

There’s a lot to talk about with this release, but most of that will get drowned out by the news that you can now use the popular GraphQL query and manipulation language or API for your Oracle Database.
This post is a GraphQL for Oracle Database using ORDS 23.3 TEASER.
One of the primary benefits of GraphQL is the ability to ask for exactly what you want from a resource server.
If I were to say, use a REST API to get an employee…
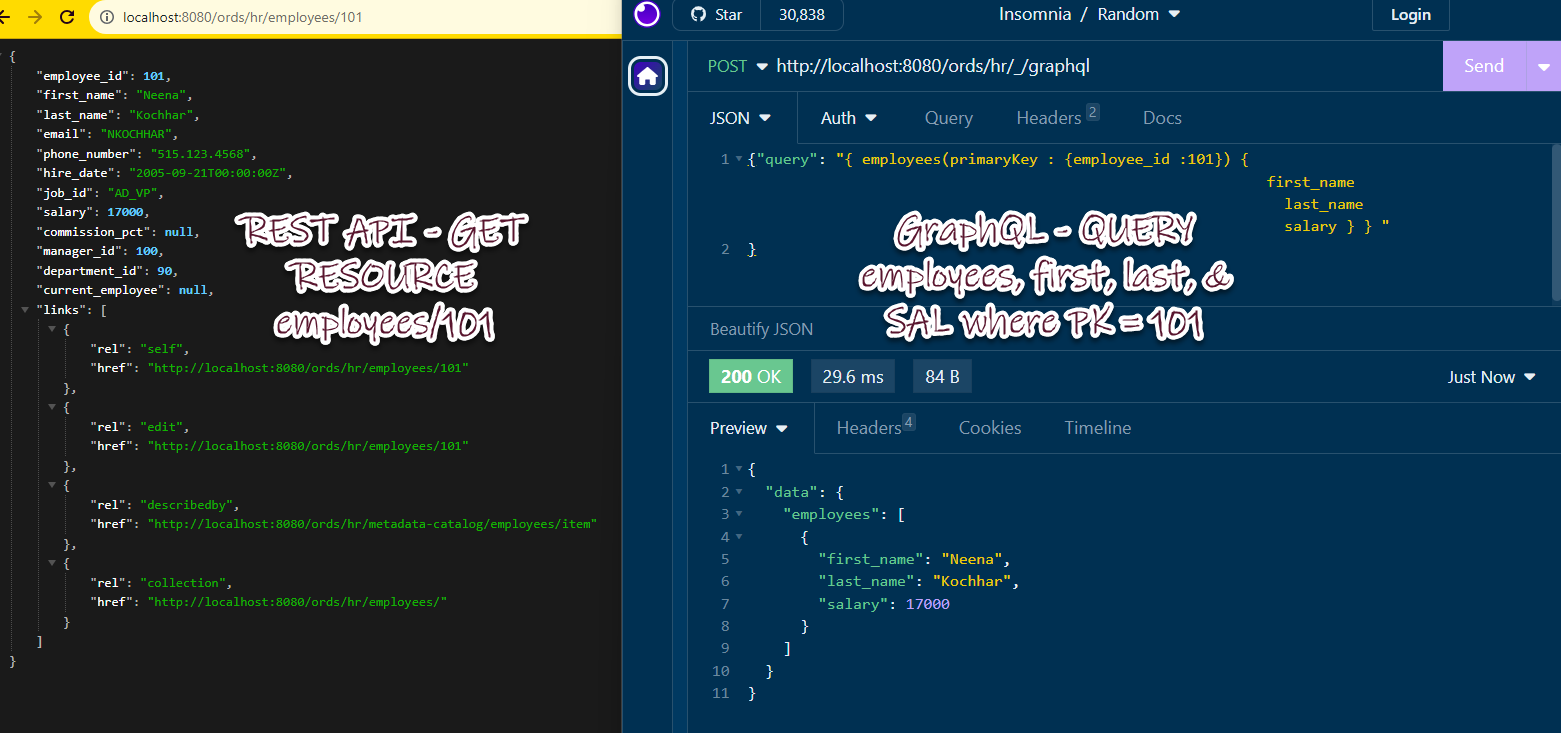
My REST API is a GET on employees/101 where the GraphQL request is a POST to the graphql endpoint served by ORDS, and attached is the ‘query I want to run.’
I don’t want all the attributes of my employee JSON object, i just want their name and salary. GraphQL queries allow for this.
Example, nested queries with the included GraphiQL editor
Bookmark this -> ORDS 23.3 GraphQL Docs / Query Examples
ORDS ships with a GraphQL editor for working with your schemas and queries, it’s available at
server:port/ords/<schema>/_/graphiql/ Maybe I don’t just want an employee. Perhaps I want 5 employees from each department, listed with the department name, from each location, including the location’s city attribute.
I can now do this in a single request or query!
