

Updated 11 September 2023
REST APIs can be useful, and even fun to build.
Imagine an interface that would allow you to get a list of all the items in your collection.
Now that’s awfully vague, so let’s use our imagination a bit.
- all of the employees in our company
- all of the beers in my Untappd diary
- all of the objects in our database
- all of the songs in our iTunes library
Hopefully for the scenario YOU have imagined, it’s a ‘big’ collection. Big enough, that you wouldn’t want to get everything, all in one go.
Imagine accessing this API from your mobile phone, on a fast moving train, hopping cell towers or god forbid using the free WiFi, and having to wait for the response payload of like 150,000 employees?
That would NOT be fun.
So a common pattern is to instead PAGE the results. You get the first X records, with links to traverse the collection.
Are there MORE records? If so, provide a link.
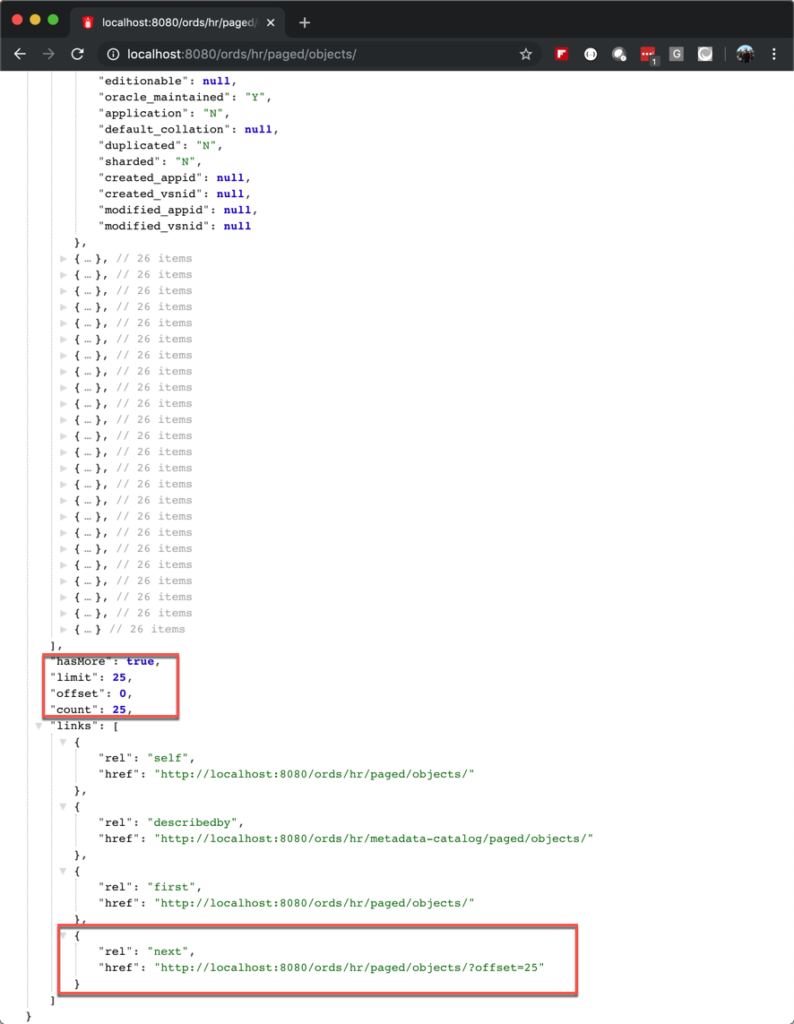
So how does ORDS make this happen?
When I define my GET handler, I’m giving it a SQL statement. And I’m also saying, hey, I want this to be a collection, AND I want my pagesize to be X (in this case, 25).
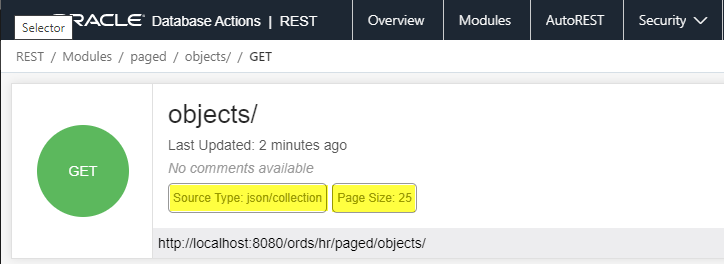
Now, this service is powered by a SQL statement.
