And sometimes a bit tricksy.
JSON and SQL are both super popular AND relevant in 2022. JSON killed the XML star. If you have data, there’s a 87% chance it will be stored as a JSON Document. Is this a made-up stat? Yes, but I also challenge you to prove me wrong.
Note: yes, I know CSV and XML are super popular, especially if you are in 2005.
You know what else is popular? Yeah, SQL – 45+ years old and still learning new tricks!

JSON and SQL, easy with Oracle since at least 2015
Our Oracle Database has been adding built-in JSON functions and interfaces since the 12.1 release. And I’ve learned a ton about how to use that from folks like Beda and Josh.
I wanted to take a second to share what I’ve learned and used to crunch some data here lately. And by second, I mean a few hours! This post took a bit longer than normal, but it was worth every moment!
Here’s some data one of our ORDS product manager’s scraped from his Medium blog stats. He’s figure out how to pull it down, and put it back up into his Always Free Oracle Database.
{
"value": [
{
"userId": "887d963500db",
"flaggedSpam": 0,
"timestampMs": 1661400000000,
"upvotes": 0,
"reads": 1,
"views": 2,
"claps": 0,
"updateNotificationSubscribers": 0
},
{
"userId": "887d963500db",
"flaggedSpam": 0,
"timestampMs": 1661403600000,
"upvotes": 0,
"reads": 2,
"views": 2,
"claps": 0,
"updateNotificationSubscribers": 0
},
{
"userId": "887d963500db",
"flaggedSpam": 0,
"timestampMs": 1661407200000,
"upvotes": 0,
"reads": 1,
"views": 1,
"claps": 0,
"updateNotificationSubscribers": 0
}
]
}It’s a JSON Document that contains an array of more JSON.
So if I were to store this in a table, it might look like this:
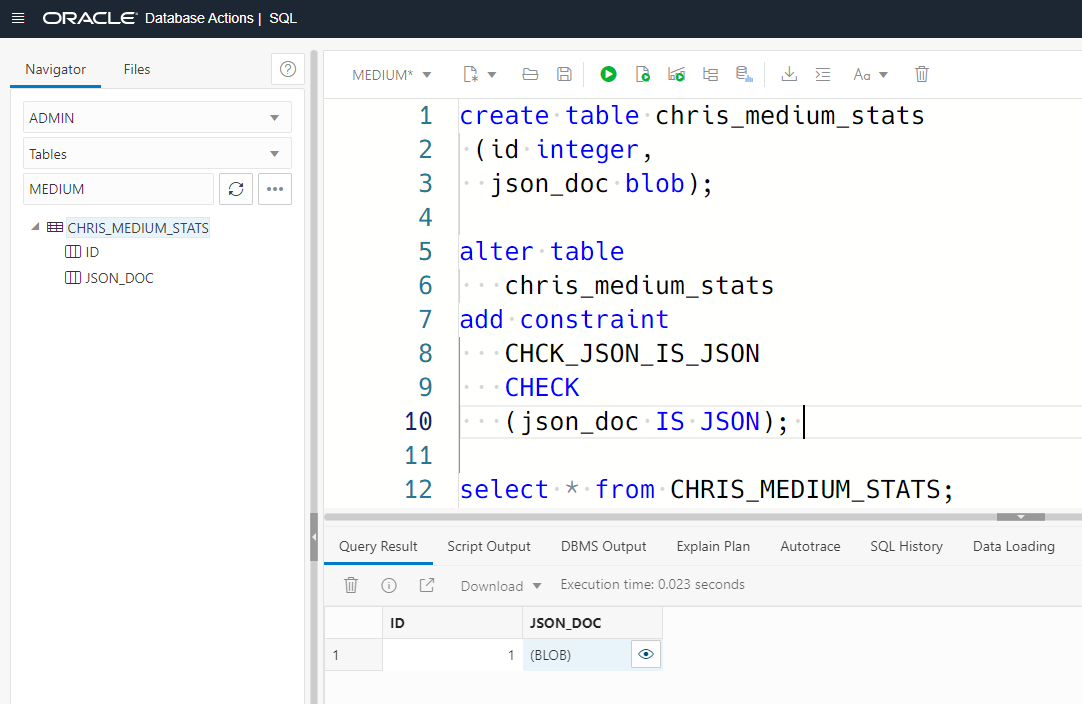
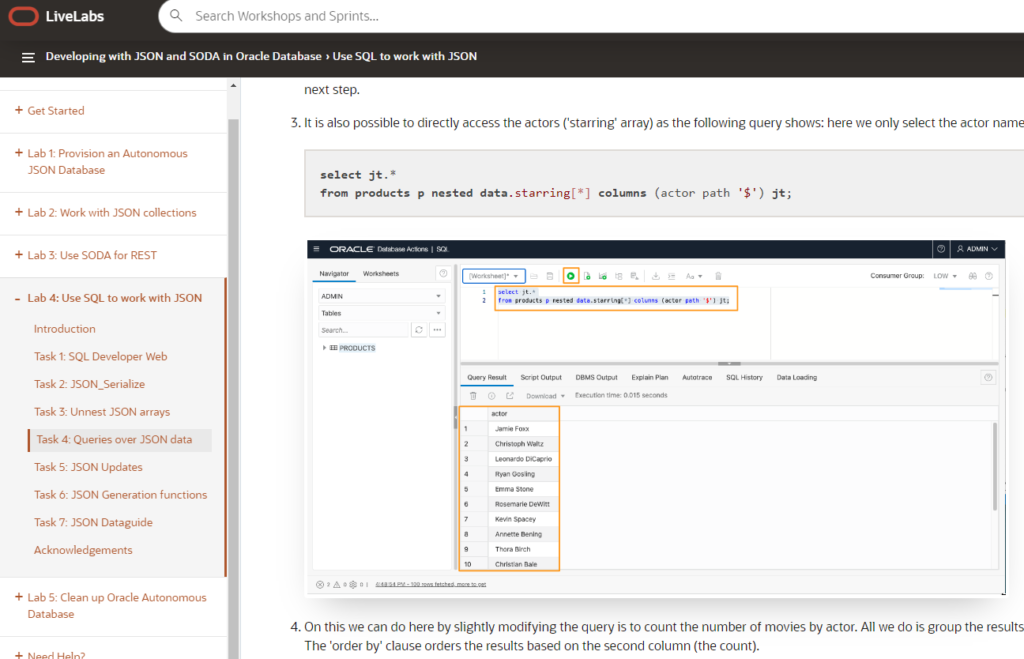
Wait, how did I populate the table to begin with? I used SQL Developer Web’s TABLE viewer to do that –