Additionally our new GraphiQL editor makes it easier, complete with insight/tab completion on the keywords and identifiers and the schemas inventoried as well.
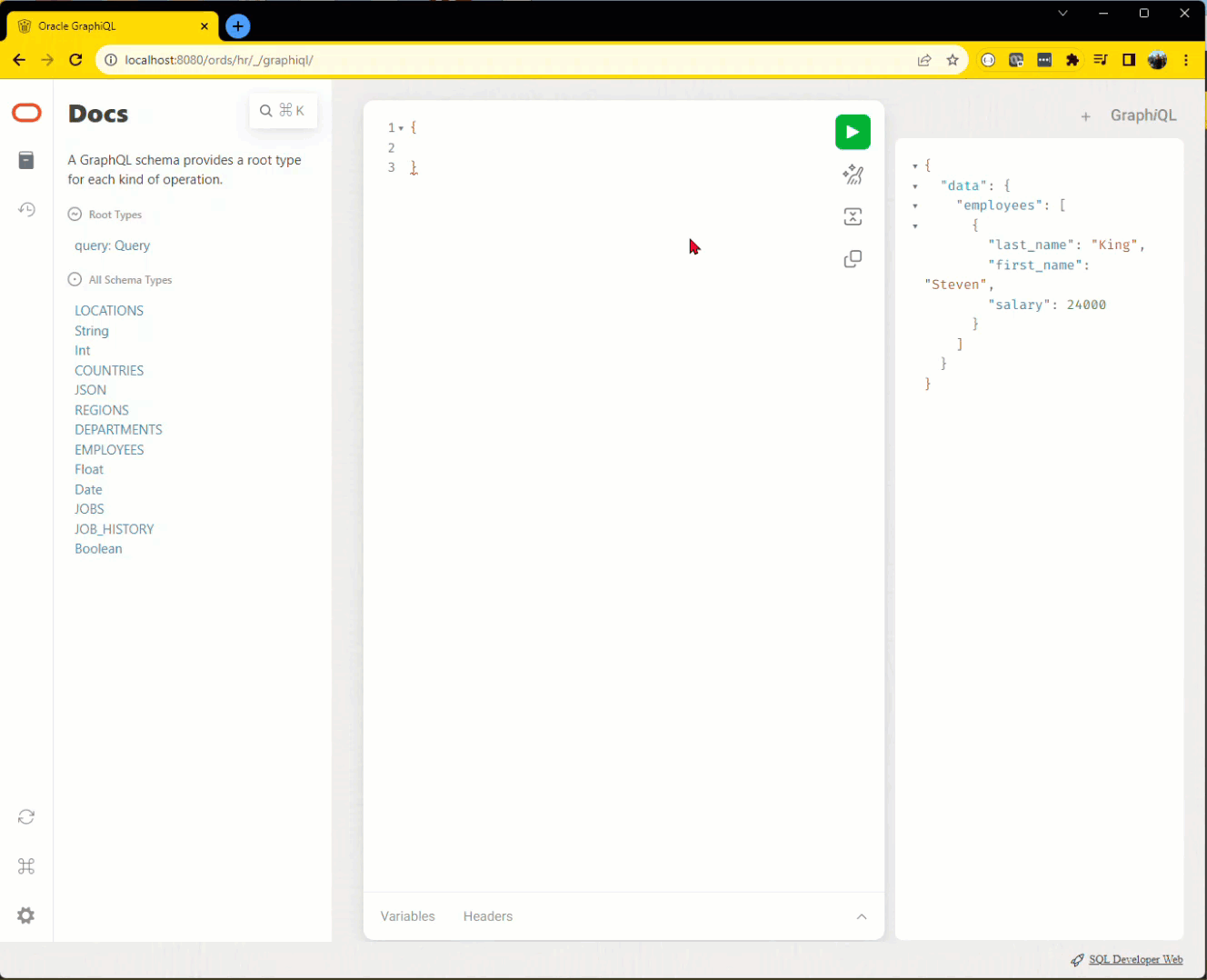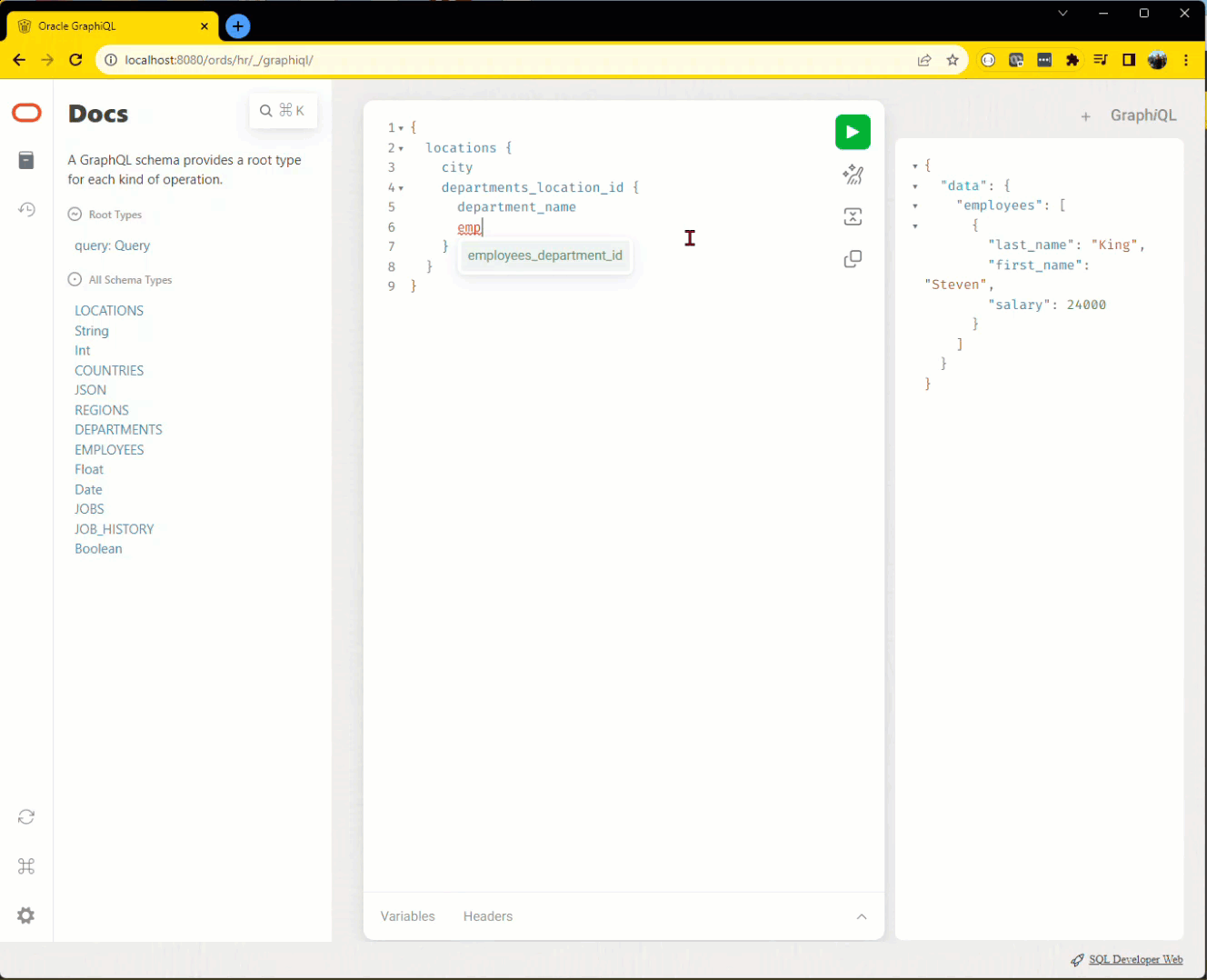