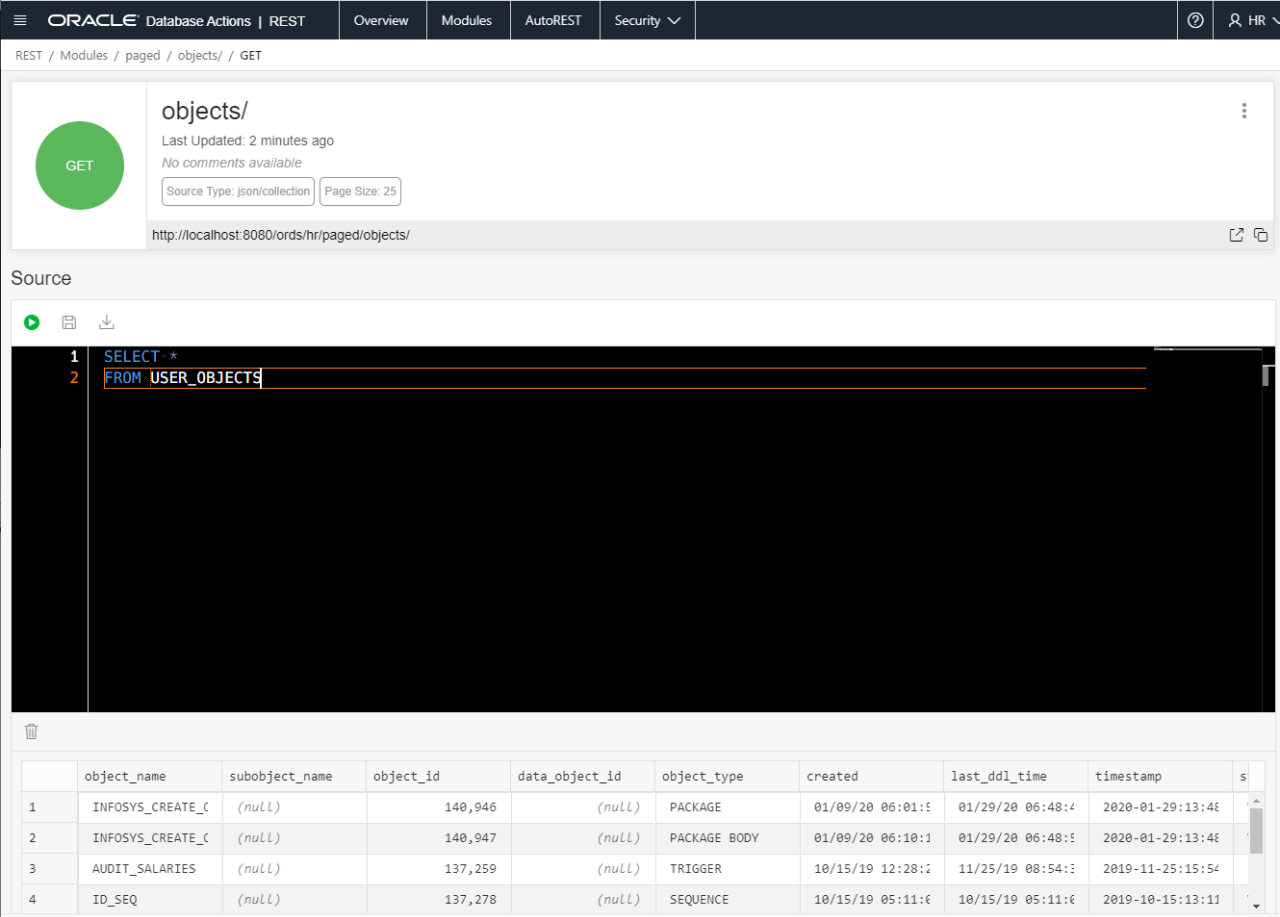
SELECT * FROM ALL_OBJECTS
Wait, that’s going to bring back a TON of stuff. How is ORDS going to page the results?
Do we…like do a fetch, hold onto the process/query, and do more fetches later if necessary?
