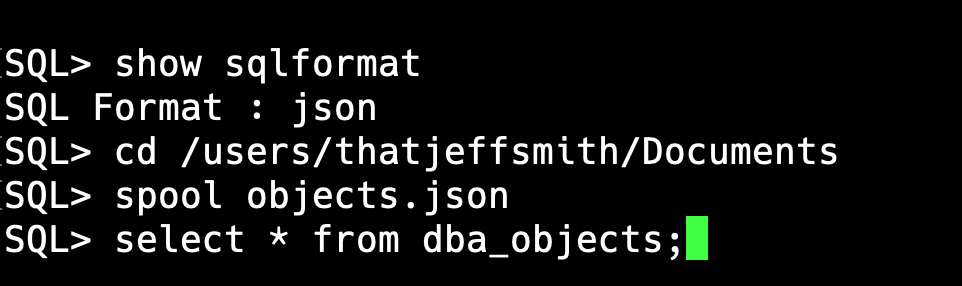
And after that’s ran on my somewhat small local instance of Oracle…
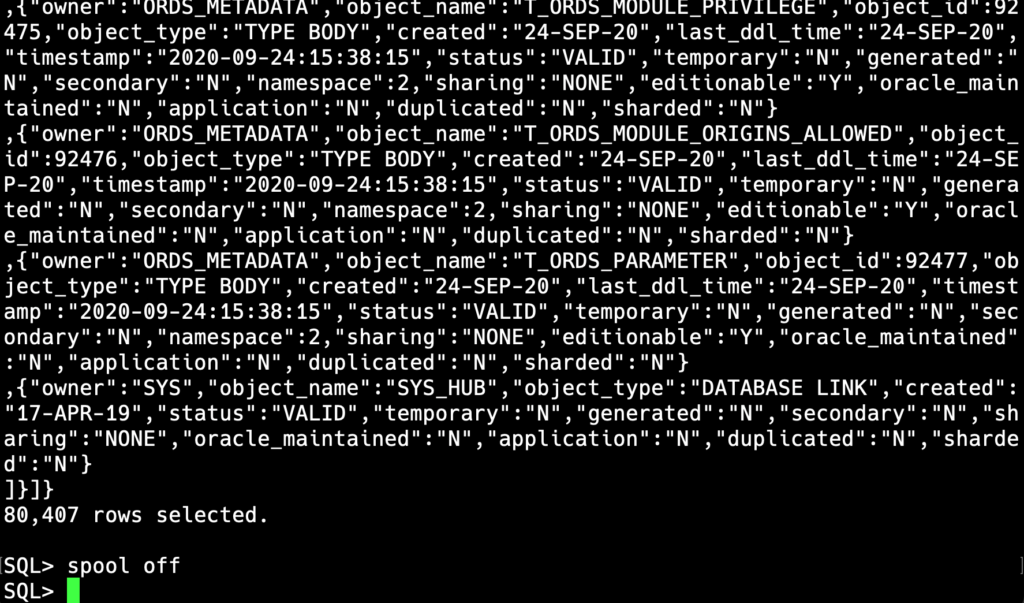
You may want to use ‘set feedback off’ – that way your spool file won’t have the rows selected text.
I’m going to use my goto text editor to trim the JSON file such that it’s just an array of records, so it looks like so –
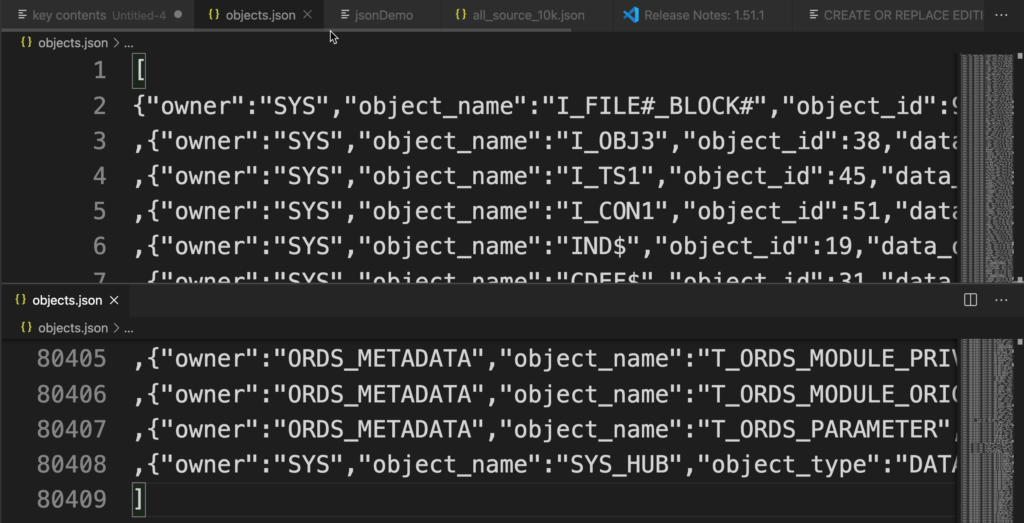
This took me about 30 seconds, start to finish to manage.
