

I’ve talked previously on how I’ve used my iTunes, Untappd, and Twitter data to build local tables I can use for blog posts, presentations, and just general fun with SQL and REST APIs.
But there’s so much great, free data out there to play with, and you just have to go grab it.
awesomedata/awesome-public-datasets
Yes, there’s an AwesomeData github project – click on the titles above.
Wouldn’t it be cool if you could just suck this data in automagically with say SQLcl or SQL Developer or APEX?
Right now you can ad-hoc add them via our loading features, and APEX has a very nice interface for adding Web Sources via REST Endpoints.
But maybe we could do more? (SQLcl> install data flights) Share your thoughts in the comments below!
But for today, I wanted to remind folks how our Import Features work today, and I’m going to use this data set as an example:
US domestic flights from 1990 – 2009
You’ll need a bittorrent client to get it, but other than that, pulling it down is pretty straightforward. Some of the sources, while public, require registration, or even $. This one has very cool data in it, AND it’s free + easy to get to.
“Over 3.5 million monthly domestic flight records from 1990 to 2009. Data are arranged as an adjacency list with metadata. Ready for immediate database import and analysis.“
Hey, we have a database. Let’s go immediately import that!
Creating the Table
Once the file is downloaded, simply right click on the Tables node in SQL Developer’s tree, and select ‘Import Data…’
Then navigate to the file you’ve downloaded (you’ll need to extract it from the Zip after your torrent has finished.)
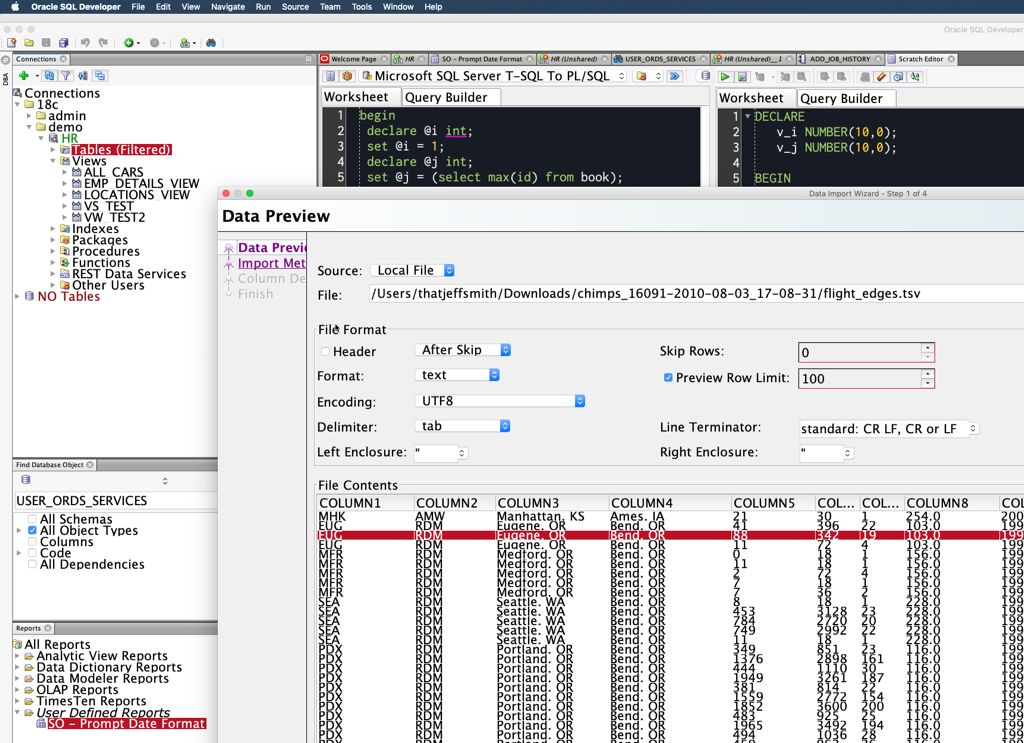
SQL Developer automatically detected the file was TAB delimited – but if for some reason that doesn’t happen for you, just adjust the ‘Delimiter’ field.
