

Updated 28 June 2022
Got this question from a friend:
I created a new schema (API) and within that schema a view based upon a table…like
create view my_data as select * from hr.data
I REST enabled my API schema.
I REST enabled my_data viewCalling /ords/api/my_data/1 returns a 500
A Friend on Twitter or Slack or Email or Postcard, I can’t remember now.
And my reply was, it’s a bug.
But unfortunately, my reply was buggy.
The real answer is…
Your VIEW needs a Primary Key
Not all VIEWs are based on tables such that you can assume there is a primary key available. So what we do is if YOU provide us a PK on your view explicitly, we’ll support it. If there’s no PK available on the VIEW directly, we fall back to using ROWIDs, just like we do for TABLEs.
Let’s take a look at a concrete example.
A VIEW sans PK
I have a TABLE called STRAVA, it has my exercise activity data. And I’ve created a view on this table, that let’s me pull up anything in that table that’s NOT based on running activities.
My view…
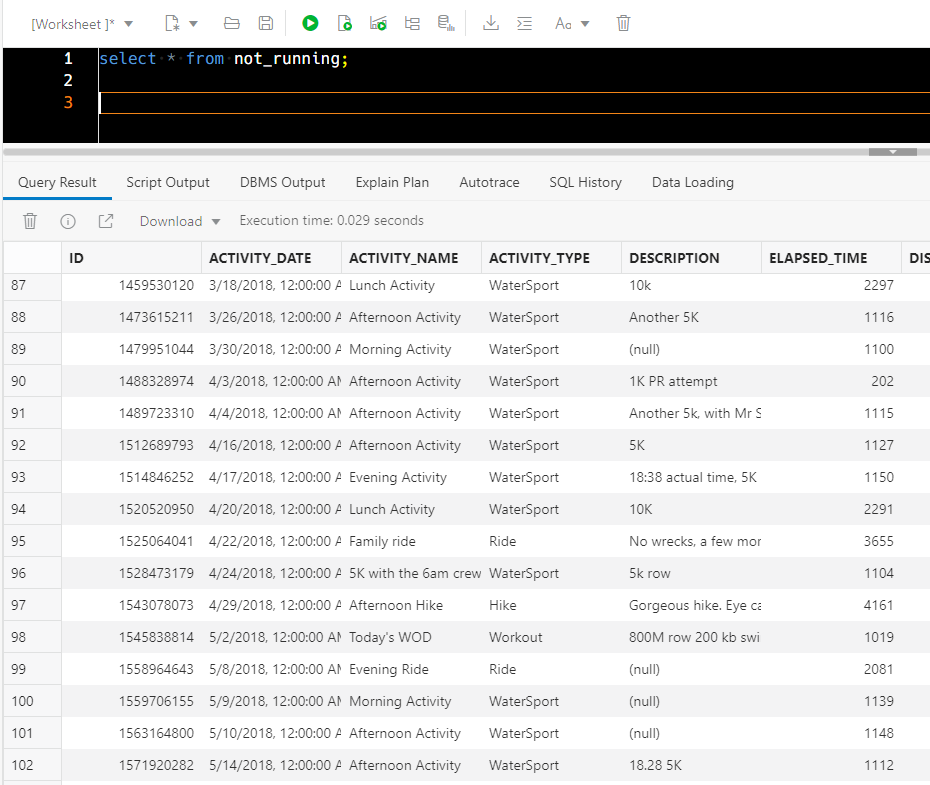
CREATE VIEW ADMIN.NOT_RUNNING ( ID, ACTIVITY_DATE, ACTIVITY_NAME, ACTIVITY_TYPE, DESCRIPTION, ELAPSED_TIME, DISTANCE, COMMUTE, GEAR, FILENAME ) AS
select *
from activities
where ACTIVITY_TYPE <> 'Run'
;Which looks like this –