Do we…get ALL the data on the mid tier, cache it or something, and dole it out as necessary?
NO.
We use the power of analytic functions!
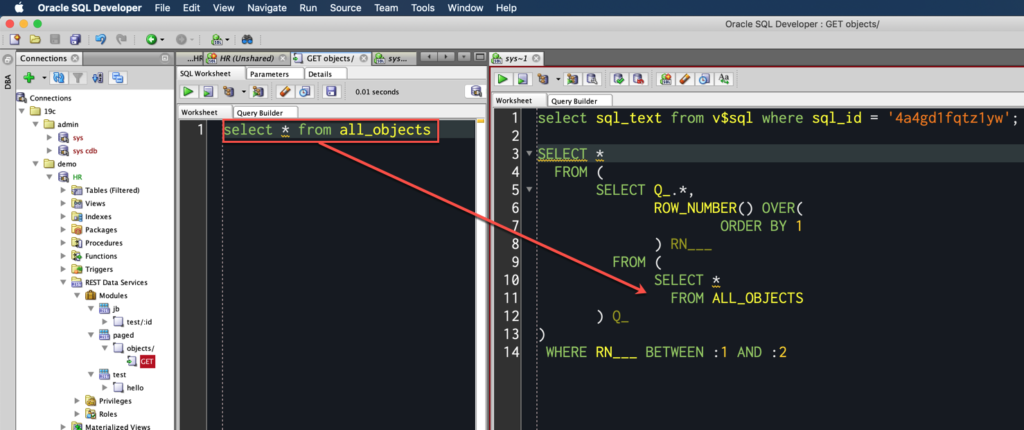
This is what we actually run.
SELECT * FROM ( SELECT Q_.*, ROW_NUMBER() OVER( ORDER BY 1 ) RN___ FROM ( SELECT * FROM ALL_OBJECTS ) Q_ ) WHERE RN___ BETWEEN :1 AND :2
ROW_NUMBER (Docs)
This makes paging the query results very easy.
By nesting a subquery using
Oracle DocsROW_NUMBERinside a query that retrieves theROW_NUMBERvalues for a specified range, you can find a precise subset of rows from the results of the inner query. This use of the function lets you implement top-N, bottom-N, and inner-N reporting.