Next we need to define the columns – give them a name, and adjust the data types as necessary.
Thankfully the data set tells us what we’re looking at, and we can use this as our guide.
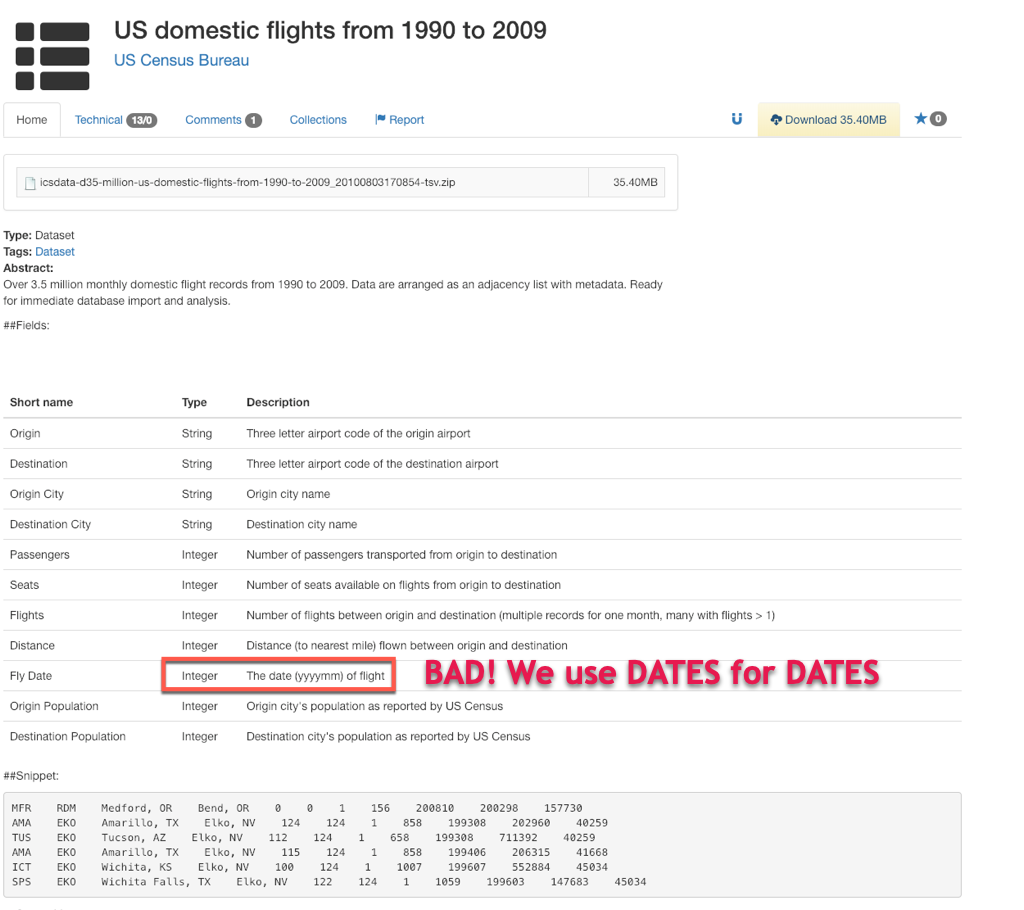
So as we’re adjusting the column definitions, setting the names, etc. – we can make sure the Fly Date is handled appropriately.
