
TL;DR – I asked Claude to talk to my Oracle Database, build a REST API for me to summarize my streaming history from Spotify. It worked, but I didn’t like the query it used. So I used my brains to fix it, then had it update the API, and then had it generate execution plans and compare to see if it made any difference.
I wanted to give Claude a deeper go at a database task, and I went with ORDS (REST APIs!), since ORDS is ‘one of my children.’
I have an existing Oracle Database, and in there I have my Spotify streaming service data. I wanted to quickly create a REST API that would be served up by ORDS.
Agent: Claude Desktop
LLM: Opus 4.1
MCP Server: Oracle SQLcl
Prompt:
Connect to my Raptor database, and for my Spotify data, construct an ORDS REST API, GET Handler, that returns a collection of artists with a summary of the total number of tracks and total overall time spent listening
You will need to generate some SQL to provide for the GET handler definition in the ORDS PL/SQL API.
Implement the ORDS REST API using the ORDS.CREATE_SERVICE plsql program.
The module base path should be 'claude-apis' and the template should be called 'spotify-summary'
Here is a simple example -
begin
ORDS.create_service(
p_module_name => 'day_zero',
p_base_path => 'day0',
p_pattern => 'greeting/',
p_method => 'GET',
p_source_type => 'json/item',
p_source => 'select ''Hello!'' from dual',
p_status => 'PUBLISHED',
p_module_comments => 'see if we can create a module',
p_template_comments => 'see if we can create a template',
p_handler_comments => 'see if we can say Hello!');
COMMIT;
END;
I can be opinionated, and that’s reflected in my prompt. I wanted things done a certain way, and for Claude to know that, I have to tell it.
Use the all-in-one API (CREATE_SERVICE), and use a specific URI template (spotify-summary) and handler (GET). Also, USE ORDS.
Some information that I know, but Claude does not.
My table looks like this –

Ok, so how will Claude do this? Our MCP Server will offer up tools to interact with my database! And the Agent can then do more than just generate code, it can ACTION it!
My MCP Server –
Oracle SQLcl 25.2.2 running on my Mac, next to Claude Desktop.
Ok, so Claude has my prompt and the MPC Server, what did it do?
Claude’s Plan, how did that go?
- Get list of connections, filtered on “Raptor”
- Found connection, “Project Raptor 🦖”, connected
- Find Spotify tables, queried USER_TABLES looking for %SPOTIFY%
- Found it, SPOTIFY_STREAMING, get column names, data types, and precisions
- Sample data, query first 5 rows
- Develop and test query to satisfy my API request –
SELECT /* LLM in use is claude-opus-4-1-20250805 */ artistname, COUNT(DISTINCT trackname) as total_tracks, COUNT(*) as total_plays, SUM(msplayed) as total_ms_played, ROUND(SUM(msplayed) / 1000 / 60, 2) as total_minutes, ROUND(SUM(msplayed) / 1000 / 60 / 60, 2) as total_hours FROM spotify_streaming WHERE artistname IS NOT NULL GROUP BY artistname ORDER BY total_ms_played DESC FETCH FIRST 10 ROWS ONLY
Hmmm, I gave it an INTERVAL called ‘PLAYING_TIME’ right there in the data, but it decided to do the maths tto compute that on it’s own. Not how I would have done it, but OK - Test query, it works! Well, data comes back, and that’s enough for Claude at this point.
- Construct the create the REST API
BEGIN
ORDS.create_service(
p_module_name => ‘claude_apis’,
p_base_path => ‘claude-apis’,
p_pattern => ‘spotify-summary/’,
p_method => ‘GET’,
p_source_type => ‘json/collection’,
p_source => ‘SELECT /* LLM in use is claude-opus-4-1-20250805 */ artistname as artist_name, COUNT(DISTINCT trackname) as total_tracks, COUNT(*) as total_plays, SUM(msplayed) as total_ms_played, ROUND(SUM(msplayed) / 1000 / 60, 2) as total_minutes_listened, ROUND(SUM(msplayed) / 1000 / 60 / 60, 2) as total_hours_listened, ROUND(AVG(msplayed) / 1000, 2) as avg_seconds_per_play FROM spotify_streaming WHERE artistname IS NOT NULL GROUP BY artistname ORDER BY total_ms_played DESC’,
p_status => ‘PUBLISHED’,
p_module_comments => ‘Claude APIs module for Spotify data analysis’, p_template_comments => ‘Returns artist summary with total tracks and listening time’,
p_handler_comments => ‘GET handler returns collection of artists with track counts and total listening time’ );
COMMIT;
END;
/ - Check to see if it’s in the ORDS repo, queries USER_ORDS_MODULES
FIRST FAILURE!