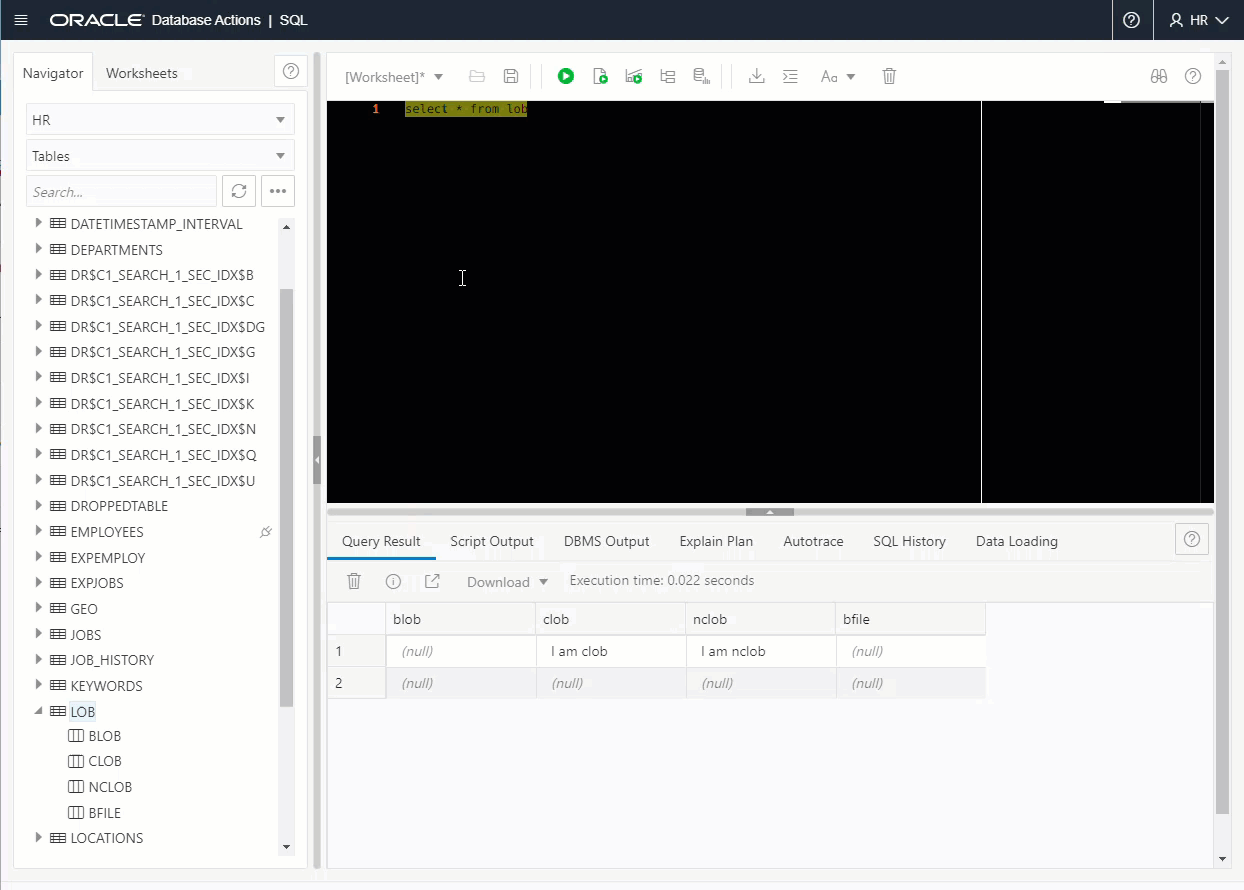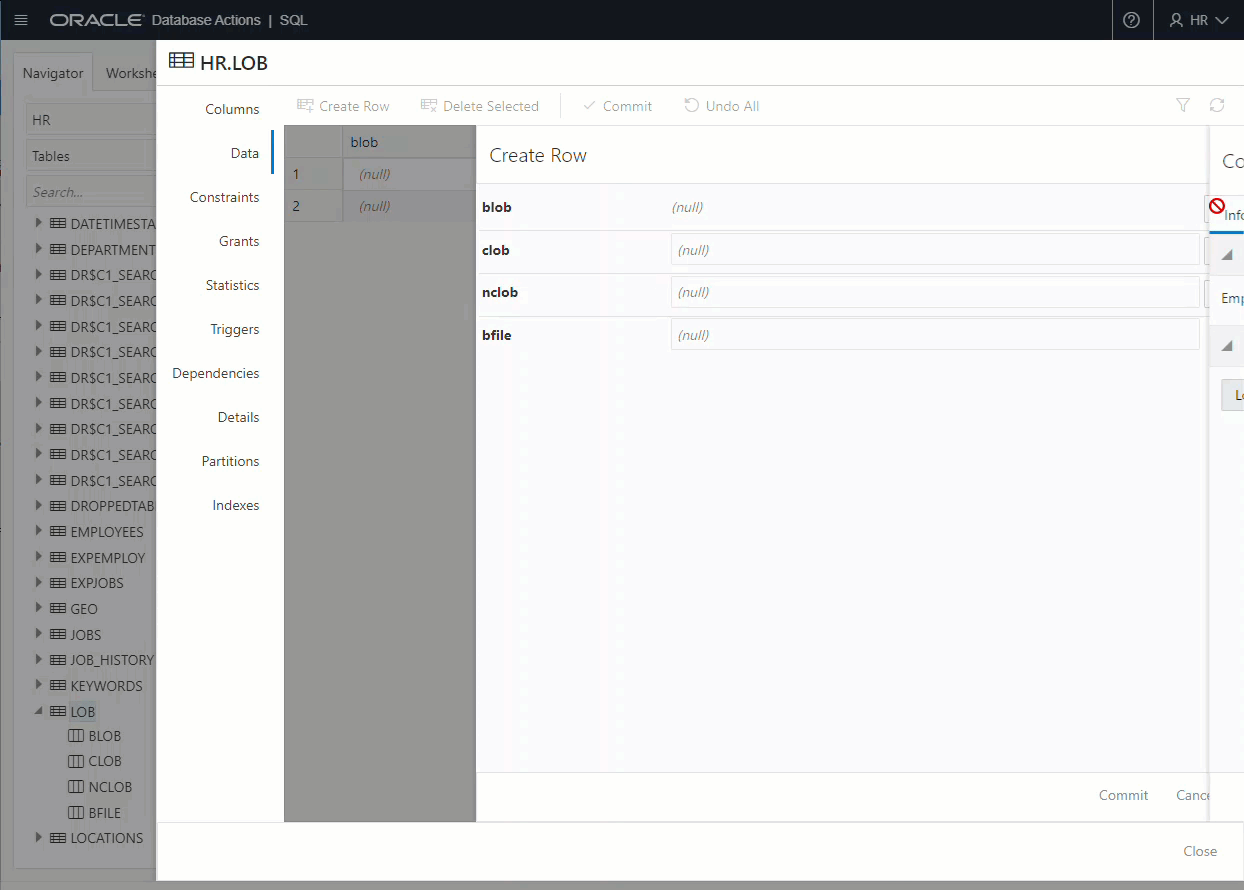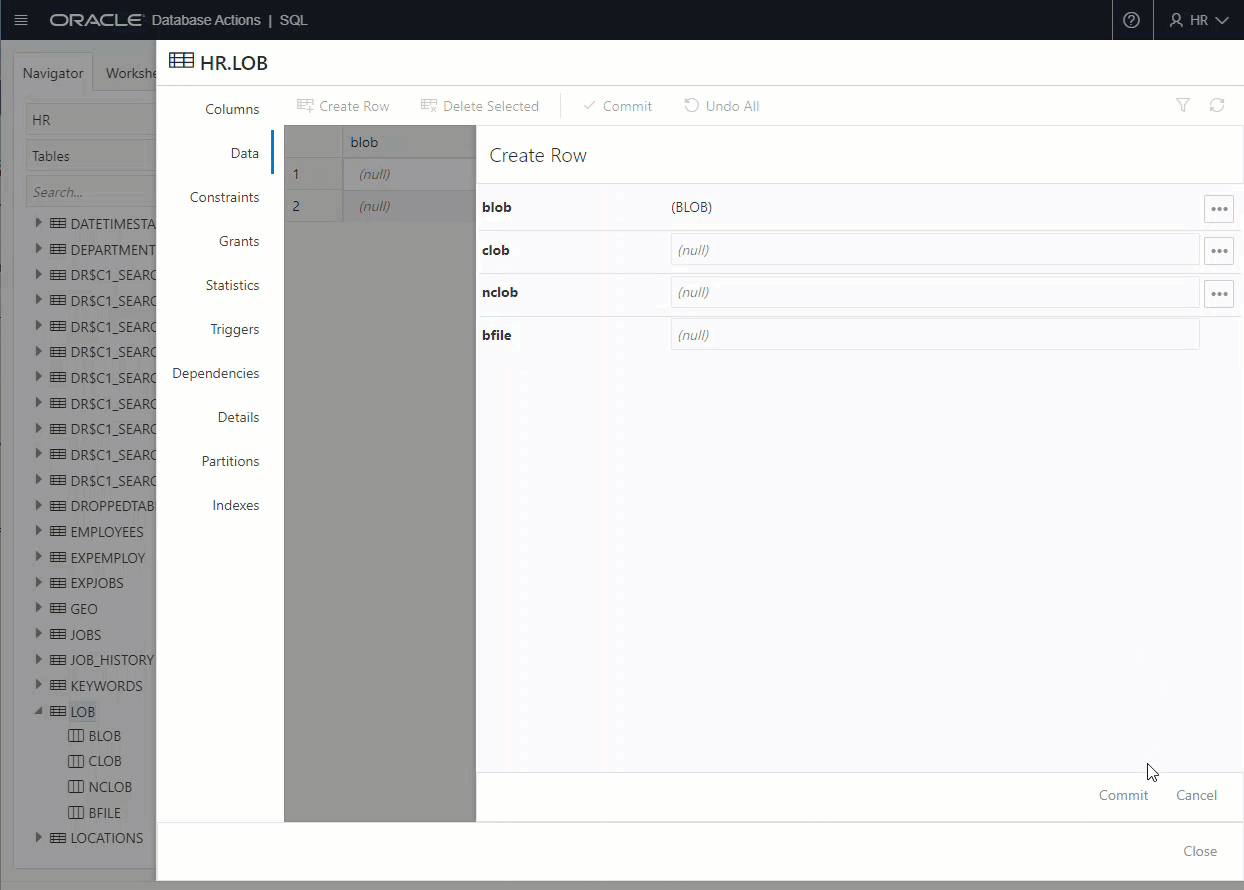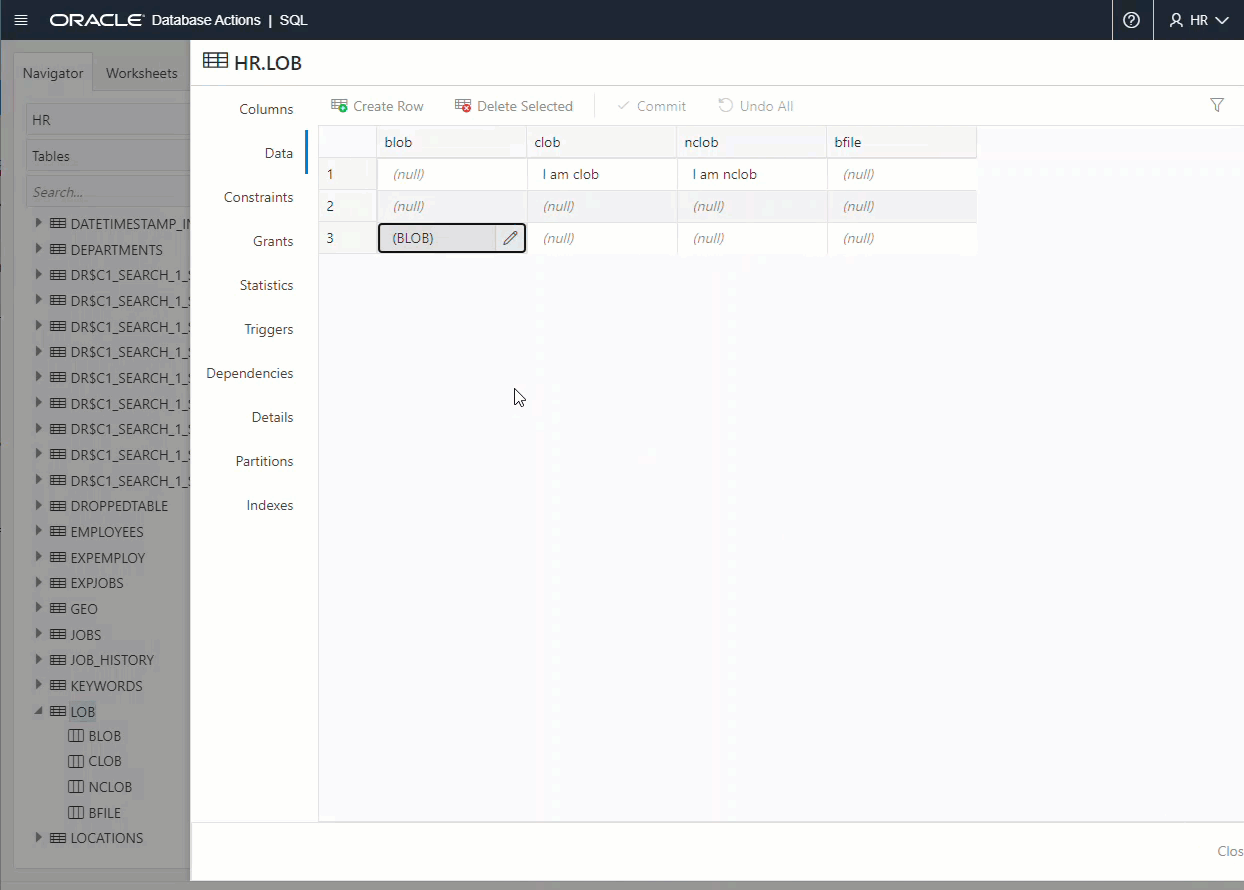
When querying the table back, you can use this “Trick. Click on the eyeball, we’ll show you your JSON doc.
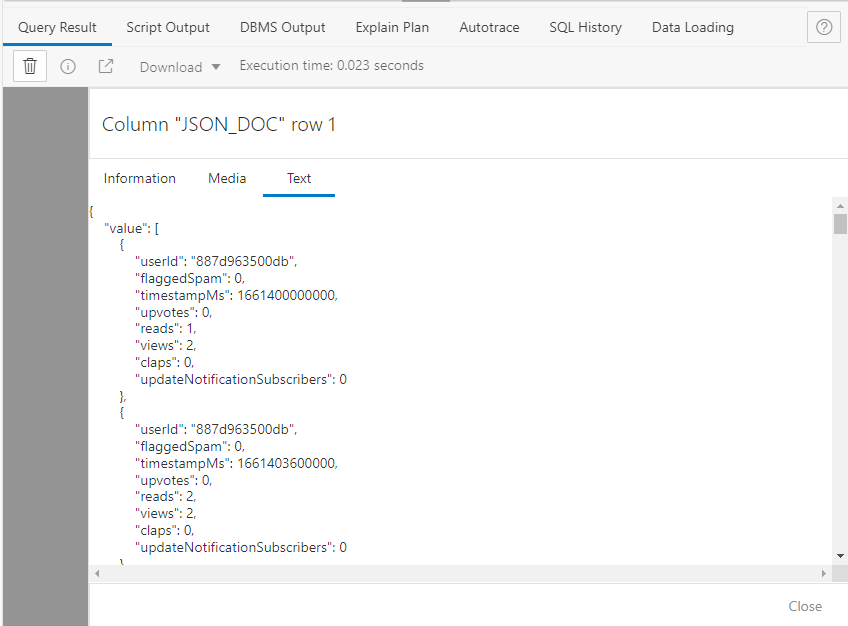
Wouldn’t it be nice if we could use SQL to grab “views”?
Yes, of course it would be! And I’m going to help Chris figure out the SQL to get some nice Medium stats from his blog posts.
The JSON function/feature we are going to use in our SQL for this use case of ‘1 big JSON doc but I want many, many rows of output’ is JSON_TABLE.
Given one input (JSON data ) JSON_TABLE can give us multiple outputs (rows).
Beda, our JSON Architect.
We’re going to combine this powerhouse of a function with what Beda and the JSON team refer to as ‘simple DOT notation.’