What we do, if your pagesize is 25, we actually try to get 26 records. If that 26th row is there, we return the 25 records, and then we KNOW there is at least one more page. If there’s NOT that 25th row, then we know we’re done, and there’s no link for the next page.
So what does this mean, for me?
- You provide the base query, ORDS handles the paging.
- EACH request you make, results in the query being executed, again.
- The bigger the pagesize, the more resources you’re going to consume.
- You have to mind your CURSOR expressions, else…
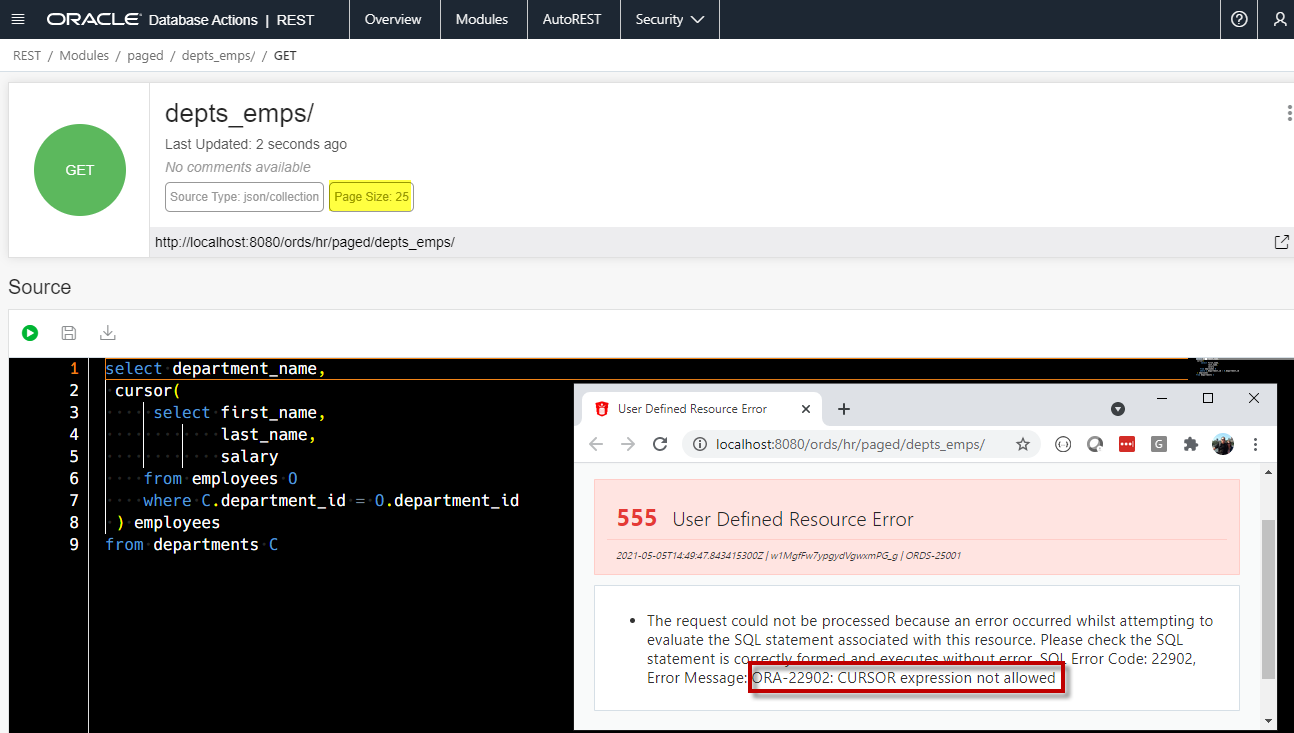
Note I have DEBUG and PRINT TO SCREEN enabled for my local ORDS, so I get to see the stack trace on my 5xx screen.
The solution? Disable paging…
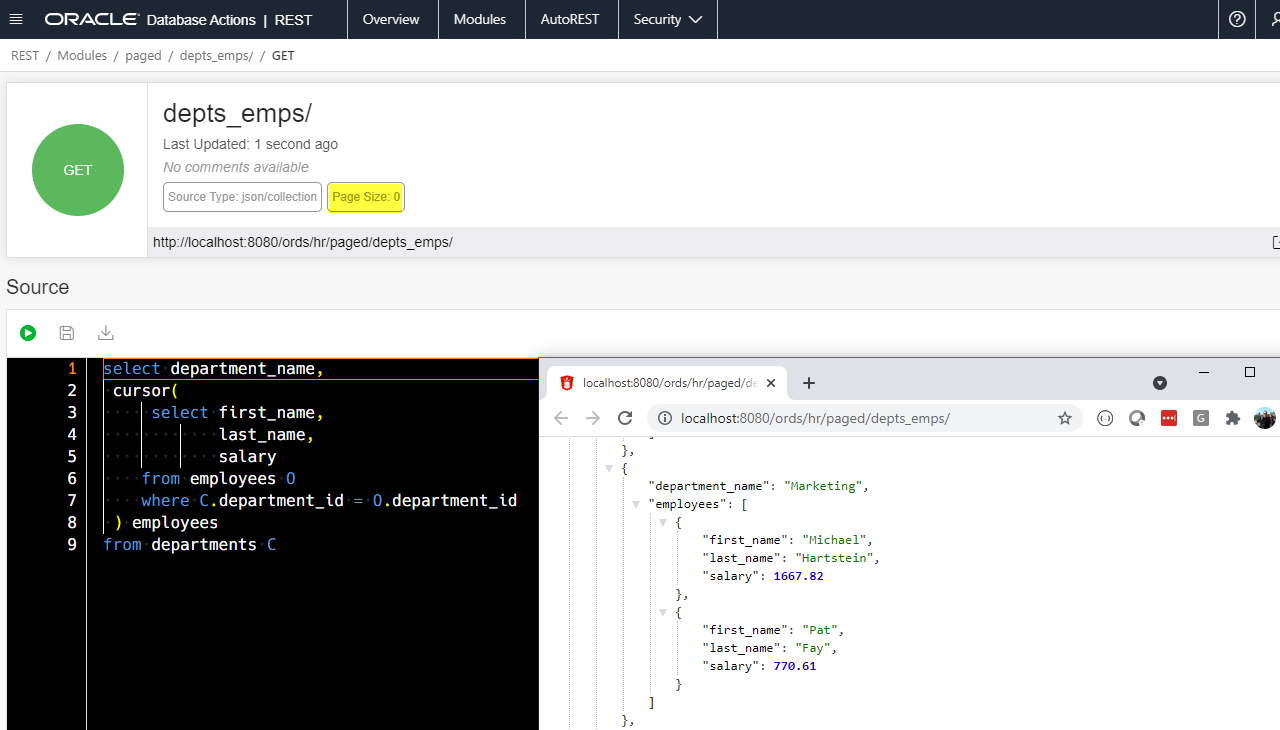
Want a complete demo of building a CURSOR based SQL GET Handler? I have the code and steps here on StackOverflow.