Step 2: Creating the Collection on Autonomous
This could also be done via HTTPS and a REST call, but we’ll step over to the UI just to make sure everything’s as expected.
My user has the SODA_APP priv, so the JSON feature is available on the Development panel of SQL Developer Web.
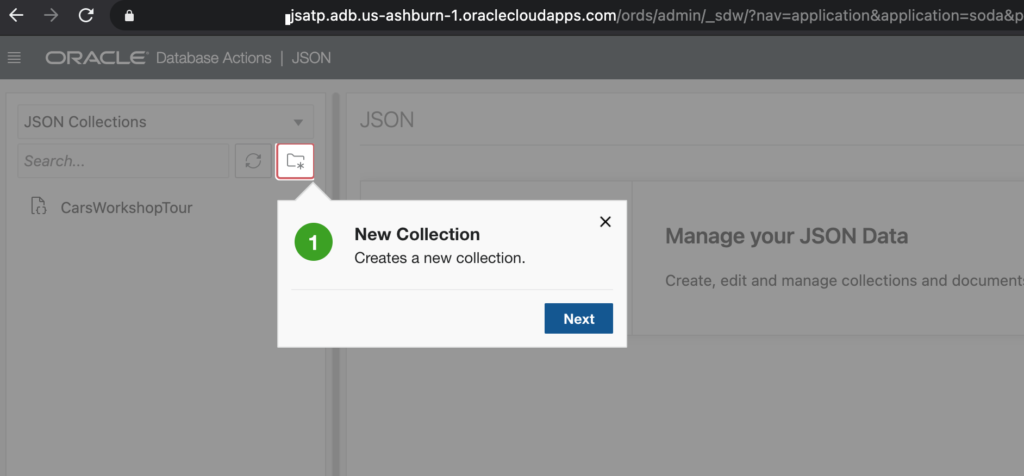
I’m going to take the tour’s advice and create my first collection. It’s going to be a VERY simple call, I’m just going to supply the name for my Collection, and let the database manage the rest.
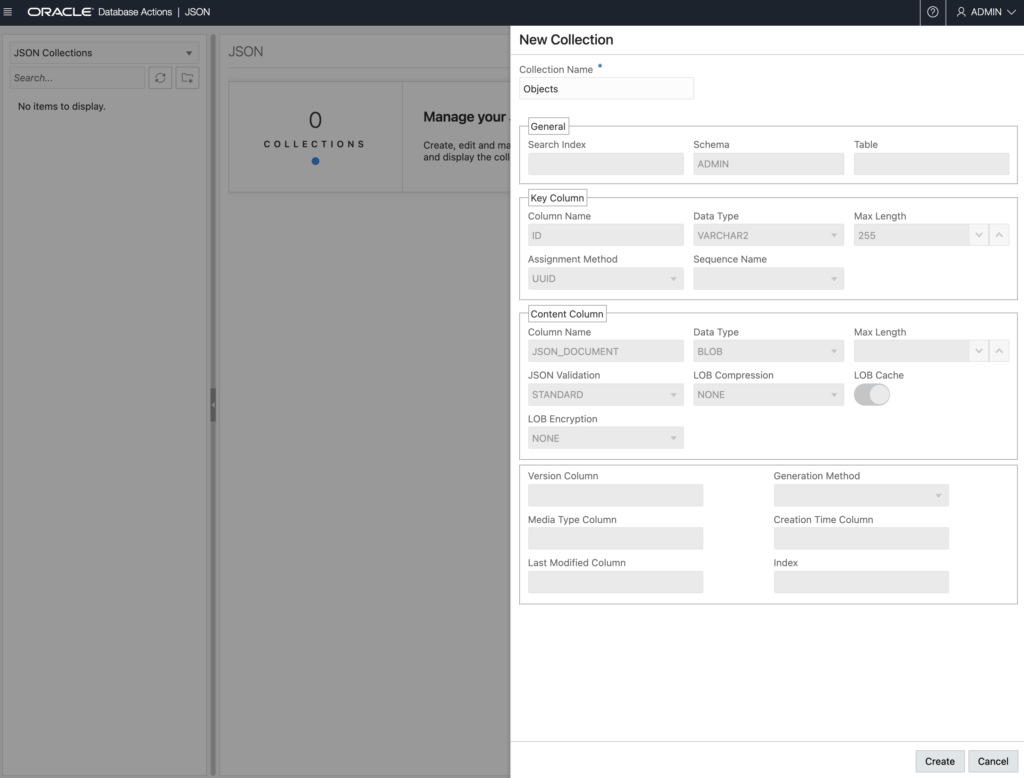
After I hit the ‘Create’ button, I see my new, and EMPTY! collection.
Step 3: Loading the documents
I need a few things to make the HTTP POST call.
- the request URI
- the file
- the authentication required to access the URI
Finding the URI comes down to looking at your URL for SQL Developer Web. We’re going to take everything up and to the REST Enabled SCHEMA alias.
Mine looks something like this –
https://abcdefghijklmn-tjsatp.adb.us-ashburn-1.oraclecloudapps.com/ords/admin
I’m using the ADMIN account, you should be using your development or application schema.