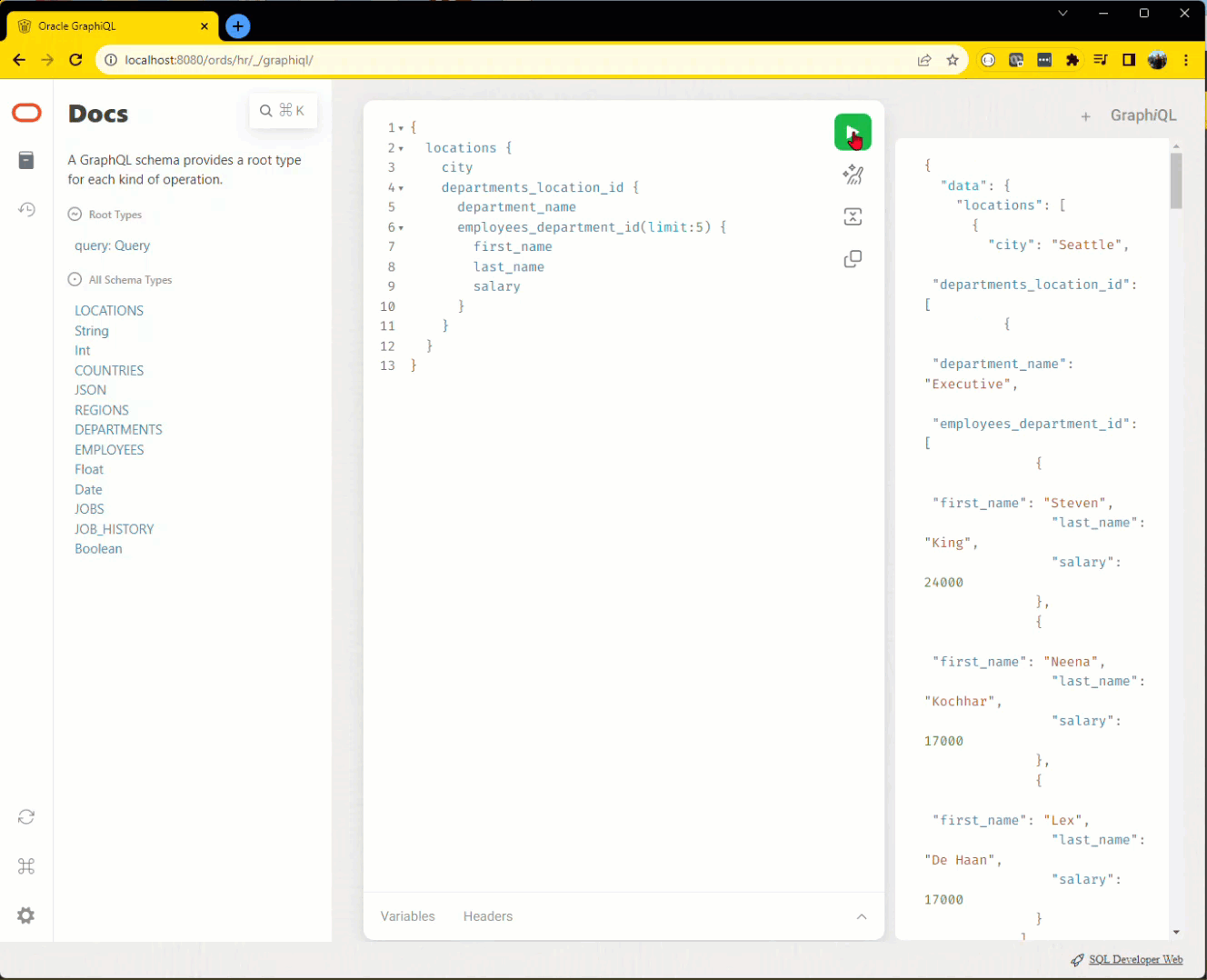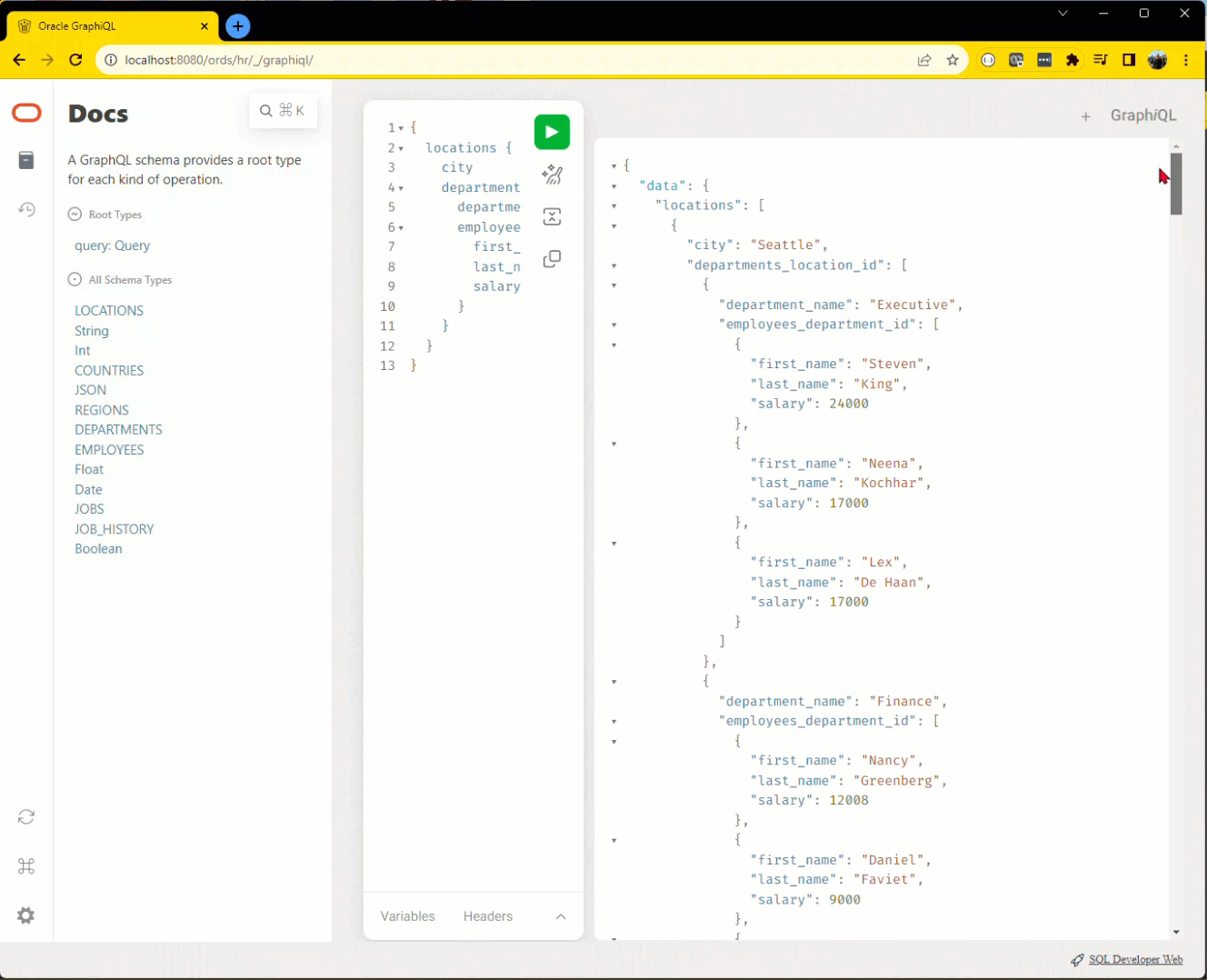
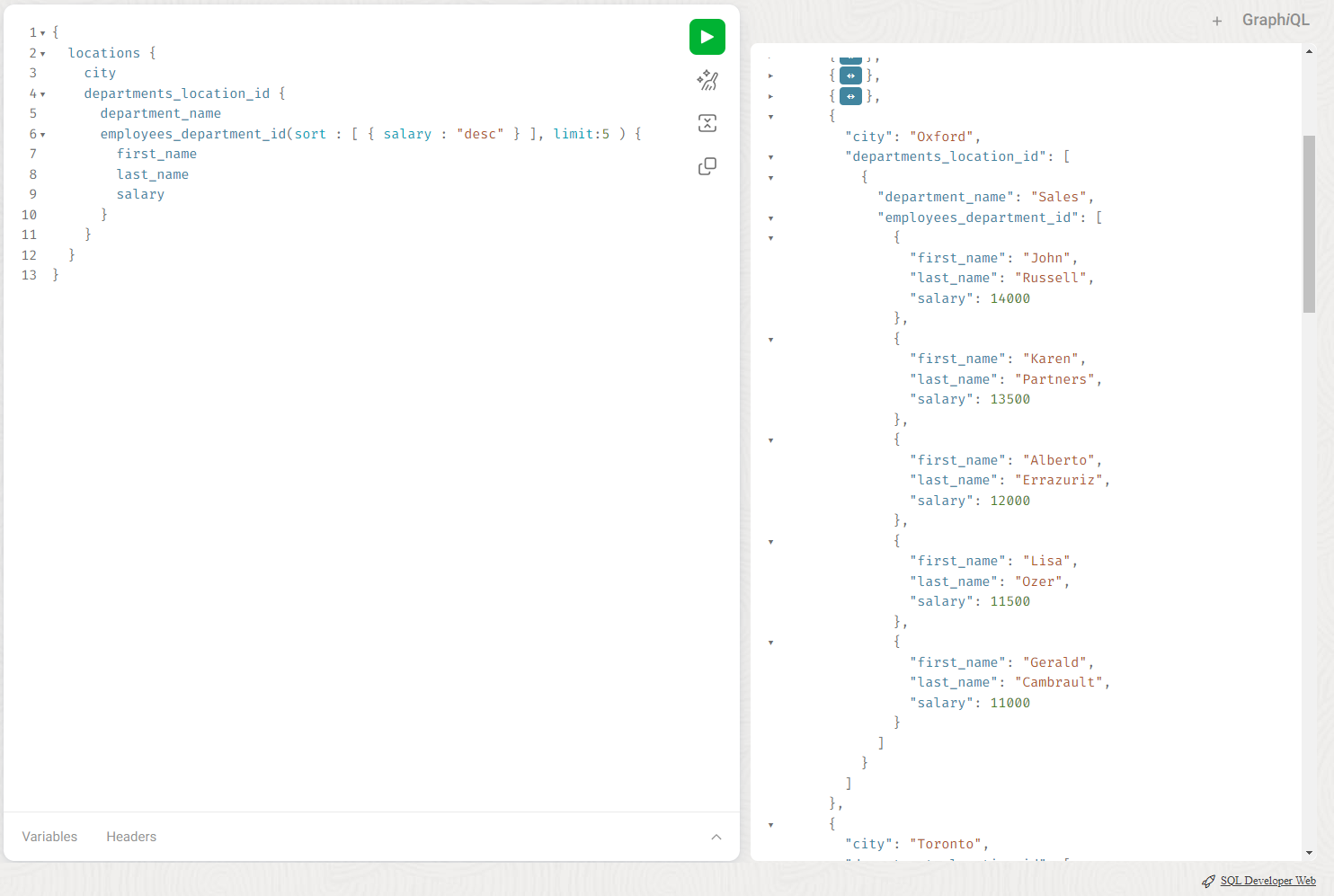
That would be MORE interesting if it were the top 5 paid employees in each department by location…sorted by salary DESC.