SQL Error: ORA-00904: “M”.”BASE_PATH”: invalid identifier
BASE_PATH isn’t in USER_ORDS_MODULES - Tries again to get our our METADATA several different ways..even tries to use the run-sqlcl tool to issue the ORDS MODULES command…this is where Claude basically fell down, but still managed to declare victory.

It had a hard time querying the ORDS_ user views, but that’s OK, the real test can be done via HTTP because my ORDS webserver is up and running!
There’s another way to test…
Prompt:
let’s test this with curl, the API is being served at http://localhost:8080/ords/hr
Response:
Perfect! I've created a comprehensive set of curl commands for testing your ORDS REST API. The main command to test your endpoint is:
bash
curl -X GET http://localhost:8080/ords/hr/claude-apis/spotify-summary/
Try running this command in your terminal. The API should return a JSON response with all your Spotify artists sorted by total listening time.
If you want to see the output in a more readable format, you can pipe it through a JSON formatter:
If you have jq installed:
curl -s -X GET http://localhost:8080/ords/hr/claude-apis/spotify-summary/ | jq '.'
It just so happens I have cURL and jq available, so cutting and pasting to bash –
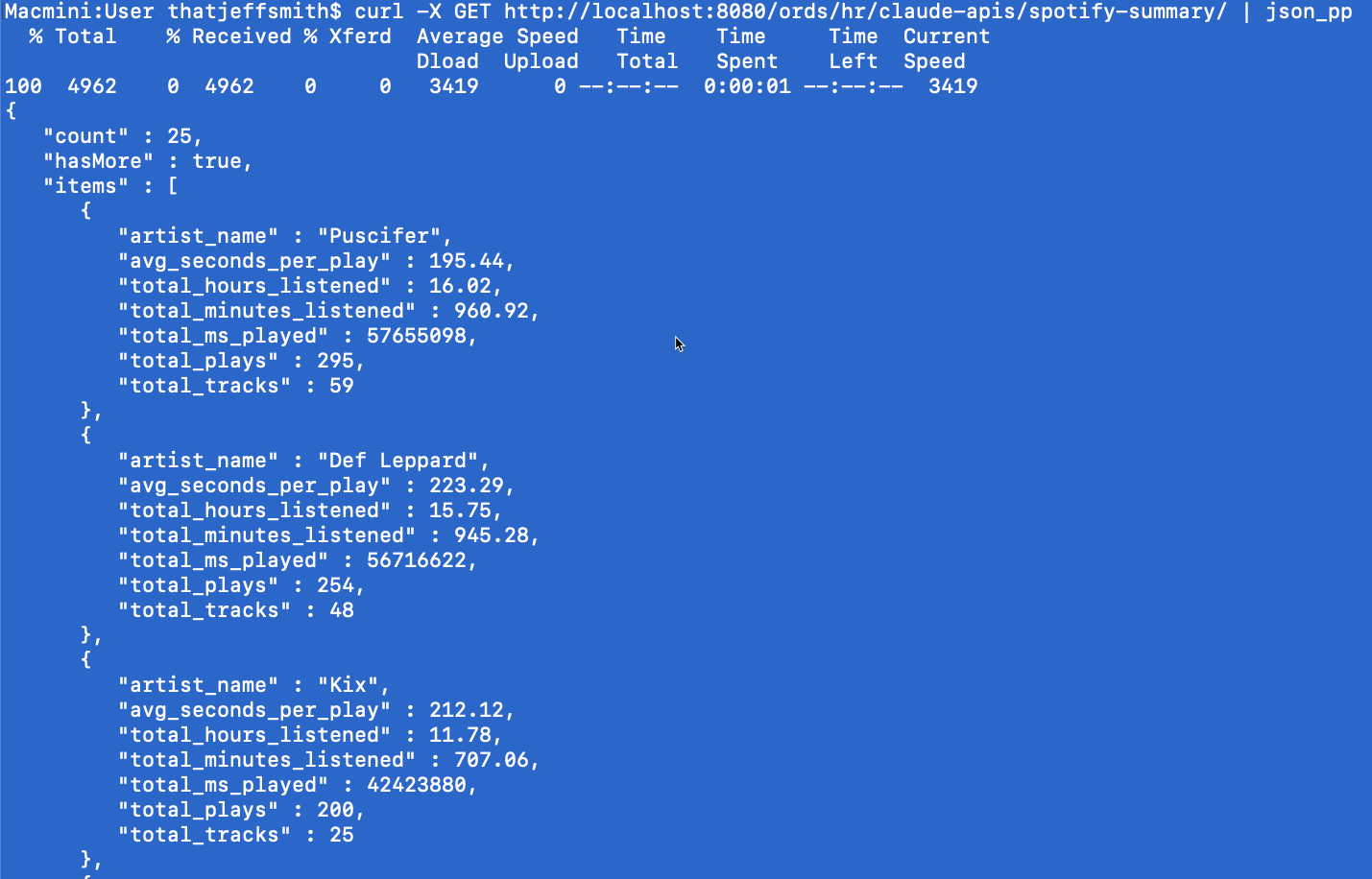
OK, so does it make sense that over the time period, a year, that I spent ~16hrs listening to 48 different Def Leppard songs? I think so…yeah I think the SQL and results are solid.