The name of my Collection is “Objects”, so to make the call to load the documents, we’re going to append this to the URL above –
/soda/latest/Objects?action=insert
The file, well it’s wherever you placed it, I’ll assume you can manage finding that in your REST GUI or in bash.
The authentication, well you have two options there.
- Database Authentication – easy, just supply your database username and password. This is probably OK as long as it’s just you using it.
- OAuth2 – also easy, you need to create a Client, and grant that client the oracle.soda.privilege.developer privilege
I’m going to use option 1 for simplicity.
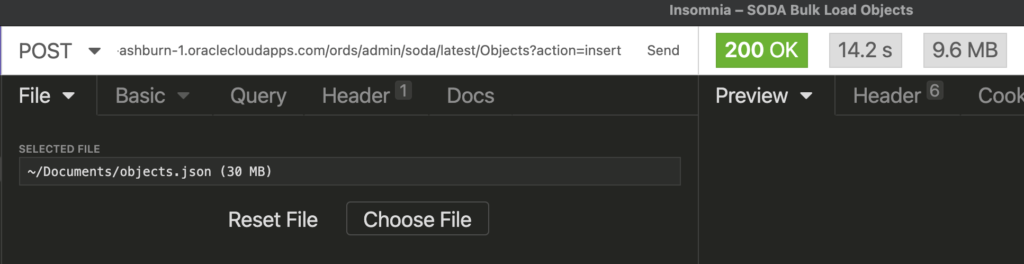
So in 14 seconds, I’ve loaded 80,000+ new documents to my JSON Collection in the Oracle Autonomous Database in the Oracle Cloud using just HTTPS.
Me, just now.
I could do a {} search on the collection to see all of my documents, but let’s instead just look for the VIEWS that belong to ORDS_METADATA.
The QBE syntax for that request would be:
{
"$and": [
{
"object_type": "VIEW"
},
{
"owner": "ORDS_METADATA"
}
]Place that in to the Query panel, hit the ‘Go’ button in the toolbar, and you’ll get your results back. Clicking on a Document, labeled with the ID, will open the JSON editor.
