

If you’ve visited my blog before, you’ve likely seen several posts here on a similar topic, Liquibase. Several years ago we enhanced that open source library to make it easier to generate Liquibase changeSets for your Oracle Database objects, schemas, ORDS REST APIs, and APEX applications.
This allowed developers to ‘do their work’ – and deliver that work to the Oracle Database, in an automated, and controlled fashion using Liquibase.
Today I want to introduce the next evolution in CI/CD for the Oracle Database with SQLcl’s new project command.
But first let’s discuss why we built this Project mechanism, and contrast it with the existing Liquibase commands.
Why the Project command was necessary
While using the liquibase command offered a ton of benefits over putting together your own custom SQL scripts, there were a few things it didn’t do:
- fit neatly into your existing Git workflows
- implement easy-to-read (diffs!) SQL based changeSets
- package up your changes to drop-dead-simple artifacts for deployments
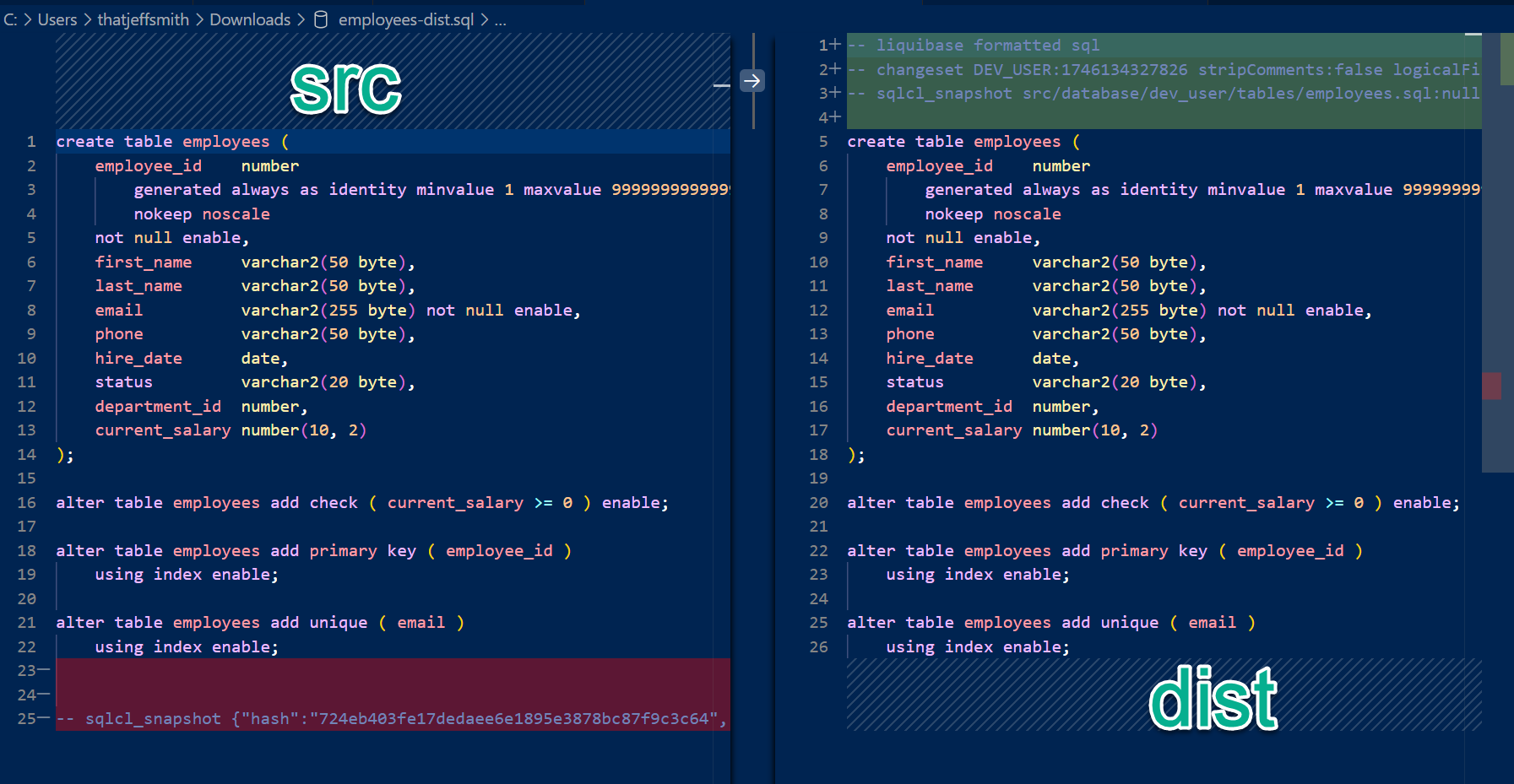
Database changes are also computed/delivered differently
This is perhaps the biggest difference between liquibase update and project deploy – how the CREATE/ALTER scripts are generated and deployed.