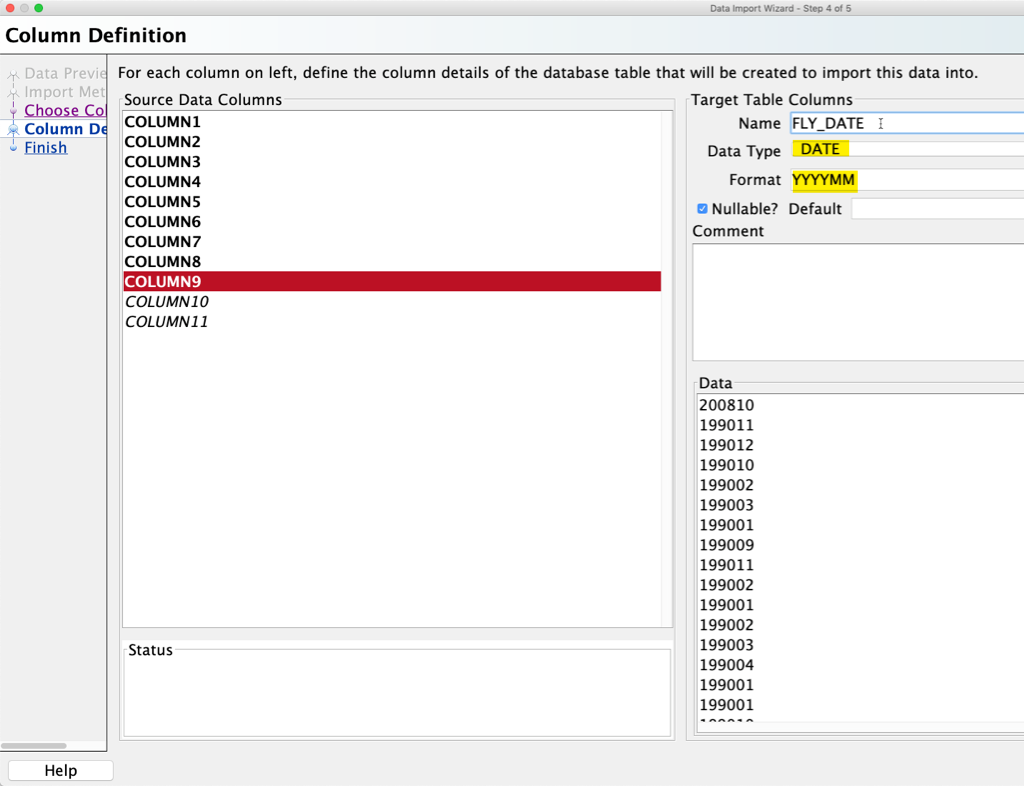
Ok, I’ll get to the end and say ‘Go’
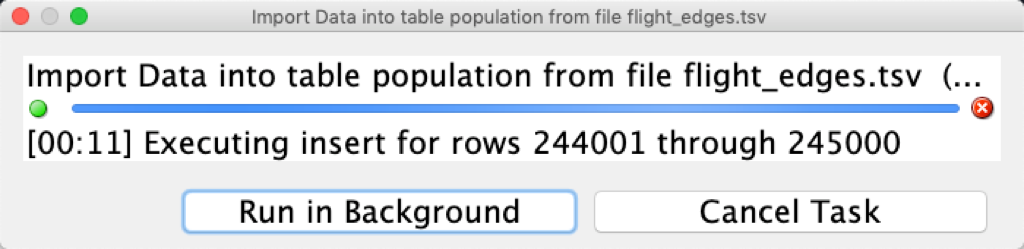
3,500,000 is a small’ish data set. If it were 35,000,000 rows, I’d have setup a SQL*Loader scenario like I talked about here – but I’m ok with just quick and dirty INSERTs, row-by-row.
Before I look at the data, I want to add column comments, which I can do by copying and pasting them over from the GitHub page to the Table Edit dialog.