‘Simple DOT notation’ in a table has generally been things like ‘TABLE.COLUMN’, so if we had a very simple JSON value stored in our column, we could query it out like so –
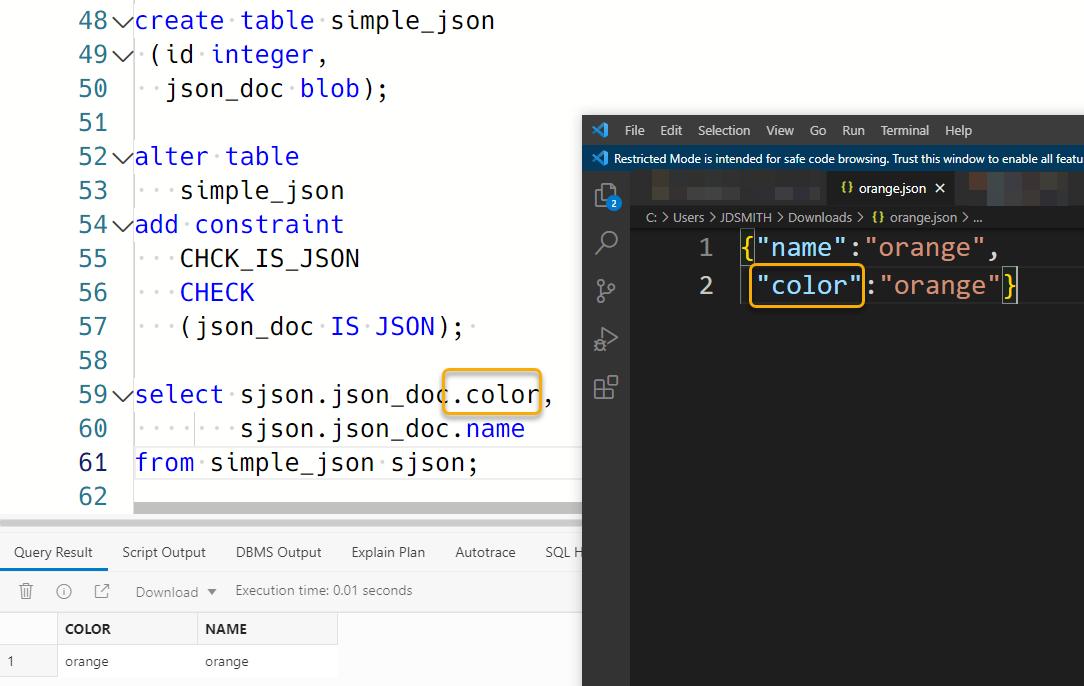
We can use this when the database knows our data is JSON. The database can know this in several different ways. One, you tell it is with a CHECK constraint (IS JSON) on the column. Or optionally if you’re on 21c or higher version of the database, use the native JSON data type.
We’re not ready for 21c, what about 19c?
IF you’re on Autonomous you can get closer to native JSON storage. 19c Autonomous instance allow you to get more optimized binary storage format which is FASTER. Use this variation of the IS JSON check constraint.
is json FORMAT OSON
See the JSON Developer's Guide for more info.What if our JSON is a bit more complicated?
You might start to see text like this in your SQL SELECT statements –
$.attribute[*]One of the reasons JSON is popular is due to it’s flexibility and ease of use. Your document can contain simple value pairs, but it can also include objects and arrays.
As we start to navigate these more complicated JSON documents, we need to build a ‘Path Expression.’ These will ALWAYS start with a dollar sign ($).
Arrays are notated with brackets [] – and we can specify all the items in our array [*], or specific items or ranges of items [0] or [1 to 3] or [0,5]. JSON arrays start with position 0.
My data DEFINITELY has an array to deal with –
"value": [
{..
},
...
]I have around a thousand of items in this JSON Array, and if we’re going to use SQL to query it, we definitely need to be able to reference those items using Simple Dot Notation.
The JSON_QUERY function Oracle Docs is one of the better explanations I’ve seen that puts many of these concepts together. Definitely worth a look-see!
The magic of JSON_TABLE is where you match up a JSON expression with the COLUMNS keyword, a la:
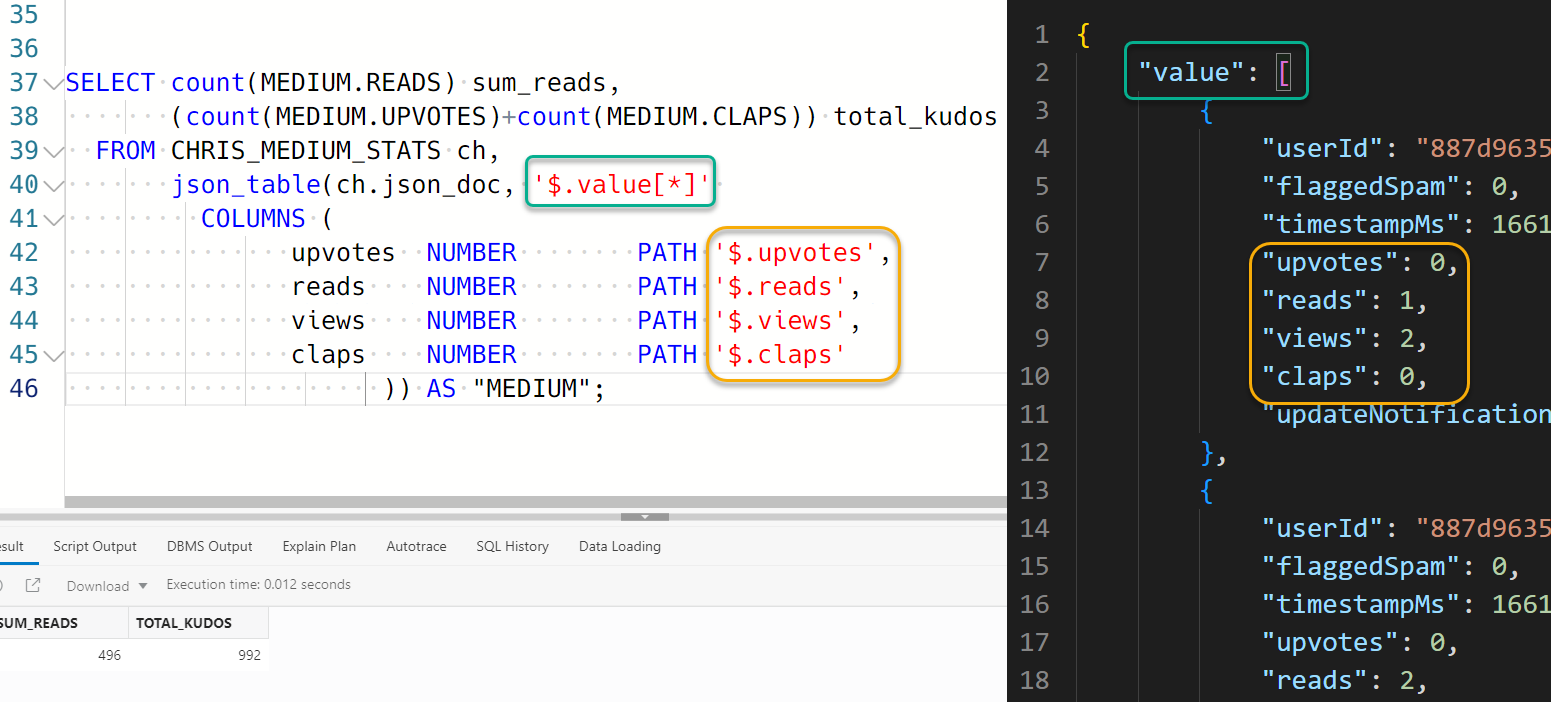
I can now refer to all JSON docs in the value[] array as ‘MEDIUM’ and four different attributes as columns, UPVOTES, READS, VIEWS, and CLAPS.
And now that I refer to those values, I can write a very simple query to sum the values across all the items in my JSON array.
Even more complicated JSON and SQL
I want to sum up these different metrics and group it by month. You can see in my screenshot there’s a attribute called “timestampMs” = that’s an Epoch period defined in milliseconds.
And thanks to StackOverflow, I have a pretty easy formula to sort that.