Speaking of Def Leppard, I’ll be seeing them at AI World next week!
Reviewing the agent’s work
What all happened in between the agent and the database?
The meaningful work all occurred over the first 6 tool interactions. The LLM invented a SQLcl command ‘show ords.url’ – not a bad idea, but technically not feasible. At least not when being served up by SQLcl.

This handler query isn’t sitting right with me.
select /* LLM in use is claude-opus-4-1-20250805 */ artistname,
count(distinct trackname) as total_tracks,
count(*) as total_plays,
sum(msplayed) as total_ms_played,
round(
sum(msplayed) / 1000 / 60,
2
) as total_minutes,
round(
sum(msplayed) / 1000 / 60 / 60,
2
) as total_hours
from spotify_streaming
where artistname is not null
group by artistname
order by total_ms_played descDo you see it? We’re writing lots of SQL text to do pretty simple maths, which is unnecessary in 23ai. We can simply SUM and AVG the interval column, to get back the numbers all at once, vs doing multiple paths to get days, hours, minutes, and seconds.
Let me re-prompt Claude:
Prompt:
I noticed you are summing the milliseconds and dividing it out multiple times to get the hours, minutes, and seconds played
We're connected to a 23ai database, this is much easier now, we can simply SUM the PLAYING_TIME column, which is an interval, which will return the time spent represented as Days, Hours, Minutes, and Seconds, and even fractions of a second up to 6 digits of precision