The GraphQL query becomes –
{
locations {
city
departments_location_id {
department_name
employees_department_id(sort : [ { salary : "desc" } ], limit:5 ) {
first_name
last_name
salary
}
}
}
}
What you need to know
1. Requires ORDS 23.3 or higher
Hopefully that part’s pretty straightforward.
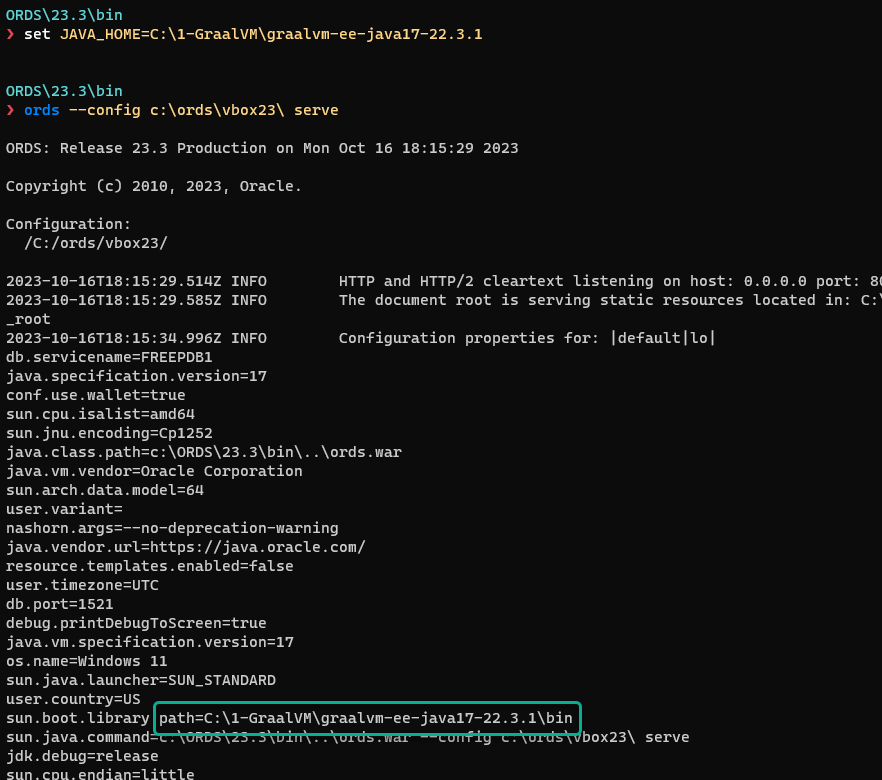
2. You need to run ORDS with the GraalVM 17 JDK with JavaScript support
We need the JavaScript support because we’re using JavaScript library to do some of the GraphQL magic. I show how to set that up for SQLcl here.
I do this by setting Java_Home and then starting ORDS…
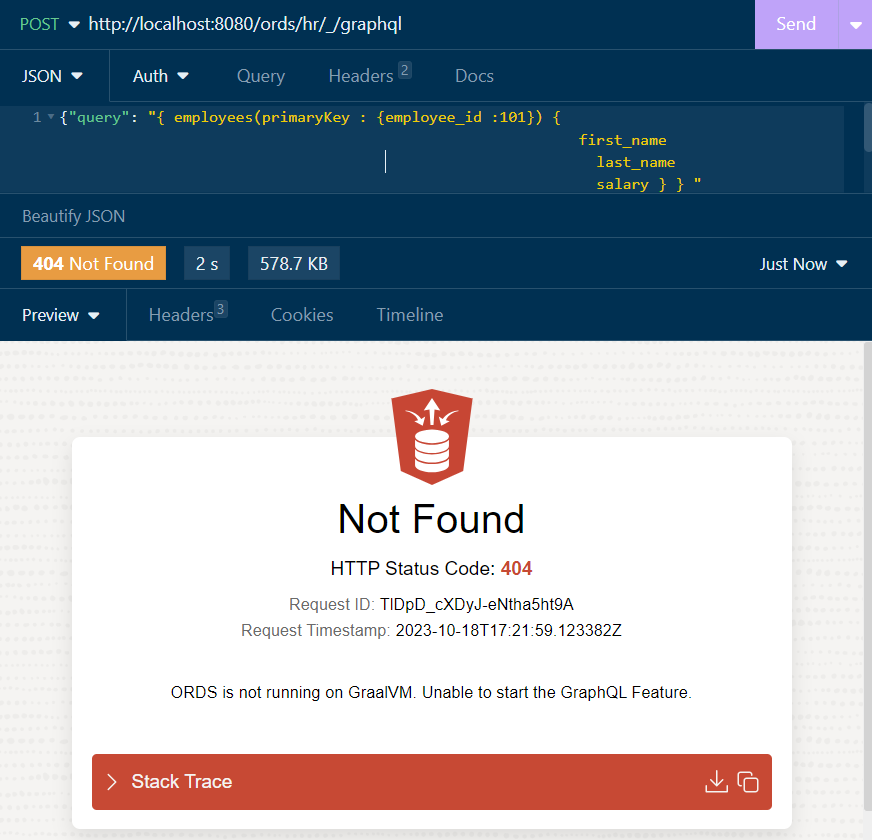
If you start this up with just an ordinary JVM, you’ll see then when you go to try a GraphQL -query –
“ORDS is not running on GraalVM. Unable to start the GraphQL Feature”