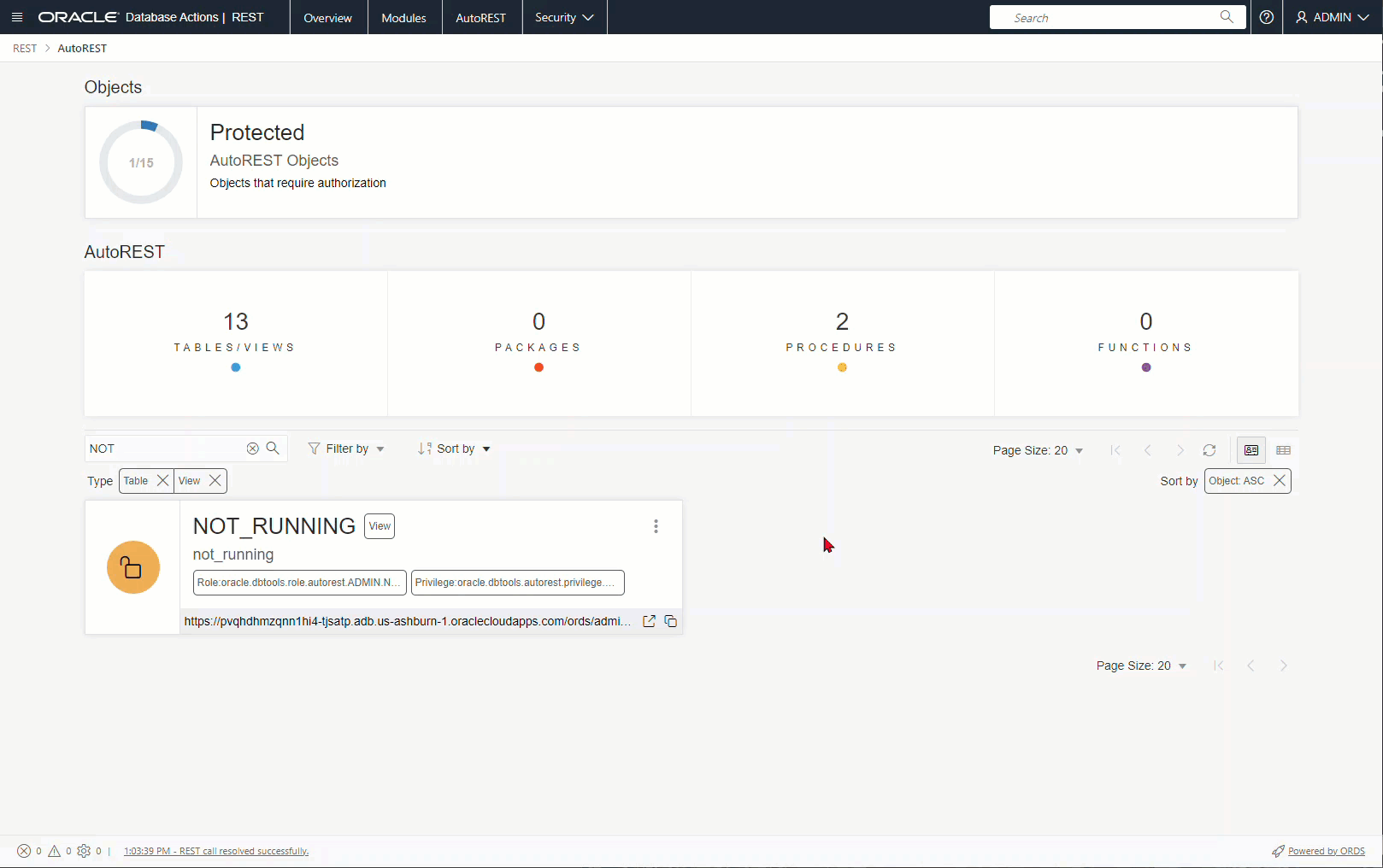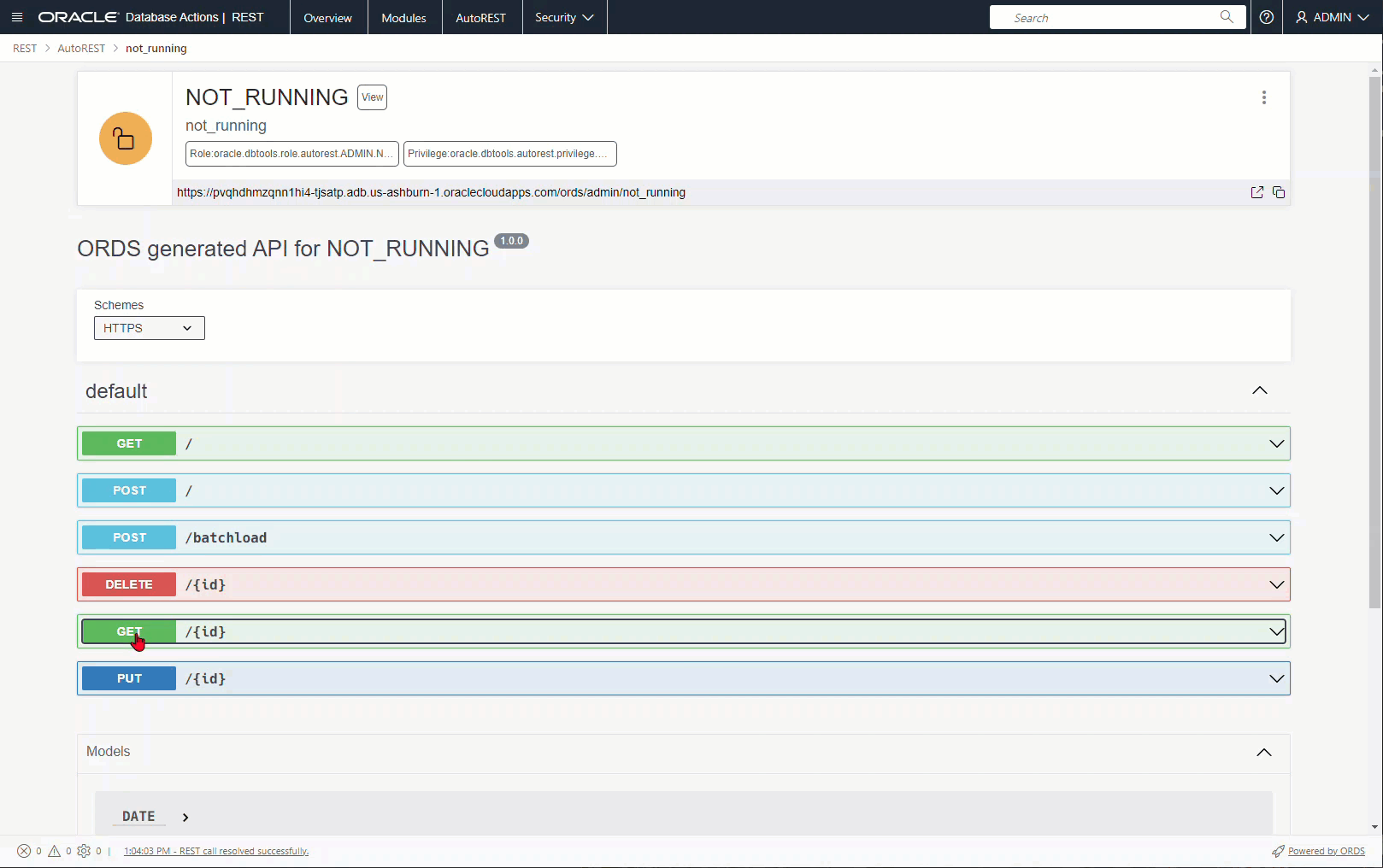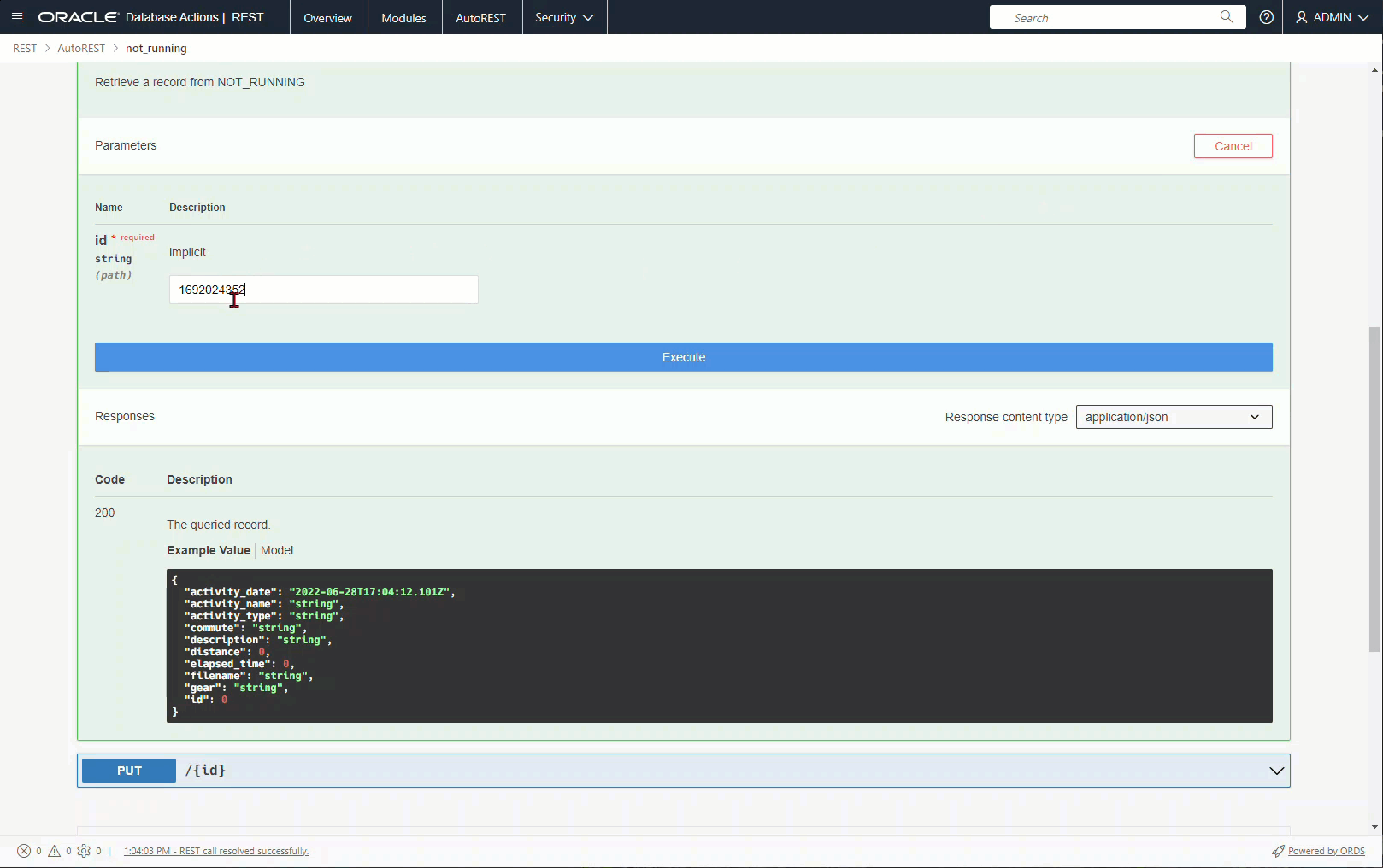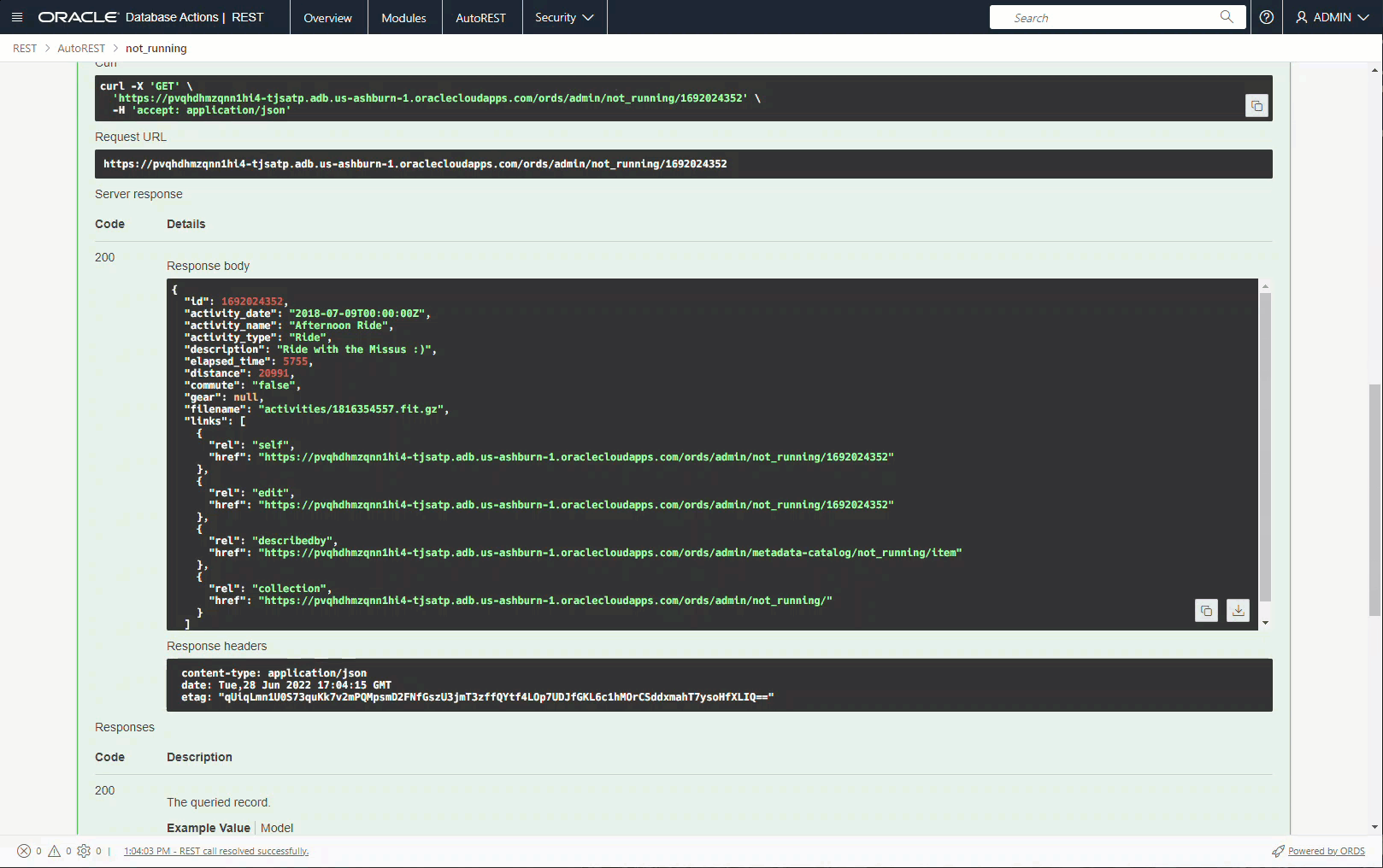
With our VIEW created, let’s now REST Enable it – and the following single API call, gives us a ton of ORDS features for FREE (no custom handler coding):
BEGIN ORDS.ENABLE_OBJECT( p_enabled => TRUE, p_schema => 'ADMIN', p_object => 'NOT_RUNNING', p_object_type => 'VIEW', -- A VIEW! p_object_alias => 'not_running', p_auto_rest_auth => FALSE); COMMIT; END;