SQLcl Liquibase command changeLogs
These are comprised of XML changeSets, that SQLcl uses to describe the state of the database object. When an ‘update’ is issued, SQLcl looks to see what the current state is in the target database, and dynamically generates the DDL/PLSQL necessary to get to that state.
That means the target system could be in a state where the object to be altered doesn’t even exist yet, and we would create it for you.
SQLcl projects command changeLogs
These are comprised of SQL changeSets, that SQLcl executes as-is when deployed to a database. The SQL is computed not at deployment time on the target system, but when the local src code is used to stage the deployment scripts.
The target system, your UAT or Prod instances for example, will be at an expected state (release), and will have these scripts applied – assuming the the dependencies and conditions described in the changeLog are satisfied.
Which way to go? Which methodology or command should our team pick?
If you’re already using our enhanced Liquibase command in SQLcl, and you’re happy with it – keep going!
If you’re about to start work on a new application, it’s our official recommendation that you go with a SQLcl project. In fact, it’s what we’re using here at Oracle for several critical solutions.
We will be maintaining both features going forward, and we’re using our enhanced Liquibase library under the covers for the Project command. Our clear path forward and the technology receiving the most updates will be the projects command.
Let’s do a brief walk through of what the Project command does, and how it works.
If you want a deep-dive demo of how exactly you can use this, you’re in luck!
- try our hands-on-lab, a guided tutorial for updating a React app’s associated schema
- my multi-part series on using projects (Part 1: Getting Started)
I highly recommend the LiveLab. And it comes with a bonus: see how a React web app can be powered by ORDS REST APIs!
SQLcl Project resources
- SQLcl Docs
- Webcast: using SQLcl for your database schema
- Webcast: using SQLcl for your database schema AND Oracle APEX apps
- Forums
A reasonable way to approach the SQLcl Project command, is to break it down to its sub-commands. Let’s do that now. Note, I’m not going to show how this would integrate into your Git workflow in this post
For the complete, step-by-step demo, see this.
What is the project command, what does it do?
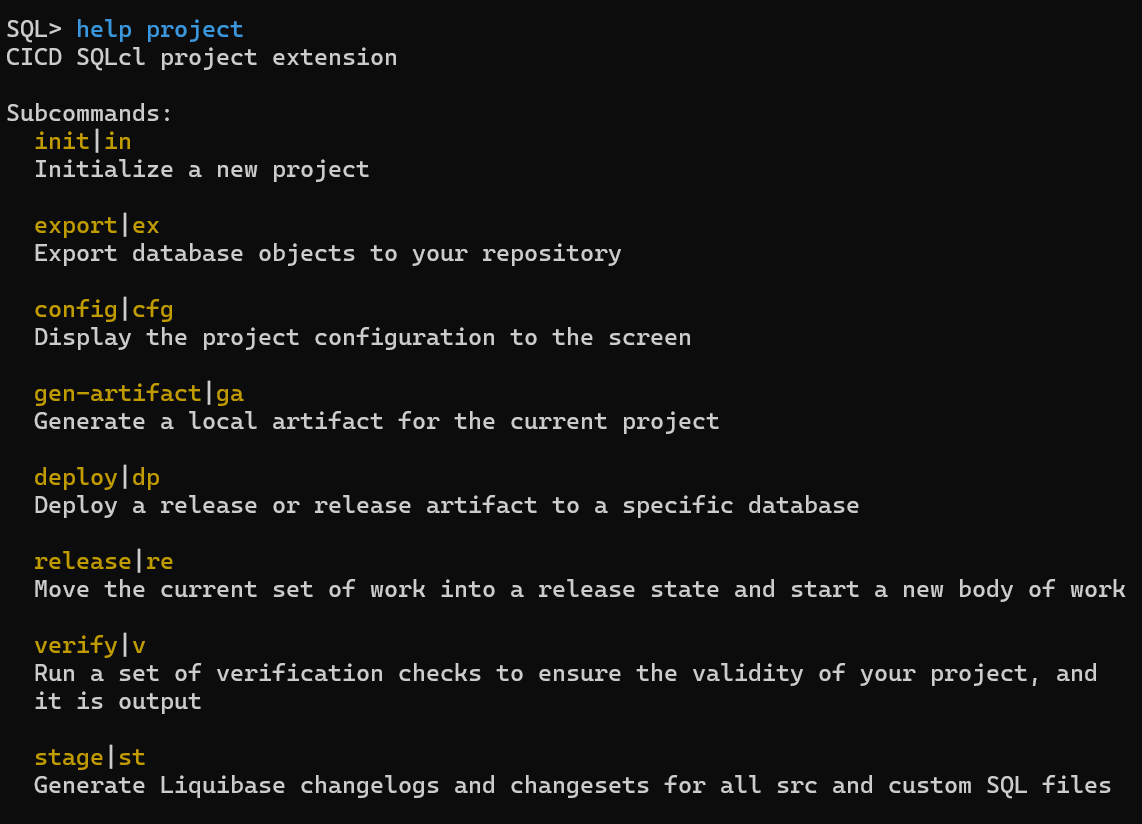
init – sets up our local directories and files, also is where you specify the schema or schemas that will be used by our project.