3. Requires an ORDS enabled SCHEMA.
I’m using HR, so I had to do this –
BEGIN
ORDS.ENABLE_SCHEMA(p_enabled => TRUE,
p_schema => 'HR',
);
END;
/4. Relies on one or more ORDS enabled TABLEs or VIEWs.
We’ll go query stuff, if you’ve given ORDS access to work with those objects.
5. The GraphQL Schema definition is computed and then CACHED
So I created a table called ‘TEST_CACHE2,’ and I REST Enabled it, but even after hitting the ‘re-fetch GraphQL schema’ button, I’m not seeing my table?
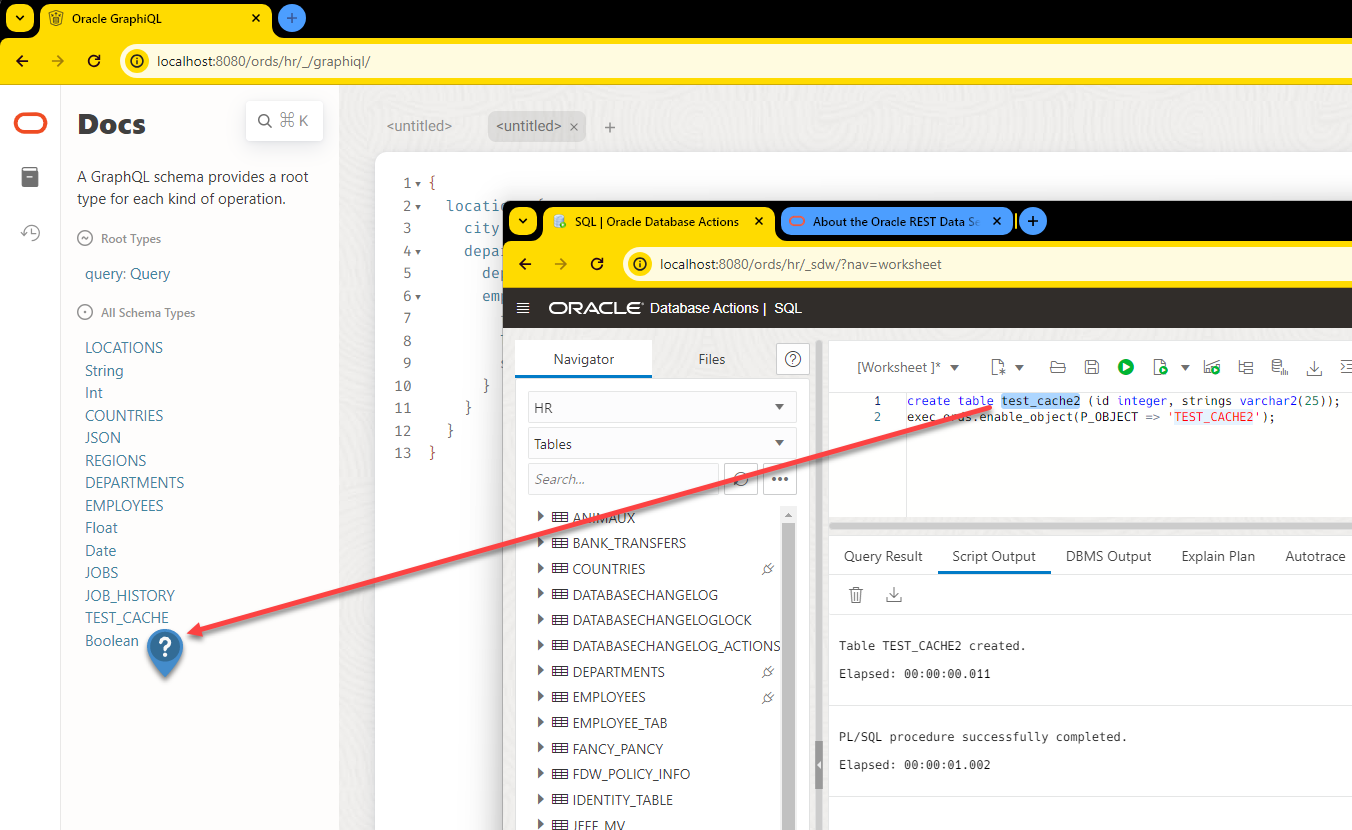
Once you startup ORDS and then make a GraphQL query, ORDS will ‘compute’ the schema mapping, by looking at the tables and views enabled, and any foreign key constraints you have defined.