With my VIEW created, let’s try to pull up a record by the underlying TABLE’s PK, the ACTIVITY_ID
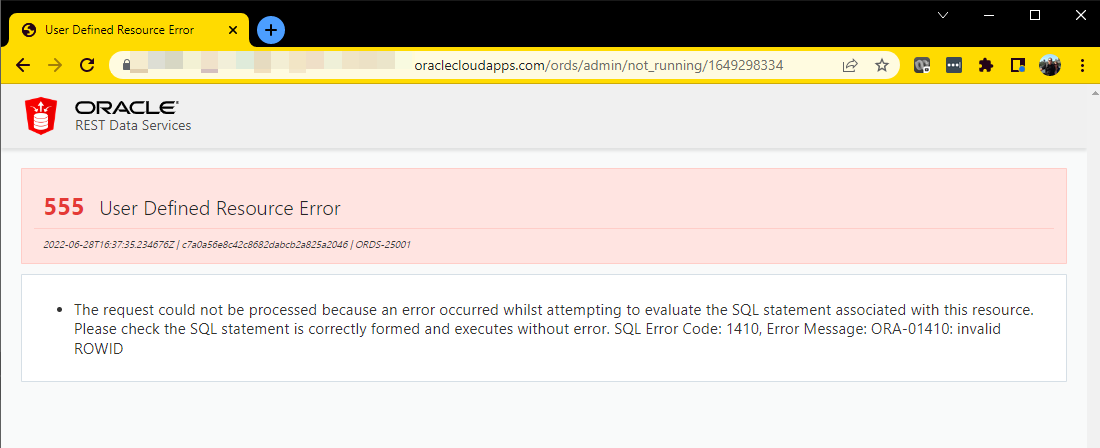
Yes, you can have a VIEW with a PRIMARY KEY
The constraint is disabled…
The PK won’t prevent duplicates on the view, but it will tell the database about my data model. And when the database knows, so does ORDS when it comes to AUTOREST objects.