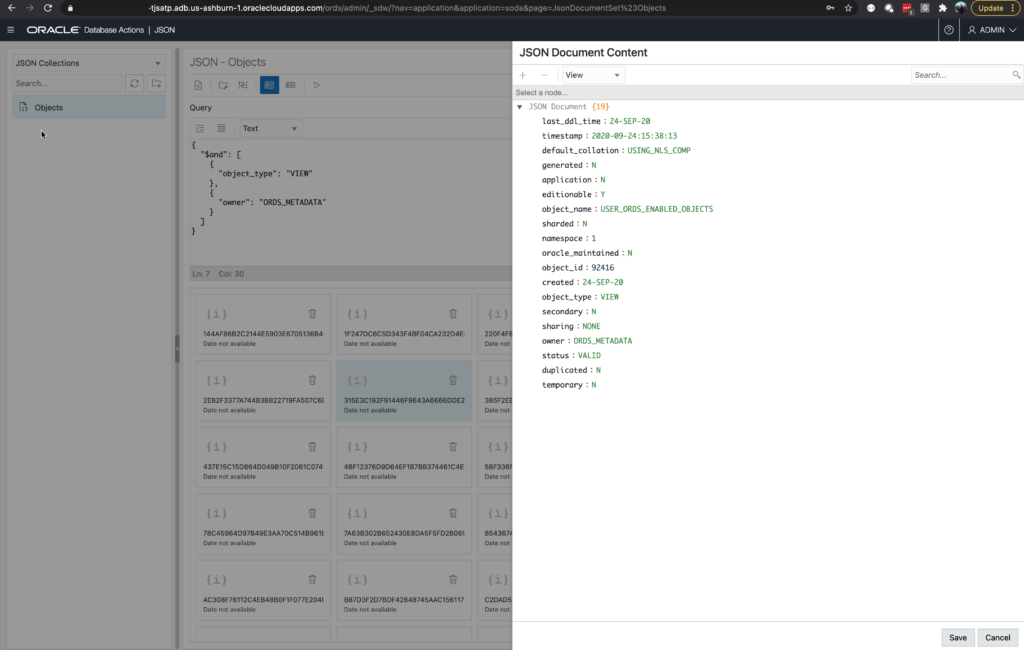
I realize these documents are quite simple, and don’t really show off the flexibility of a JSON ‘schema,’ but I imagine you’ll have your own documents to work with.
20.4 Sneak Peek
Version 20.4 of ORDS/SQL Developer Web will introduce