What about PL/SQL?
Let’s say you have a stored procedure back ending your REST API, and said PL/SQL returns a LOT of data via a REF Cursor. I want to page that!
Well, you get to write some more code, as ORDS does not provide a mechanism to auto-page your REFCURSORs.
Thankfully, there are many folks in the community that have shared how to do this.
And how does this apply to SQL Developer Web?
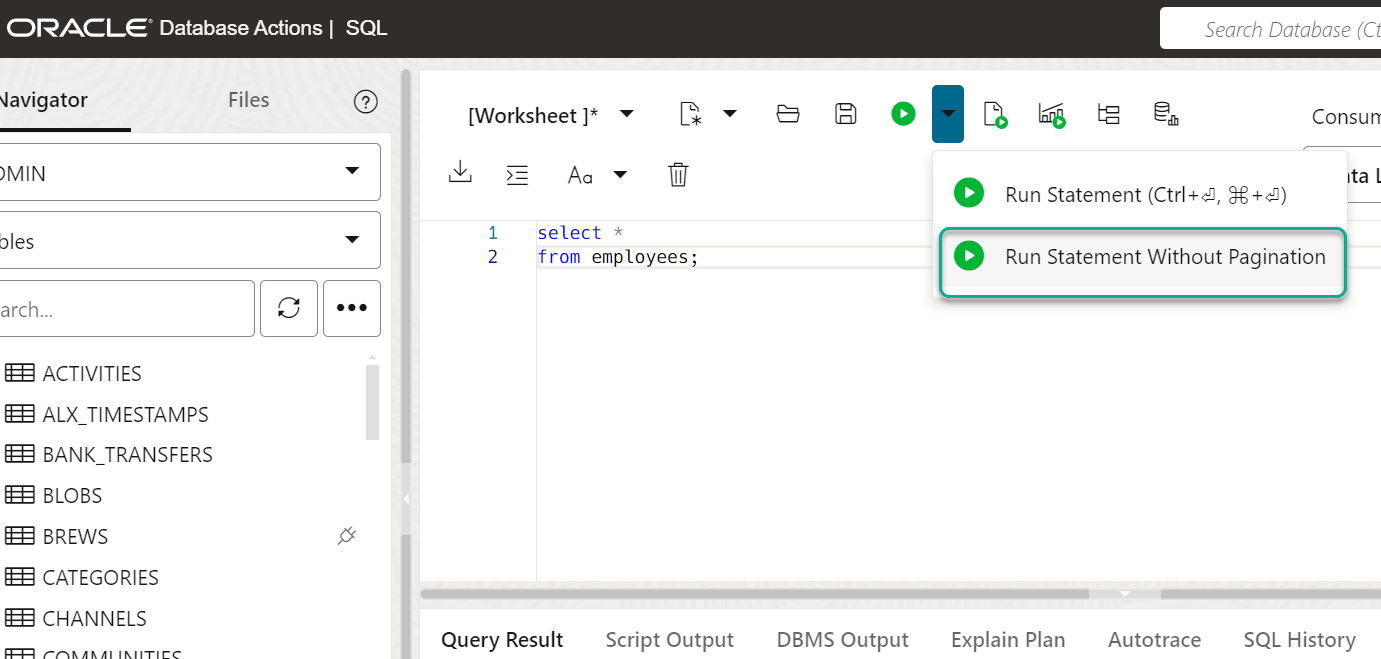
By default, running SQL through ORDS via the REST Enabled SQL endpoint, runs WITH PAGINATION.