The initial directory structure looks like this –
──.dbtools
│ ├── filters
│ │ └── project.filters
│ ├── project.config.json
│ └── project.sqlformat.xml
├── dist
│ └── install.sql
└── src
export – this uses a database connection to take all of your database objects and PL/SQL programs, REST APIs, and APEX apps and writes them to local files in your source (src) folder. We’ll organize these by object type.
This ‘src’ will always contain the ‘source’ of truth for your table, procedure, or REST API. It will be the complete representation of the object, defined as SQL or PL/SQL.
stage – this will populate the dist (distributable) directory tree with the SQL scripts to be used to deploy a ‘release’ or ‘version’ of our application schema. The ‘dist’ files are computed from the ‘src’ by comparing them to the accompanying files in your Git project’s active branch.
It’s at this point, that it should become obvious why using Git to maintain your Oracle schema objects and PL/SQL programs is no longer an option. We’re NOT using the database to generate these distributable objects, but your own Git project files! Now, of course you could argue we’re getting those files from the database, but it is an important distinction.
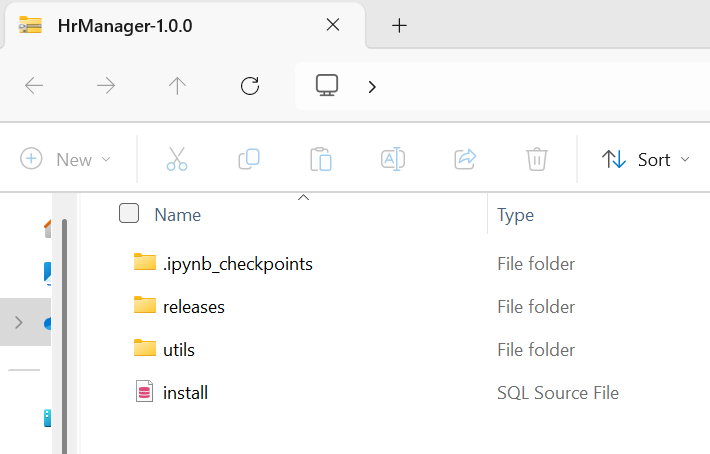
release – instead of working off of ‘master’ or ‘next,’ we’re going to have a release, such as 1.0.0 that will be used to deploy our project to the database (install), or say a 1.1.0 that’s used to upgrade an application from 1.0.0.
gen-artifact – this packages up the release dist files along with it’s install.sql script, and bundles it up in a Zip archive. This can then be used by the deploy sub-program to be applied to a database.
deploy – the simplest command, this takes an artifact (Zip), and deploys it to your database to be applied.
Summary
SQLcl’s Liquibase support has taken a major step forward with the Project command. This new workflow is a highly structured process allowing development teams to:
- maintain their Oracle Database schemas in Git
- automatically generate and manage your src and dist files
- easily compare what’s changed by keeping everything in easy-to-read SQL scripts
- setup development and production pipelines to ensure consistent and reliable database schema installs and upgrades, backed up by rigorous and automated testing via their CI/CD systems




2 Comments
Thanks for the resources.
Unfortunately the link to “Webcast: using SQLcl for your database schema AND Oracle APEX apps” seems to point to the forums instead of a webcast.
Fixed, the links were just reversed 🙂
Thanks for the head’s up!