Query History in the JSON QBE interface, AND you’ll see your JSON documents immediately when browsing and running QBE requests.
Hold my beer, says someone online
A friend mentioned this isn’t quite a real world example, and I would quite readily agree. One of the challenges I found finding good, real data online as JSON. I’ve found CitiBike (talked about that last week, but it’s quite small), and I was pointed to some GeoJSON data from the USGS used to track earthquakes, but I had issues with that.
But then I remembered…I had exported ALL of my Twitter data earlier in the year. All 100,000 or so Tweets…and THAT’s stored as JSON.
So let’s have a go.
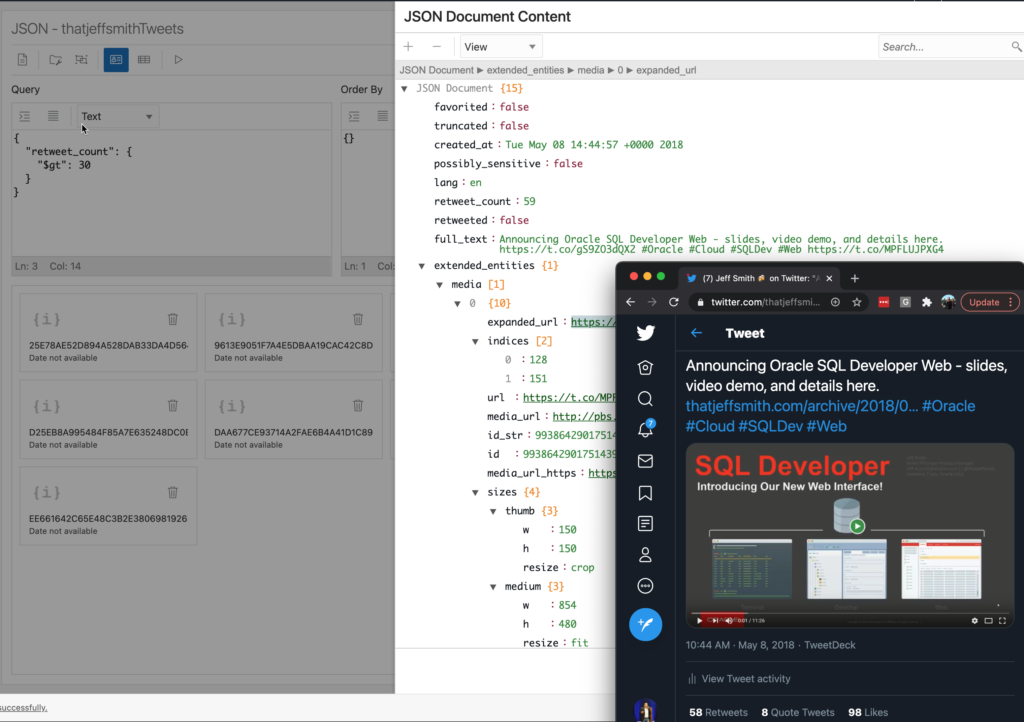
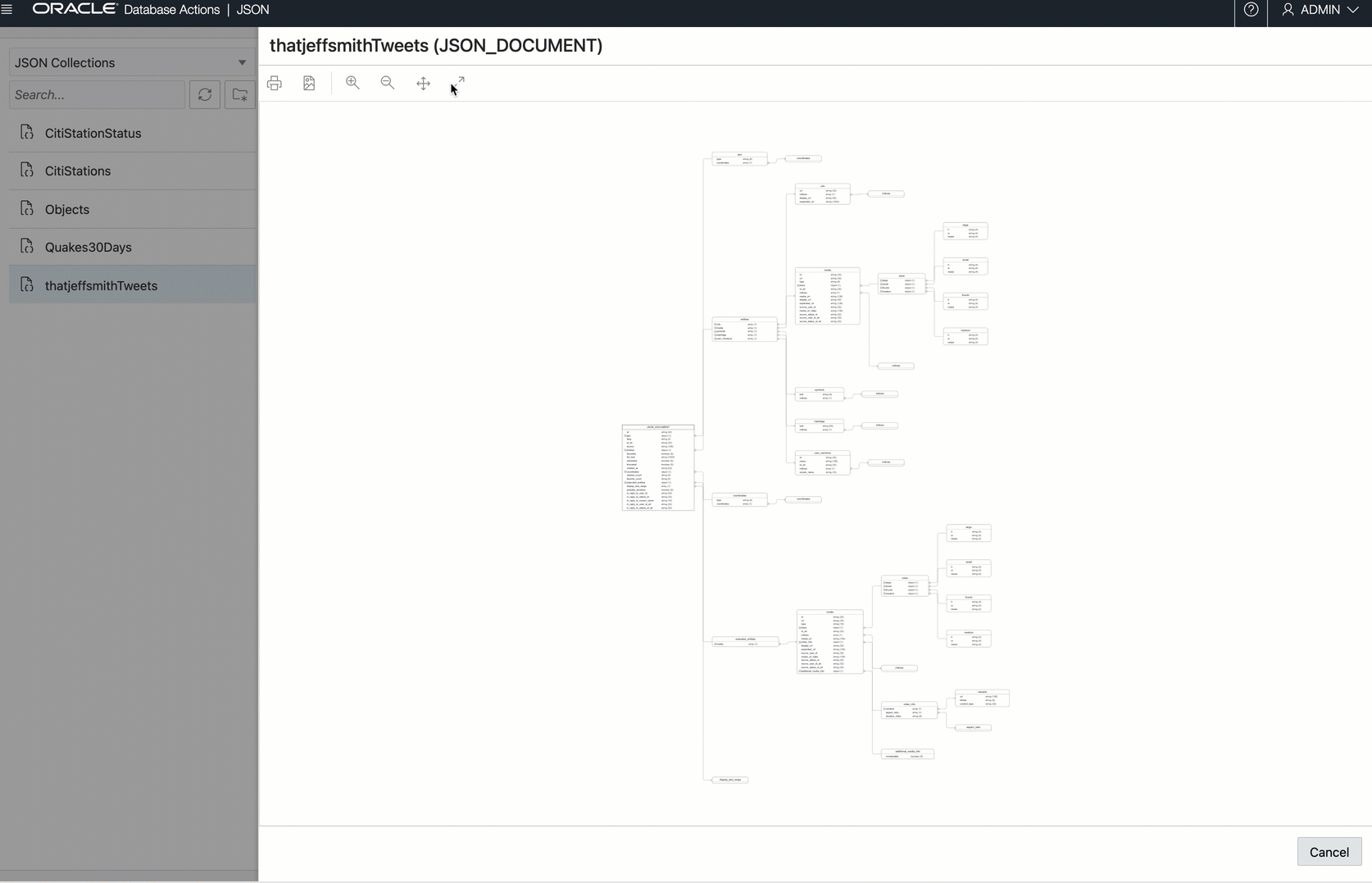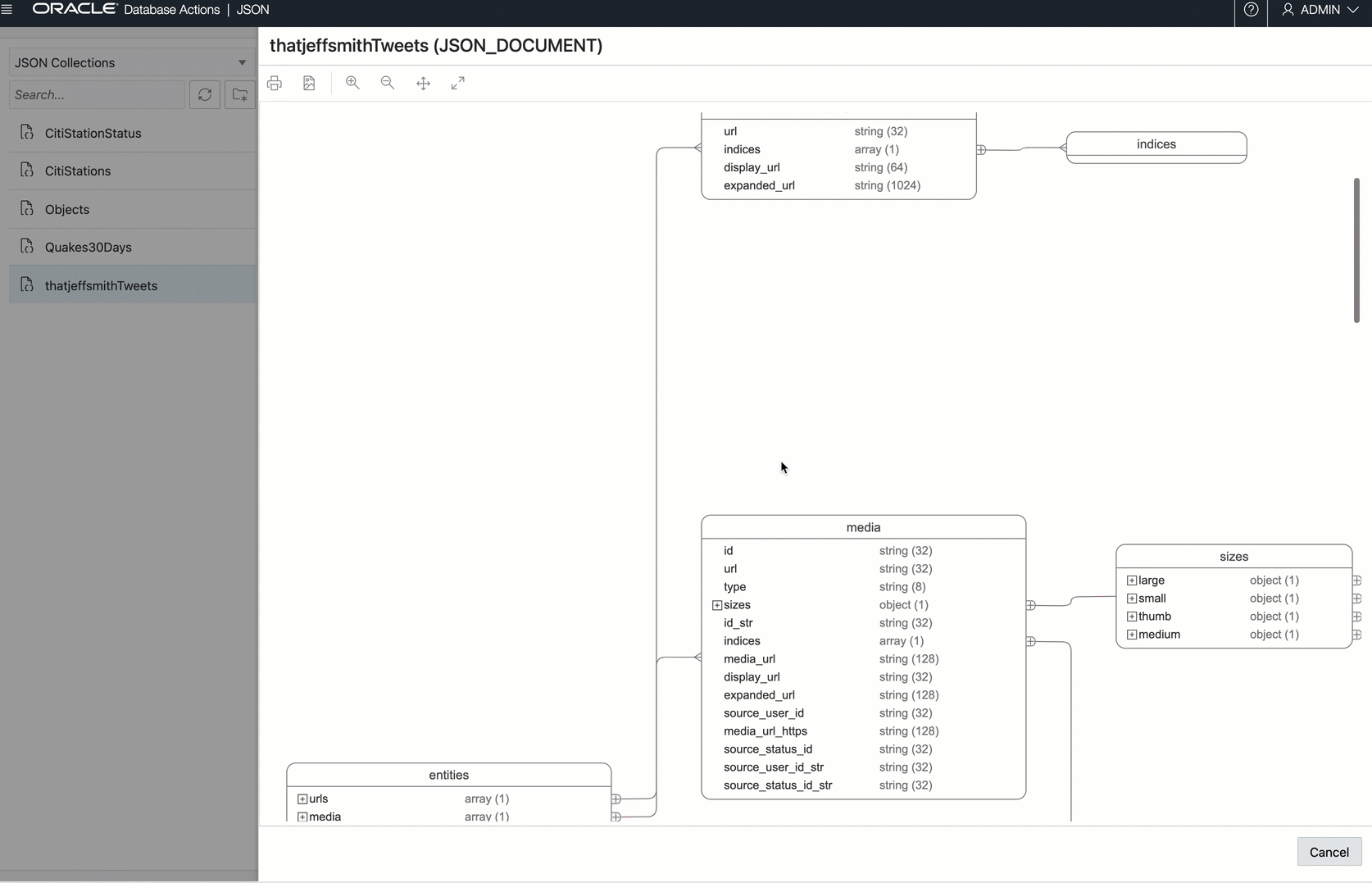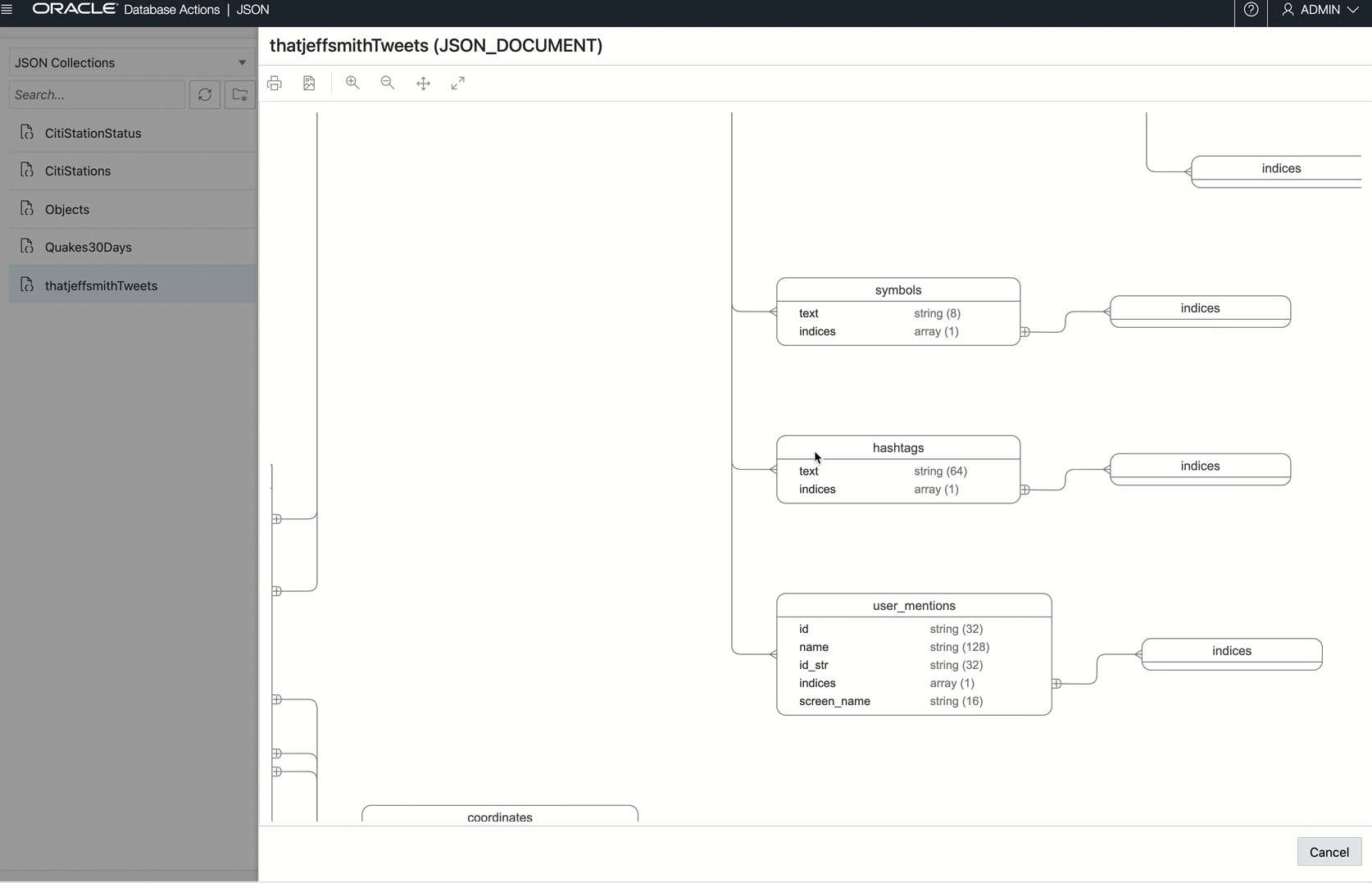