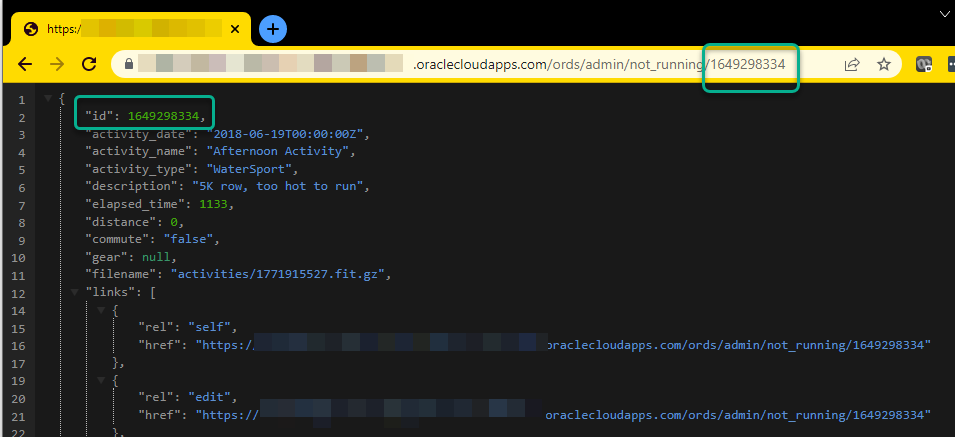
ALTER VIEW ADMIN.NOT_RUNNING ADD CONSTRAINT NOT_RUNNING_PK PRIMARY KEY ( ID ) DISABLE ;
And let’s pull up a row now.
This has another net-effect on our collection, aka the View/
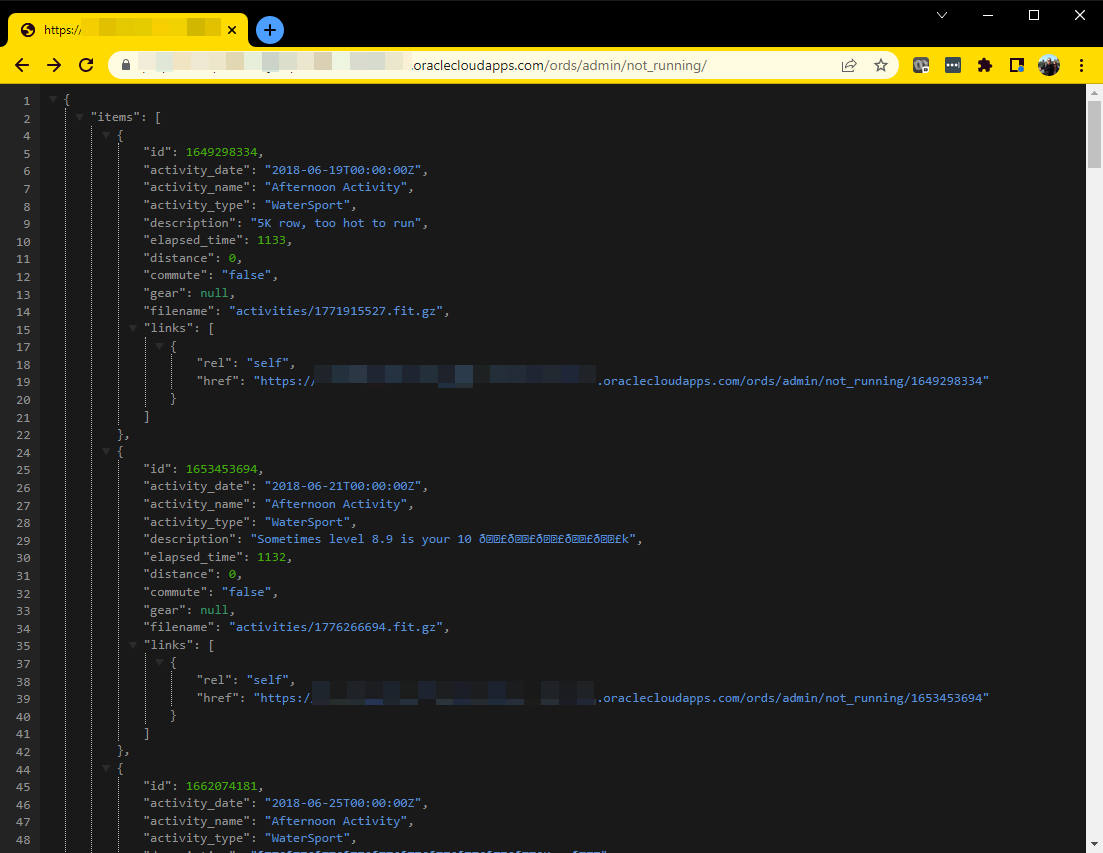
This capability, to add Integrity Constraints to VIEWs has been around awhile. Here’s a Docs link on the topic sourcing from version 10gR2.