SELECT SUM(MEDIUM.READS) total_reads, (COUNT(MEDIUM.READS) + COUNT(MEDIUM.CLAPS)) total_kudos, to_char(TIMESTAMP '1970-01-01 00:00:00.000 UTC' + NUMTODSINTERVAL ( MEDIUM.ROLLUP_DATE / 1000, 'SECOND' ), 'Month') MONTH FROM CHRIS_MEDIUM_STATS ch, json_table(ch.json_doc, '$.value[*]' COLUMNS ( upvotes NUMBER PATH '$.upvotes', reads NUMBER PATH '$.reads', views NUMBER PATH '$.views', claps NUMBER PATH '$.claps', rollup_date NUMBER PATH '$.timestampMs' )) AS "MEDIUM" GROUP BY to_char(TIMESTAMP '1970-01-01 00:00:00.000 UTC' + NUMTODSINTERVAL( MEDIUM.ROLLUP_DATE / 1000, 'SECOND' ), 'Month');
Ok, there’s a lot going on in here. Let’s break it down a bit.
FROM CHRIS_MEDIUM_STATS ch,The table, nothing tricksy here. BUT, for the JSON functions like JSON_TABLE, I need to use a table alias, and for that, I’ve chosen ‘ch’ – for Chris Hoina, it’s his Medium data afterall.
json_table(ch.json_doc, '$.value[*]'JSON_DOC is the column in our table where the JSON is being stored.
My JSON array named “value” so i refer to it as $.value[].
And I want to query all the items in the array, so I say [*].
COLUMNS (
upvotes NUMBER PATH '$.upvotes',
reads NUMBER PATH '$.reads',
views NUMBER PATH '$.views',
claps NUMBER PATH '$.claps',
rollup_date NUMBER PATH '$.timestampMs') I have multiple attributes in the JSON, I can pick the ones I want to use in my SQL query, and I can name them whatever I want. That epoch time notation, ‘timestampMs’ – I’m going to call ‘rollup_date,’ and for all these attributes I’m asking JSON_TABLE() to treat as NUMBERs.
)) AS "MEDIUM"We’re asking the database to treat our JSON as a table, and our table NEEDS a name – so we’re going to call it “MEDIUM.”
SELECT sum(MEDIUM.READS) total_reads, (count(MEDIUM.READS) + count(MEDIUM.CLAPS)) total_kudos,
to_char(TIMESTAMP '1970-01-01 00:00:00.000 UTC' + NUMTODSINTERVAL
( MEDIUM.ROLLUP_DATE / 1000, 'SECOND' ), 'Month') MonthMEDIUM.READS – that’s the $.reads value, and I’m doing a SUM() of that over ALL the items of the JSON array, via the [*].
I’m converting the milliseconds number to a date with a TIMESTAMP call and adding an INTERVAL to it – that’s the maths courtesy from StackOverflow.
And once I have that date, I’m converting it to a string, and asking for only the MONTH. I have less than a year’s data here so I don’t’ have to worry about the year. Running this gives me –
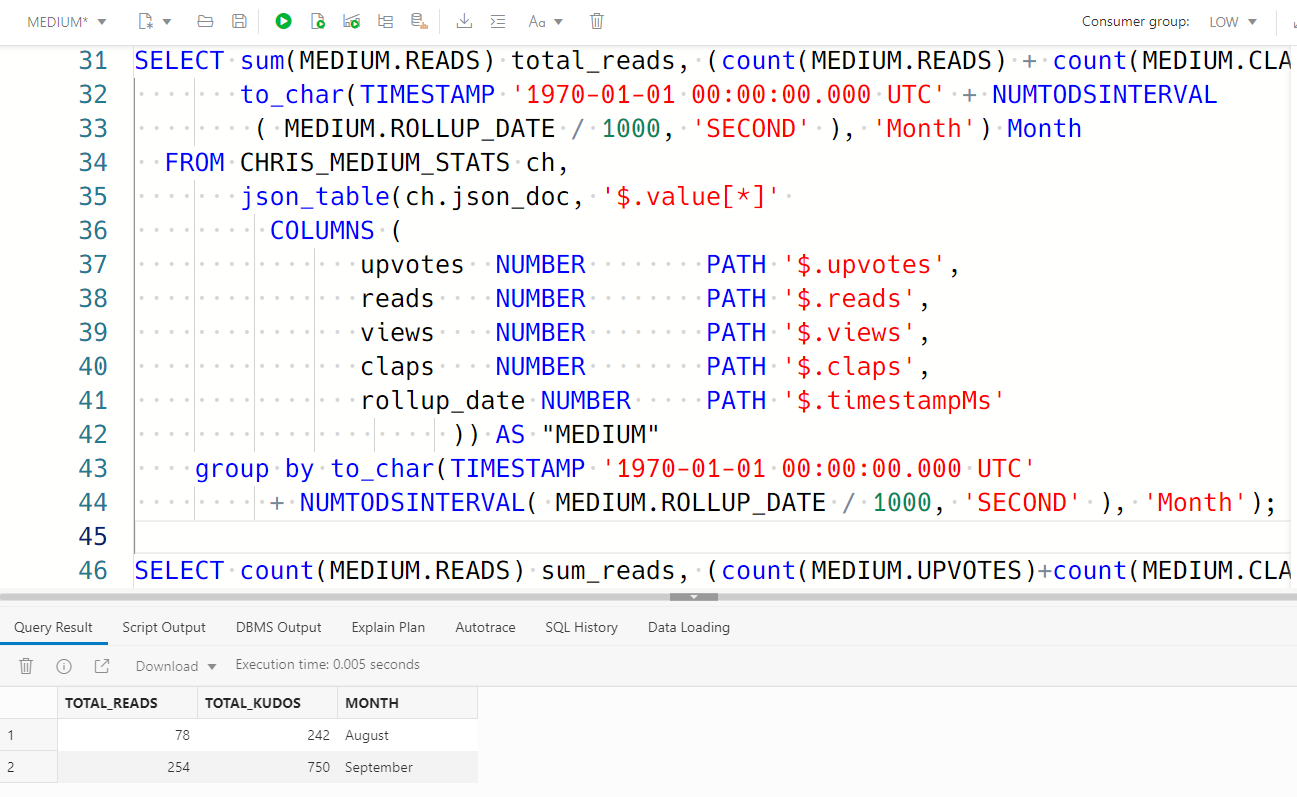
And the group by at the end, that’s just a repeat of the computed ‘MONTH’ column. Something to look forward to in Database 23c, we’ll have a new feature making this syntax SO MUCH EASIER.
But Jeff, my docs are split up as one per row in my table!
I find myself in this bucket more often than not. The good news is that querying this data is also pretty easy, and totally doable with SQL!
Awhile back I downloaded my Twitter history and uploaded it to my Oracle Database. It’s a very simple table, an ID column and a BLOB that’s used to store the JSON doc (the tweet!)