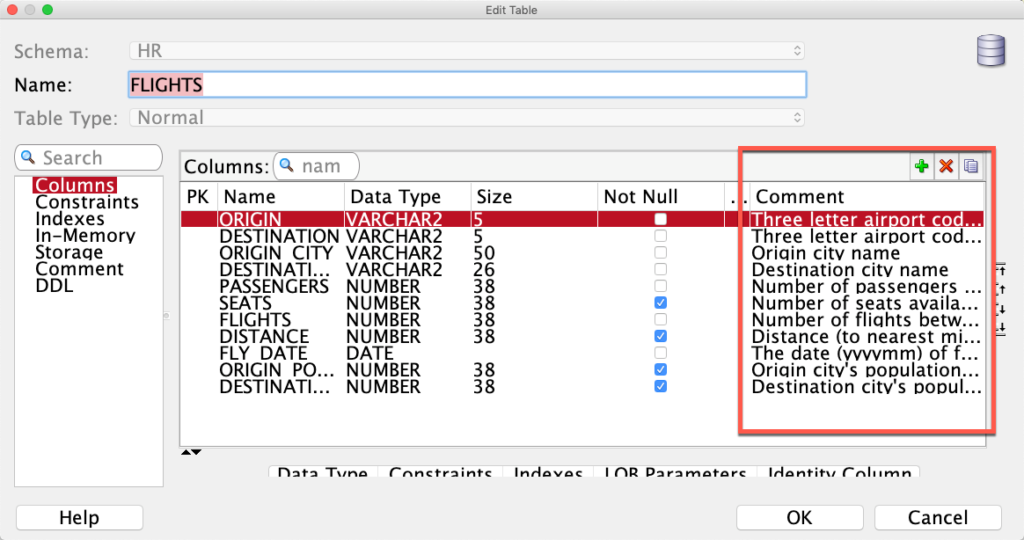
Let’s Look at Our Table!
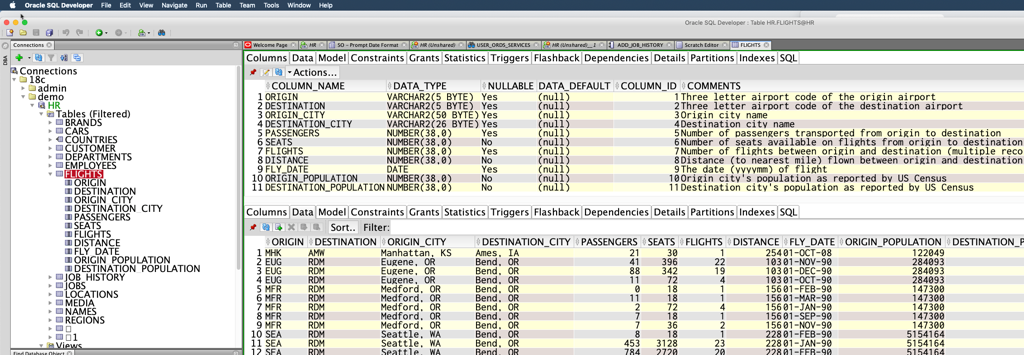
You know the ‘split editor trick’, yes?
What Do We Have?
Well, from what I can tell, I can now see all of the domestic flights over a decade of time in the US. I can see the populations of each city over time. And I can see how full a flight was, or how often a route was flown. Very cool things to build reports around.
What Do I Need to Do?
I’m going to need some indexes. And I’m going to need to build some views probably. And then I can probably start building out some reports and RESTful Services for demos this year.
I built all of this in about 5 minutes. The blog post took much longer to write in comparison. You’ll notice there are hundreds, if not THOUSANDS, of data sets to pull from. This was just the 2nd or 3rd one I pulled from ‘the hat.’




2 Comments
SQLcl>install data flight
Are you talking about a command line version that does all of the above for you?
This would be great for client side deployment scripts.
Or, are you talking about installation of a entire schema (with or without data) similar to yum/CPAN (perl)/CRAN (R)?
The ability to install things from GitHub (or LiveSQL) would be beneficial in sharing code.
PS – some of the public data needs to be …. finessed. (eg HURDAT2)
Install from GitHub or similar…like yum, but for open data…yeah