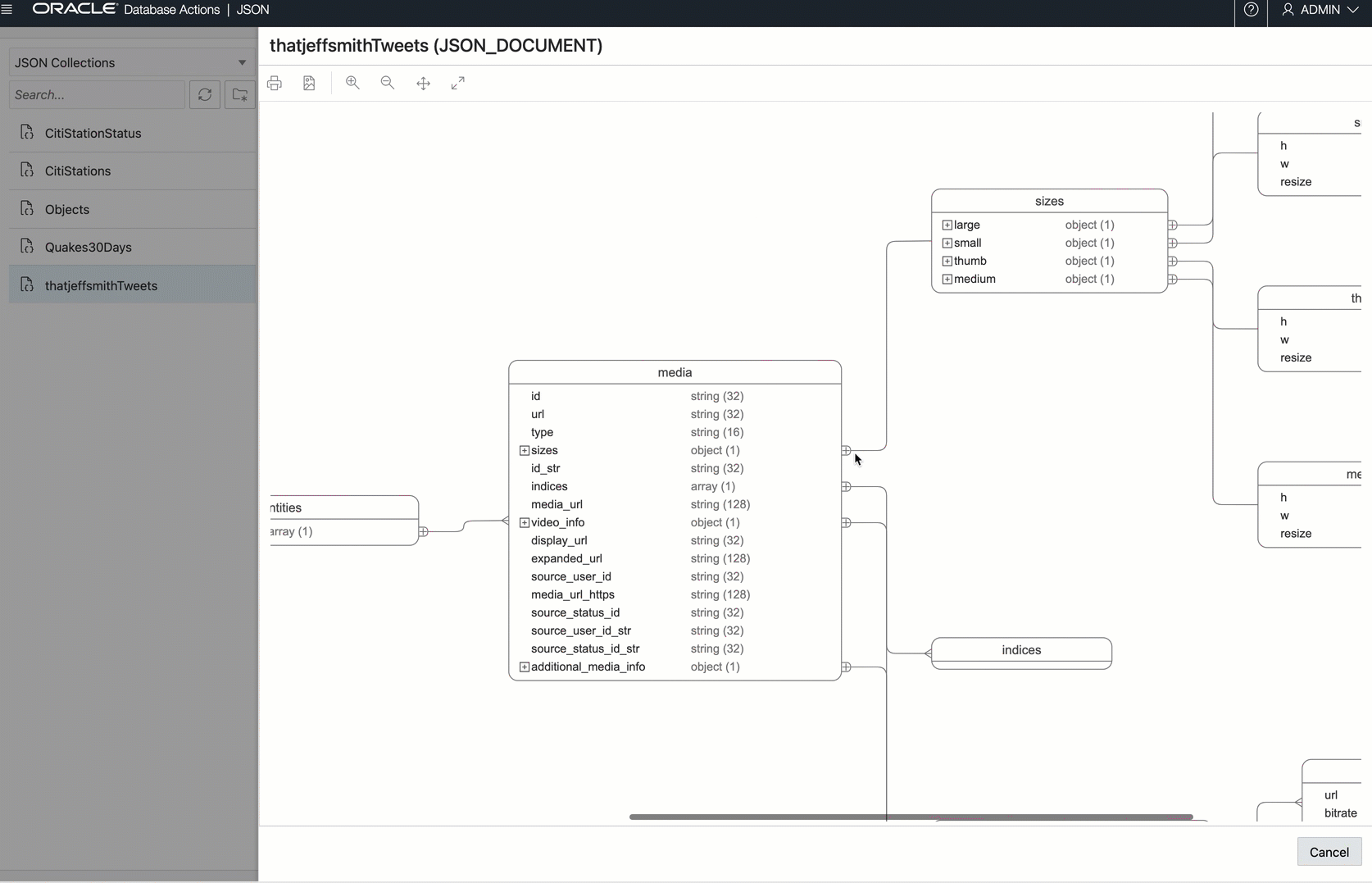
And if we wanted a JSON Data Guide ‘schema’ diagram…this is how Twitter sees how our tweets:
And maybe a quick query?
Let’s see, tweets with at least 30 RTs (that’s retweets, where someone shares your tweet as their tweet)