let's refactor our REST API to do that instead -
we can keep the interval type
we do not need to drop and recreate the handler, we can simply define the handler again, and it will overwrite or replace the existing api SQL
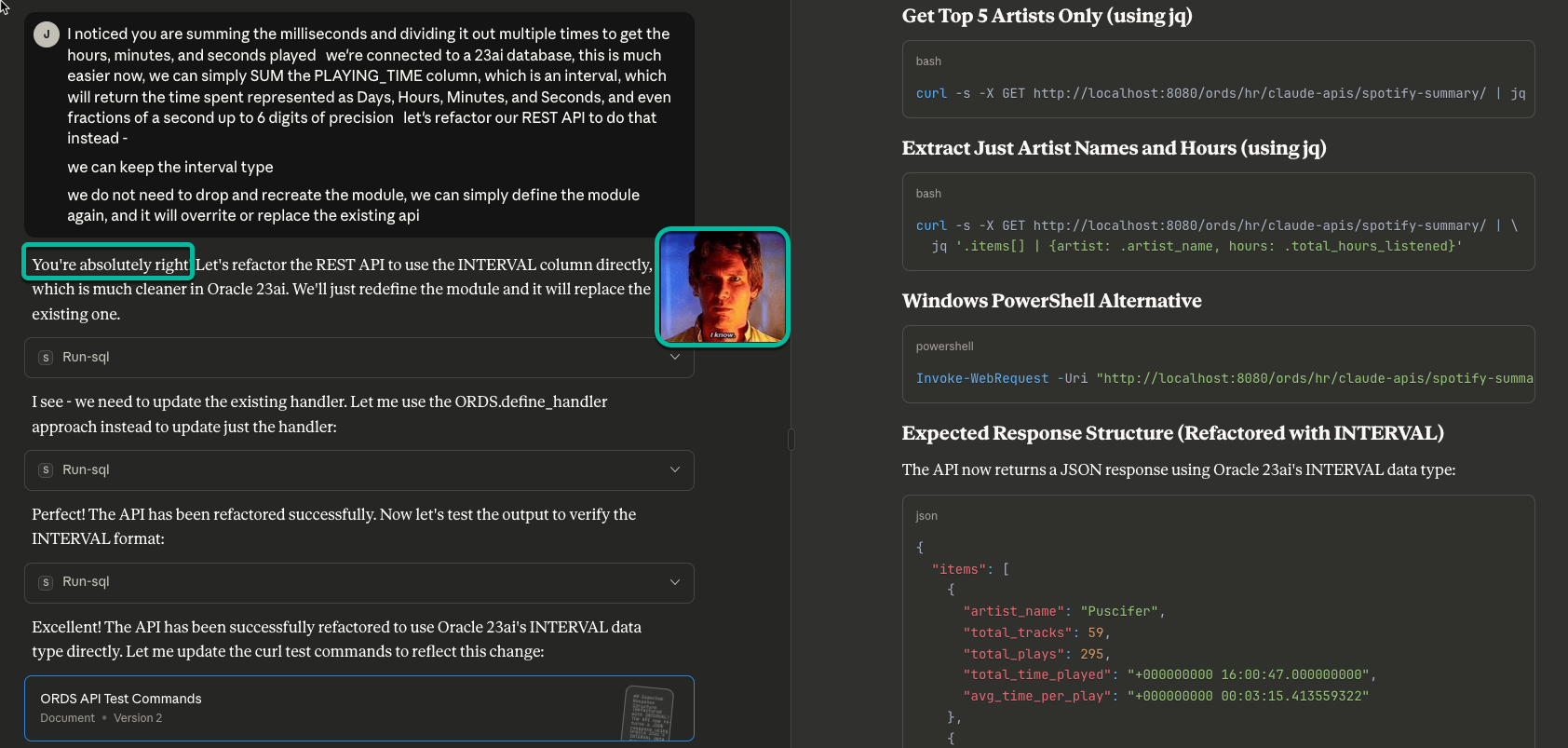
It agrees with me, because they have been trained to always think we’re right, even if we’re not.
But it did what I asked it to do, it republished the REST API.
So, let’s run our cURL test again –

The data is the same, but the resulting JSON payload is smaller (more efficient!), now we just have a single attribute for avg time played and total time played, vs breakouts on hours, minutes, and seconds each.
So theoretically the SQL is better, what about the plan/performance?
I can do the comparison myself, because these plans are pretty simple…
Query and Plan 1 – not summing/averaging the INTERVAL
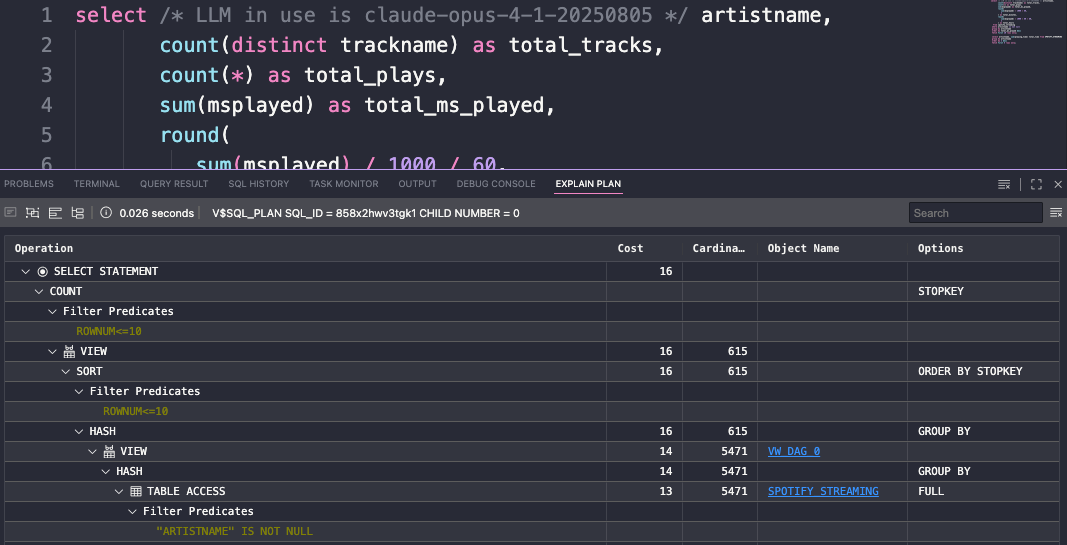
Query and Plan 2 – simply using the INTERVAL to get the sum and average
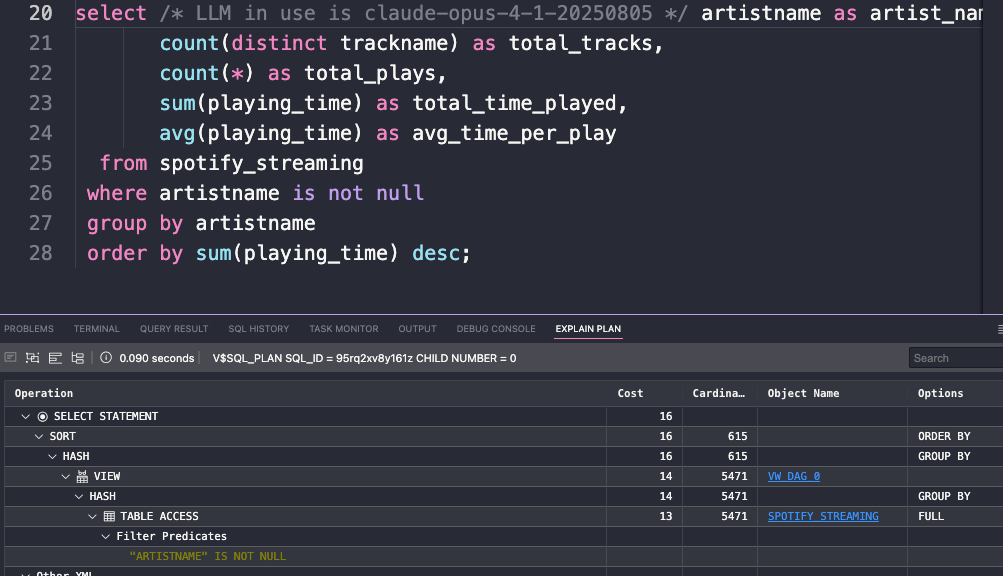
OK, I’m pretty happy with that, and I was expecting the cost and cardinality estimates to remain the same, and they are.
But what does Claude think?
Prompt:
So we started with this query
select /* LLM in use is claude-opus-4-1-20250805 */ artistname,
count(distinct trackname) as total_tracks,
count(*) as total_plays,
sum(msplayed) as total_ms_played,
round(
sum(msplayed) / 1000 / 60,
2
) as total_minutes,
round(