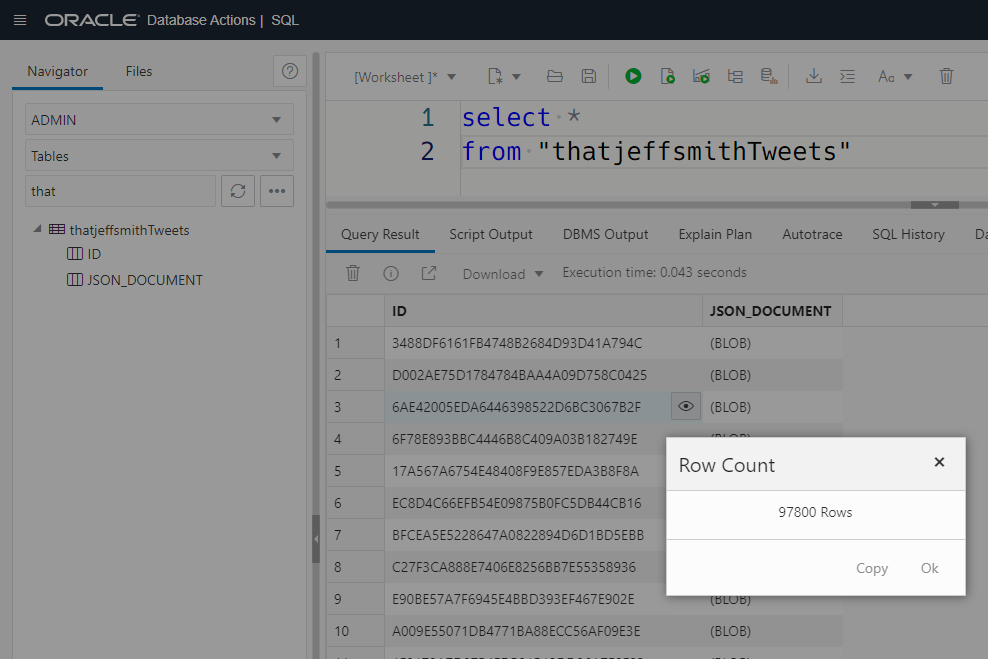
Now let’s peer into one of those JSON docs, and for that, I’m going to toggle over to my JSON workshop interface in SQL Developer Web.
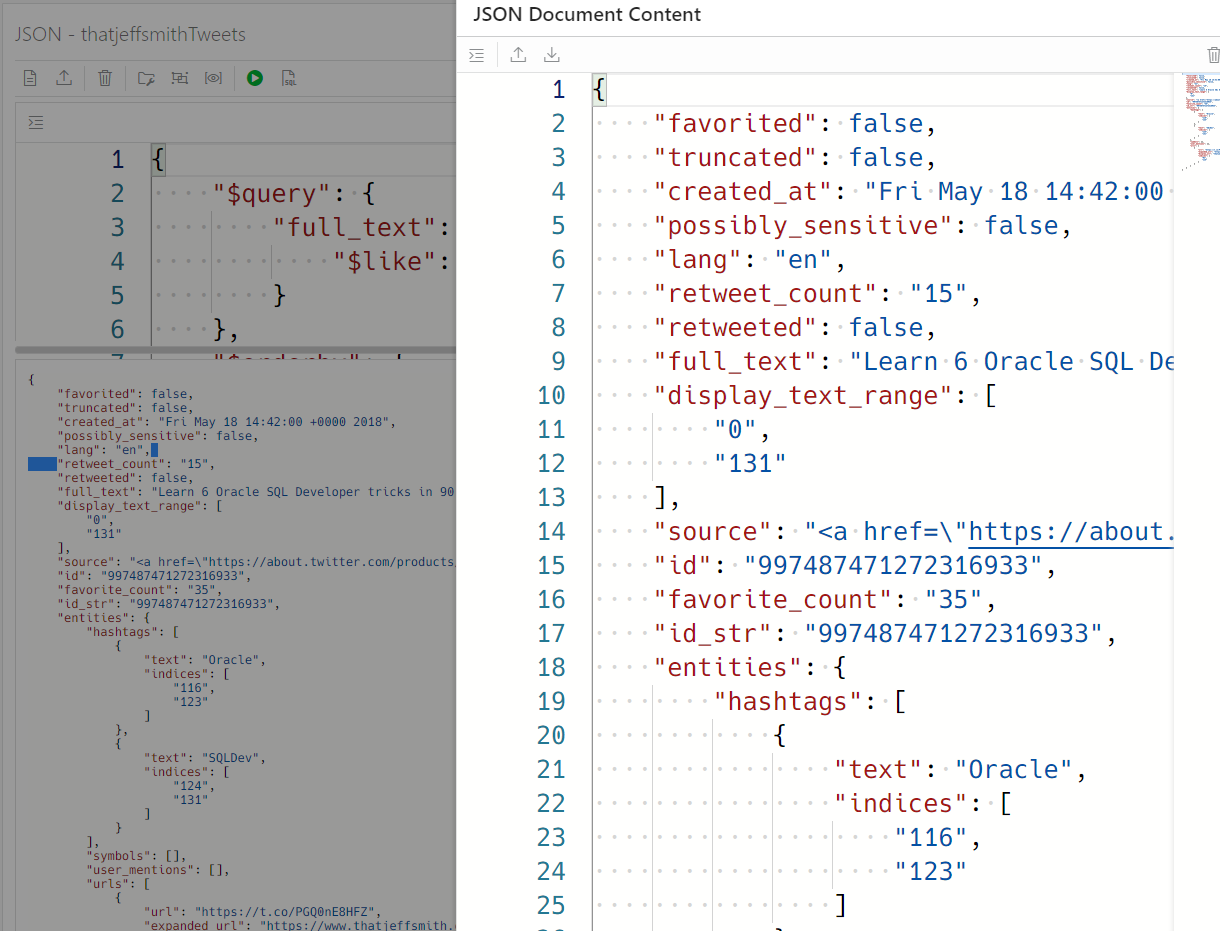
I can just query on that!
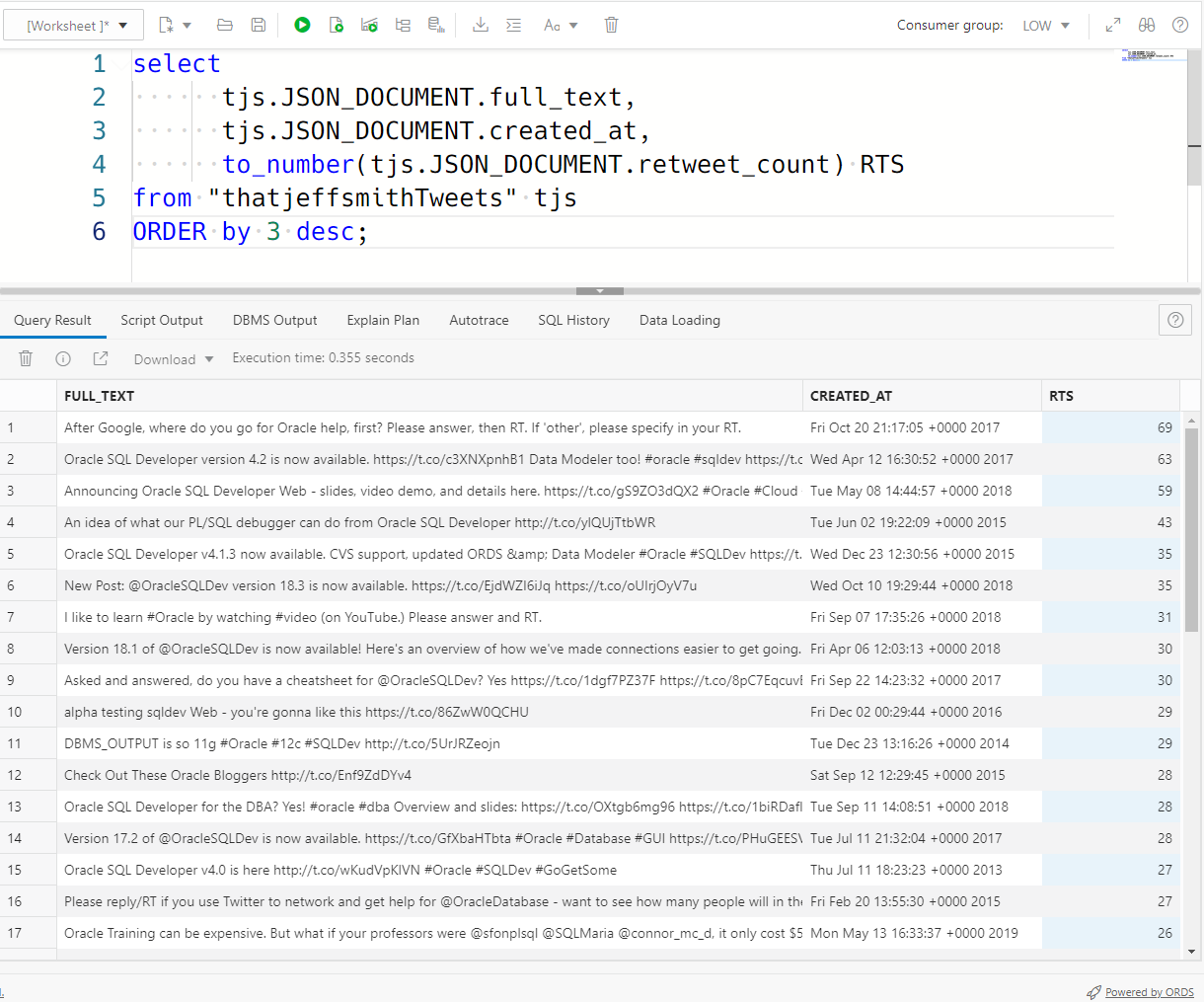
So let’s look at the code –
select
tjs.JSON_DOCUMENT.full_text,
tjs.JSON_DOCUMENT.created_at,
to_number(tjs.JSON_DOCUMENT.retweet_count) RTS
from "thatjeffsmithTweets" tjs
ORDER by 3 desc;What’s going on here?