Now that my VIEW has a PK, I can update it, too!
I can also now do a
PUT /ords/schema/view/PK
And attach the on the PUT body a {JSON} with the values of the row, and have an UPDATE run.
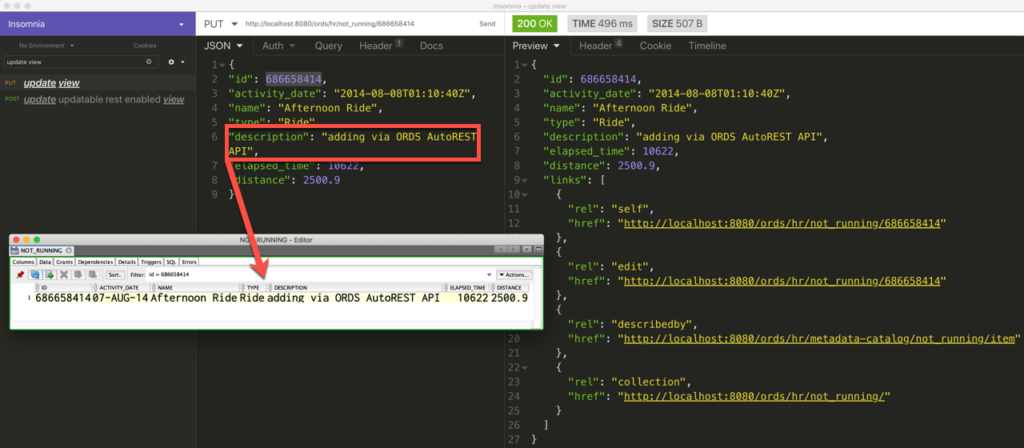
So let’s add a comment to my Afternoon Ride, #686658414.
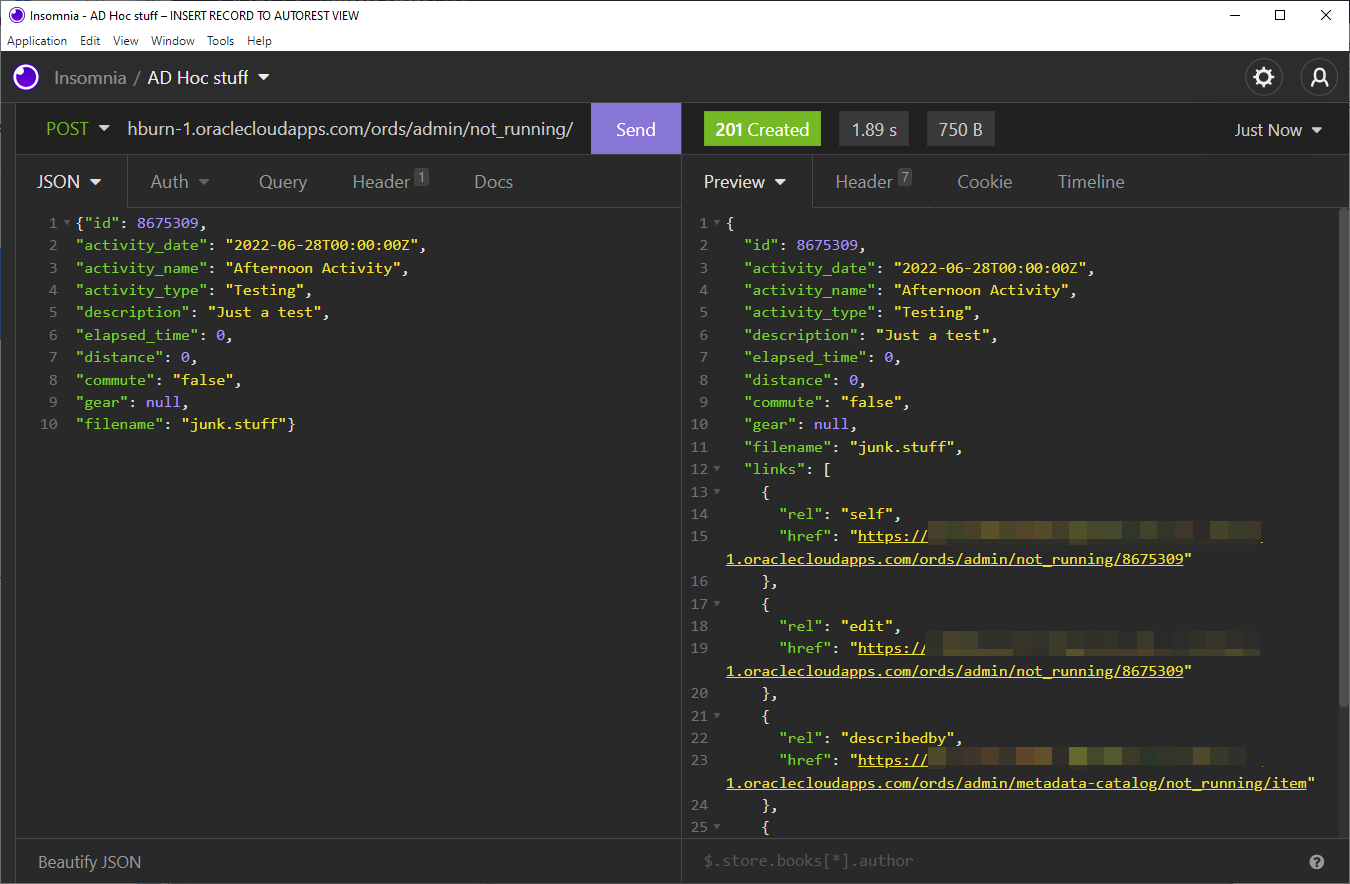
Or a POST / INSERT
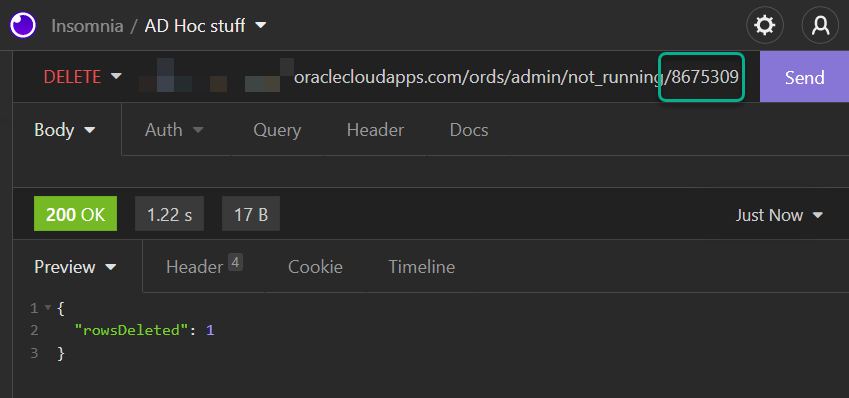
And yes, a very sad DELETE
OpenAPI Doc?
Yes!





3 Comments
SQL> drop table t
Table dropped.
SQL> create table t(x number primary key, y number)
Table created.
SQL> create or replace view v as select x from t where y=1 with check option
View created.
SQL> create or replace trigger g instead of insert on v for each row
begin
insert into t values (:new.x,1);
end;
Trigger created.
SQL> insert into v values (1)
1 row created.
SQL> select * from t
X Y
———- ———-
1 1
1 row selected.
I end up writing a procedure and rest-enabling that procedure instead of this view+trigger approach
I had lot’s of hassle with view with CHECK CONSTRAINT and INSTEAD OF triggers.
I realized in https://www.thatjeffsmith.com/archive/2018/08/executing-pl-sql-package-procedure-via-rest/ that using procedures with in out procedures is so much simpler in my case
You rule Jeff, your SQL Developer is just fantastic… really zero-coding PL/SQL programming, awesome 🙂
Thanks
Thanks Laurent, really appreciate that.
I think anytime you can get rid of a TRIGGER, you’ve already won 🙂