That means we don’t run ‘select * from employees’ but instead the analytic function wrapped version of the SQL as shown above.
In the latest versions of ORDS and SQL Developer Web, we now also allow you to disable this paging feature.
So, that means you can run any query – you won’t be limited if using a CURSOR function or something else not compatible with the analytic function. However, if it returns MANY rows…we only fetch the first 256.
When invoking the REST SQL endpoint, we set the offset to ‘-1’, that tells ORDS not to invoke the pagination logic.
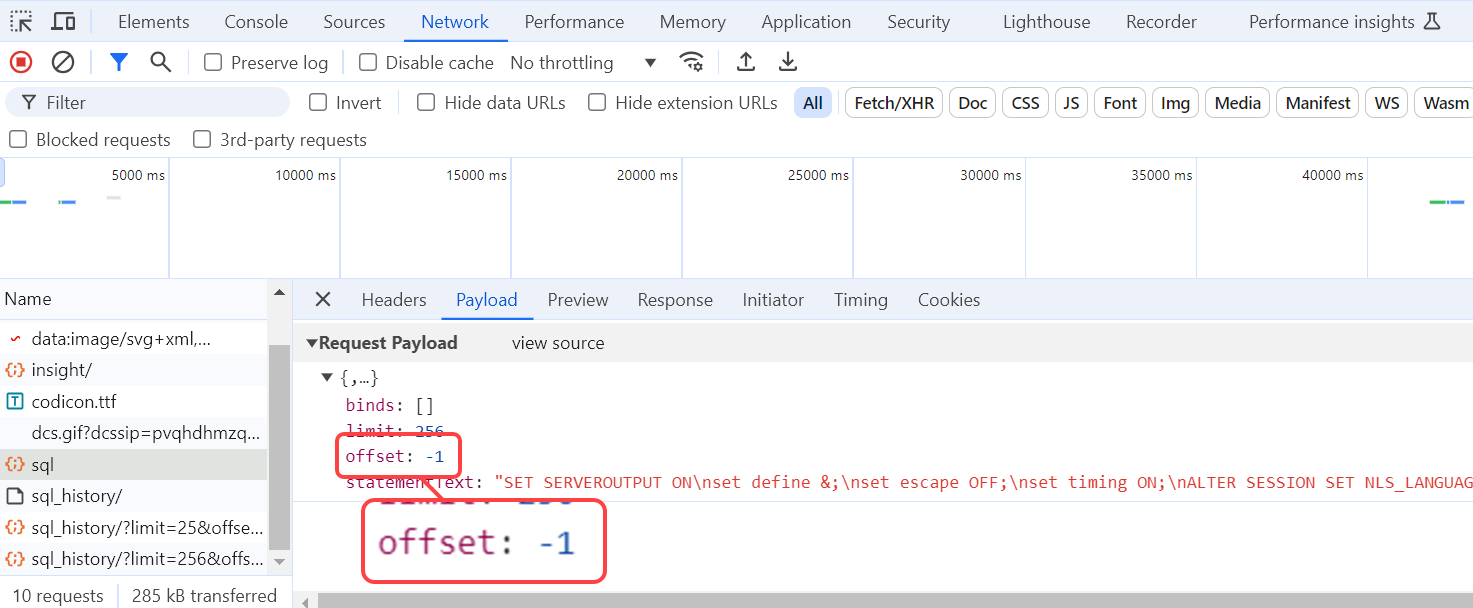
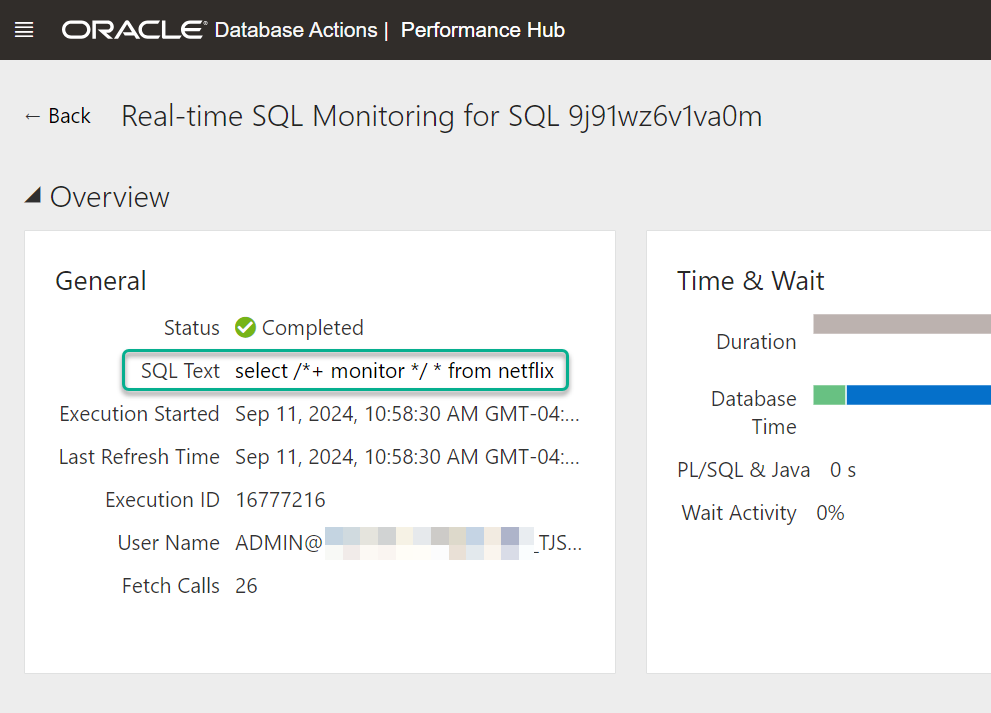
So when I run …
select /*+ monitor */ * from netflix;…and execute without pagination, ORDS receives the request with the offset header set to -1, and runs just that.
Which I confirm later by observing the SQL Monitoring report.




24 Comments
Hello, is it possible to turn off “link” section in the output. Thank you.
You don’t want paging? Set pagesize to 0.
Thanks for this explanation of the paging mechanism, it’s given me the solution to the paging bug I’ve been hunting for a couple of hours now. Just one more limitation of using CURSOR I guess. Part of the attraction of using ORDS for me has been returning nested JSON results containing several CURSOR statements in the base query. That way I can return not only the results of the master table, but arrays of the records from detail tables as well in one interface. It’s nice that you’ve deviated from the standard example of returning “all of the records in EMP” but any single table query is a pretty limiting example. Why not return all customers from the customer table, with an array of all invoices from the invoice table and a further sub array of all detail lines from the invoice line table. Oh, and since our example has 10,000 customers it would be nice to page that and maybe even use some filters.