For the simple DOT notation in my SQL, I HAVE to alias the table. And I went for tjs there.
Then the JSON doc is stored in a column called ‘JSON_DOCUMENT’, so everything in my SELECT will start with tjs.JSON_DOCUMENT.
And after that, I can just start into the attributes.
The top level attributes are pretty straightforward. By that I mean, they’re not in any objects or arrays.
What IS interesting is that by default, everything comes back as a VARCHAR2.
So I queried
to_number(tjs.JSON_DOCUMENT.retweet_count)
vs
tjs.JSON_DOCUMENT.retweet_count
Without the TO_NUMER(), sorting by that column (descending order), the first record that comes back has 9 RTs. Because ‘9’ comes after ‘6’ or even ’69’ when treated as text. So by doing a TO_NUMBER() on it first, the optimizer can then treat the column appropriately and I get back the results I want.
But wait, you might be saying to yourself…you didn’t TO_NUMBER() the stats in our earlier examples!
That’s right, but I DID do a COUNT() on the column. And doing that, the strings are implicitly converted to numbers.
Even more, more complicated JSON and SQL, keep going!
Yeah, Twitter keeps tracks of users mentioned, hashtags used, etc – so you don’t have to search the tweet text itself.
So check this out, further down my JSON doc (for my Tweet), I see this –
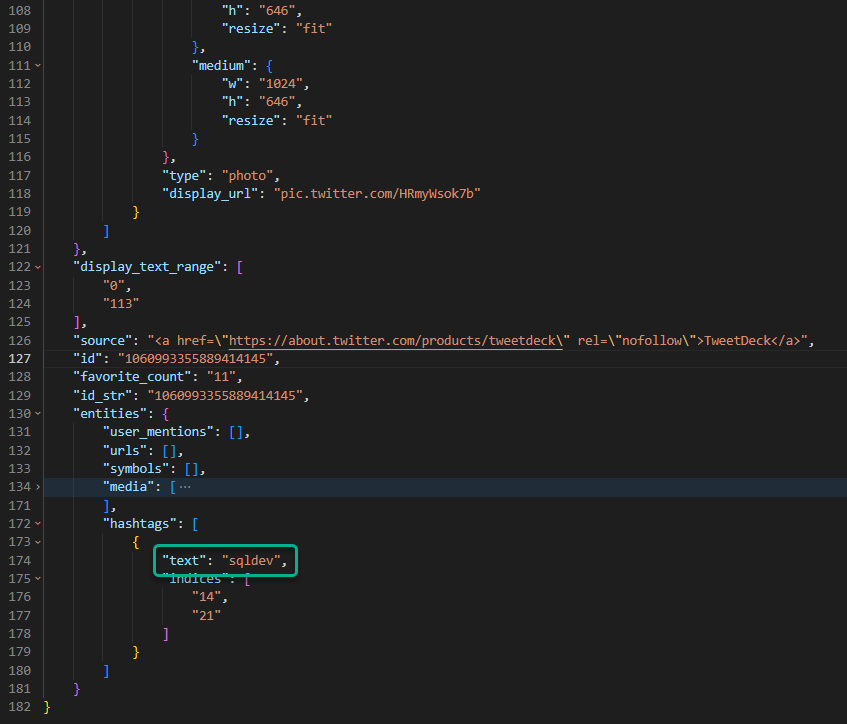
Well, how many times have I used that hashtag?
As of 2019, like 81 times.
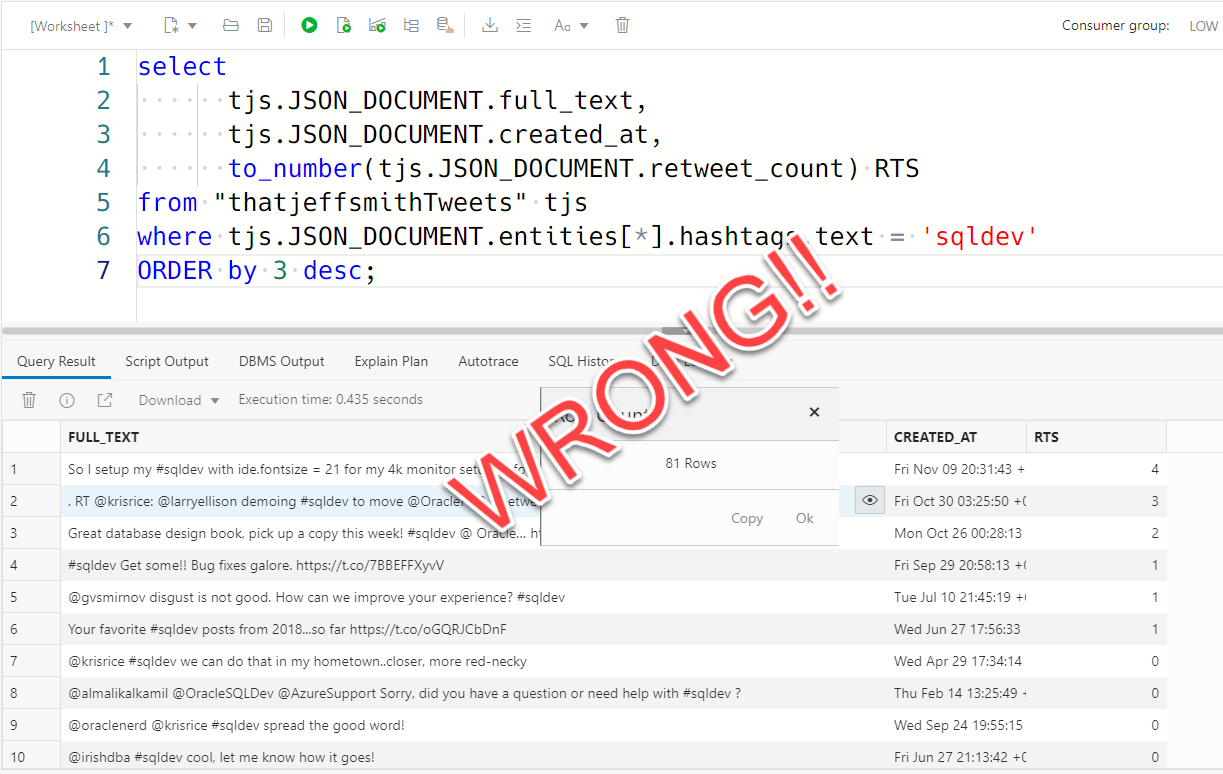
Just because you get results with SQL, doesn’t mean they’re right! It just means you got what you asked for. This is a ‘problem,’ with or without JSON! Let’s look at the query, again.
select
tjs.JSON_DOCUMENT.full_text,
tjs.JSON_DOCUMENT.created_at,
to_number(tjs.JSON_DOCUMENT.retweet_count) RTS
from "thatjeffsmithTweets" tjs
where tjs.JSON_DOCUMENT.entities[*].hashtags.text = 'sqldev'
ORDER by 3 desc;The simple, DOT notation expressions continue with my predicate clause –
where tjs.JSON_DOCUMENT.entities[*].hashtags.text = 'sqldev'That is saying where ALL of my hashtags are ‘sqldev’ – so the 81 results were where I only had 1 hashtag, that happened to be ‘sqldev’.