sum(msplayed) / 1000 / 60 / 60,
2
) as total_hours
from spotify_streaming
where artistname is not null
group by artistname
order by total_ms_played desc
and ended up with this query
select /* LLM in use is claude-opus-4-1-20250805 */ artistname as artist_name,
count(distinct trackname) as total_tracks,
count(*) as total_plays,
sum(playing_time) as total_time_played,
avg(playing_time) as avg_time_per_play
from spotify_streaming
where artistname is not null
group by artistname
order by sum(playing_time) desc;
Let's ask the database for explain plans for each and compare those - did we theoretically change the performance at all, or is the query just easier to read and maintain?
Claude proceded to:
- Run query 1
- Execute DBMS_XPLAN to get the execution plan
- Rinse and repeat for query 2
- Compare the output from each, and summarize –
Findings (click image to see full report) –
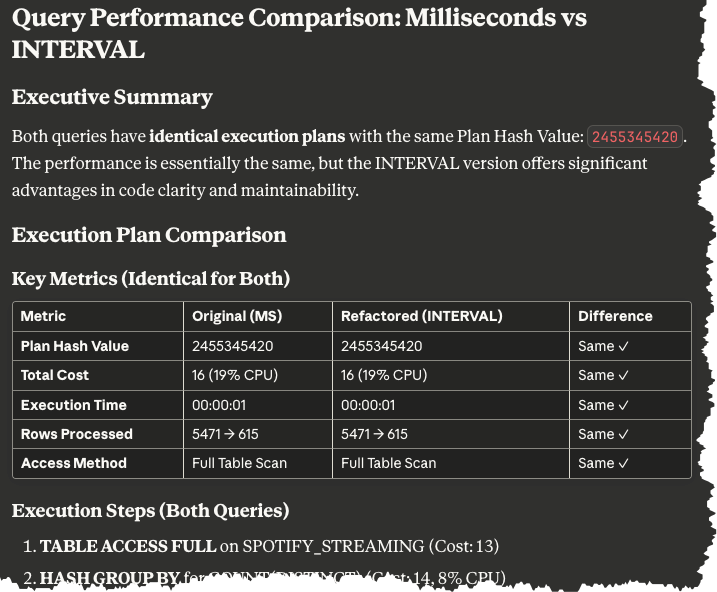
Summary
I was pretty happy with my coding session with Claude. And I dug the agent interface and workflow. Being able to generate and share the findings is pretty nice, too!
Remember – stay in charge, stop it when it goes astray, don’t trust that it’s taking the best path to the finish line, correct it as needed.



2 Comments
Hi Jeff, off topic question about this article (not too much off topic) : How was Def Leppard performance at AI World?
It was great! They really put on a great performance, and I was only about 20ft from the stage.