Hey Jeff,
Is there anyway to change the default number of rows returned by “autorest”? Maybe a config parm in the setup of the server? If not, that would be a good feature to add! 🙂
You’d have to roll your own webservice..and then the pagsize is up to you!
Jeff, seems like it would be pretty simple to add a configuration variable to allow you to set the default of the “limit” used by autorest. Don’t you think this would be a good addition?
Sure…but you can roll a custom service in a few minutes and it’ll take us months if not longer to sort out your ER.
This is a no-brainer and it *has* to be an easy implementation. Sure, I can write more code, but the draw of ORDS is NOT having to write code. If you have tons of tables that you want to autorest, this is a pain.
We’ll just pass a default limit file of 1,000,000 from our angular application but seems like such an obvious thing to add (and I know you’ve gotten this question many times) I don’t know why you just don’t add it.
Just not that hard. You’re already setting it to 25 every time.
Actually I think you’re the first to ask this particular one. I’ll definitely add it to the list.
How many tables is ‘tons’ and what would your ideal limit size look like?
25 is subjective, so it’s not crazy to ask for an option.
Tons: 20-30 is more than enough to not want to write code. If you ask me, more than one means I don’t want to write code. The really cool thing about ORDS isn’t the modules. That’s the least useful part (although perhaps necessary). The useful part is just having things work that you already have and not have to write code.
Limit size: I think 25 is fine as a default, Although, I think Sql Dev uses 50. Maybe you should be consistent?