This can be quite expensive, especially for large schemas, so we do it ONCE, then it’s cached, for 8 or 24 hours.
Meaning, once the schema is ‘loaded,’ if you make any changes to the schema, it could be awhile before those are honored by your queries.
This cache lifetime is defined by 2 different ORDS config parameters.

So let’s kill ORDS, and add our configuration setting, something that’s ‘OK’ for my development instance.
I’m adding this line to my POOL config –
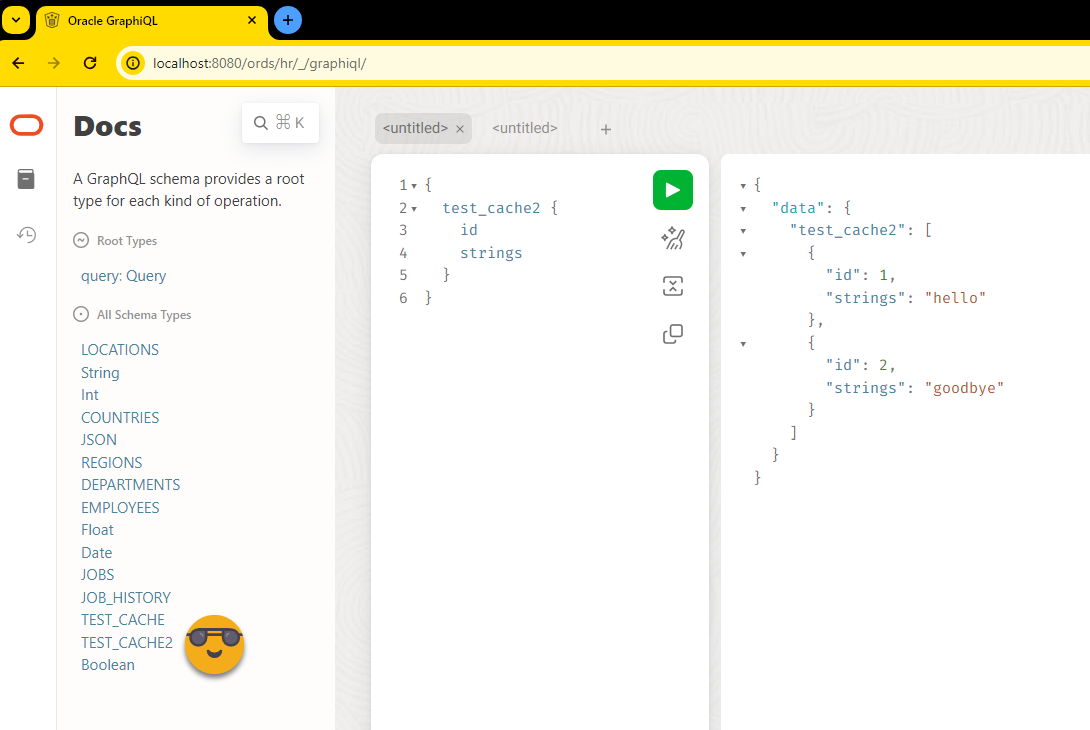
<entry key="cache.metadata.graphql.expireAfterWrite">2m</entry>I can now re-start ORDS, create a new table, REST Enable it, wait 2 minutes, try to query it, and it now appears in the schema after another re-fetch!
5. This is effectively our ‘version 1’ for GraphQL
There are lots of features GraphQL provides, but if you have read this blog or our docs, you can see we’ve left it at the ‘queries’ feature. We’ll be taking community feedback on what you like, don’t like, would like to see more of, and we’ll plan improvements/feature development based on that feedback.
6. Where is the REST vs GraphQL post, Jeff?
There are lots of those out there. I’m not here to pick winners. We have both REST APIs and GraphQL (queries) for you to take advantage for an Oracle Database now. Use what works best for you.
But, if you have a page that loads many different resources, and you’d like to make a single request to get a ‘customer’ response, then the GraphQL query feature is definitely worth checking out!




4 Comments
Hi jeff,
Will they give backend access to autonomous database to create custom schemas.
Thank you
‘Backend access?’
Everything but the APEX service includes SQLNet access – direct connectivity to the database. If you’re using the APEX service, you only have access to the APEX and SQL Developer Web interfaces.
Hello jeff,
We have legacy custom application in onpremise. We are planning to migrate to OCI.
What is the difference between Oracle autonomous database and oracle base database service. We have to host custom applications and develop new application as well.
Thanks,
Sridevi
Too many differences to answer in a blog post comment. Start your research here, and if you have a specific question, I’ll to help.