You may not have gotten the question about setting a default, but I’ve seen posts on the forum and stackoverflow that you’ve replied to that have touched upon the same issue.
So you’re using AutoREST for about 30 tables, and you’d be happy if you could default it to 50 vs 25?
I’ve put in your ER for formal tracking. The more you can share on how you’re using this feature, and how a larger pagesize would help you will assist in me prioritizing the request for ORDS 20.3!
Hi Jeff,
Thanks for entering. What’s the number? I’ll check it out.
So, to be clear, I’d like it to be a parameter in the default.xml file. Just changing to 50 doesn’t help all that much. It would be great to be able to set to a specific value or to “get all” (probably by setting to 0).
I will certainly comment on the request. I’m not exactly sure how to get there. Can you share a URL with me?
Thanks so much.
So you just don’t want any paging, ever? What if your table has 1m rows?
So, if you set your default to 0 in the default.xml file, you probably don’t have big tables or, if you have one big table, then you’ll set the limit in your autorest call when accessing that particular table. You have control of your default and for a particular table. If I need to page I can either do that with ORDS, or, if the table or returned results are small enough, I can use my application to page from memory and only do one network call.
If a different ords instance has lots of big tables like in a data warehouse, then they would set the default.xml value to be something smaller and make it larger when required.
If we have the ability to set the default value on our own and then use the limit parm to change when necessary for my application then I have the best of both worlds!
So, I’m not saying to change anything in the way ORDS currently words per se, I just want to be able to change the “arbitrary” 25 rows to whatever I want.
Does that make sense?
Got it, thanks!
Users writing their own queries, and who know they are working with Oracle DB 12.1 or later, might find it easier to use the 12c OFFSET / FETCH NEXT syntax, e.g.
SELECT employee_id, last_name
FROM employees
ORDER BY employee_id
OFFSET 5 ROWS FETCH NEXT 5 ROWS ONLY;
Hi Jeff,
Is there a way to get the last page with ORDS (or the total count of the query WITH filters applied) ?
ORDS gives only the “next”, and sometimes there i a need to navigate through the list with page’s numbers.
I tried to insert the count in the query, but filters are applied after, meaning the count corresponds to data without filters.
Regards,
We never do a rowcount. We only grab a specific range of rows, never knowing if it’s the last page until we’ve grabbed it and see there are no rows coming ‘next.’ Turn off paging if you want to do something like append the rowcount. Or use a stored procedure, but you’ll have to write your own paging scheme.
Thanks for the answer Jeff
I took the stored procedure route, because i need to apply my filters before the count, and ORDS doesn’t seem to be capable to do it in that order.
Is there a way to submit something to the team developing ORDS, to be able to get this kind of information if needed ?
It seems to me that this is a pretty basic information for pagination to have the total count to display the final page at the bottom of a table for example.
Even when running queries in oracle, there’s no way to get the row count. When you ask for a row count in SQL Developer for a query, we actually run another query to find out.
Hi Jeff,
Thanks for this information. It is of great help to me as I am in a project where I need to implement pagination for a couple of rest services. All of them are built on top of a pretty generic pl/sql process handling e.g. parameter validation, output format, ….
Would you also happen to know how ORDS “extracts” the typical information at the bottom of a “paginated” response? I am especially interested in the hasmore-element as this is the basis for e.g. the next relation link. I assume ORDS somehow gets the total count and compares this to the offset + limit. But does this mean ORDS fires the same query twice, a first time for the results (as explained in your article) and a second time for the count, or is he able to do this in one run?
Thanks for your input.
Rgds,
Mike
No, if paging is set to 25, we get 26 or 27…if they’re there, we know there’s a next page.
We never do a count, as that’s sometimes just as expensive as running the query.
Why not just implement count of the filtered resultset using something like this?
SELECT *
FROM (SELECT Q_.*,
COUNT(*) OVER () CNT___,
ROW_NUMBER() OVER (ORDER BY ROWNUM) RN___
FROM (SELECT *
FROM ALL_OBJECTS
WHERE — url query filter predicate here
OWNER = ‘XDB’
) Q_
)
WHERE RN___ BETWEEN :1 AND :2
I liked oracles developers