Now I KNOW my data. I know I should have more than 81 tweets with that hashtag. I often end my tweets with ‘#oracle #sqldev’ – so what If I choose [1] vs [*]?
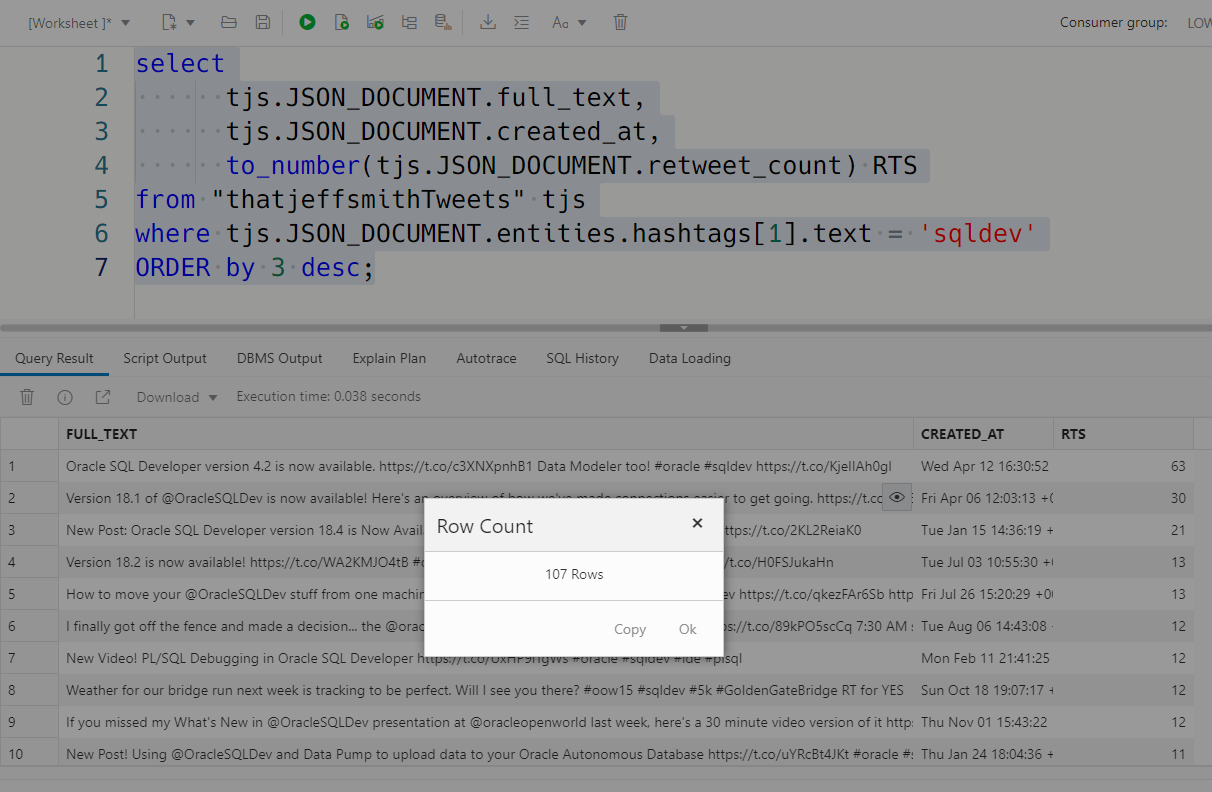
Well that’s better, I suppose. But I really don’t care which particular item in the array has that value, I just want to match on ANY document that has ANY occurrence of that tag.
To accomplish this, I searched the docs, and then I got a bit confused so I slacked Josh. I know, that’s cheating. But I was sniffing in the right area at least before I resulted to bothering a co-worker.
Josh reminded me to use JSON_EXISTS! BTW, Josh is a lead dev on the JSON team, and he’s great working with customers AND building great product.
Turns out that Beda had a blog on this topic, you can find it here.
I’ll show the right query and then talk about how it works.
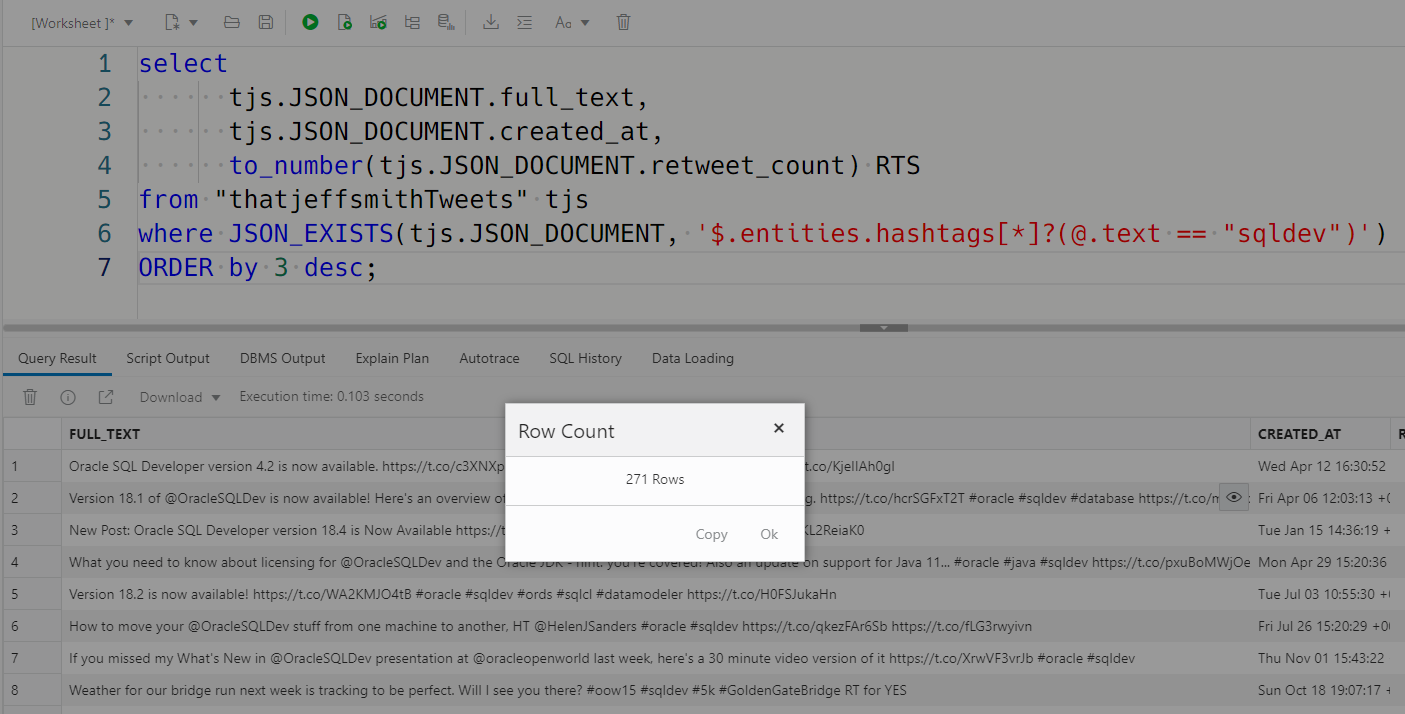
where JSON_EXISTS(tjs.JSON_DOCUMENT, '$.entities.hashtags[*]?(@.text == "sqldev")')JSON_EXISTS – a new function (Docs)
If you open that Doc link, you’ll see some examples.
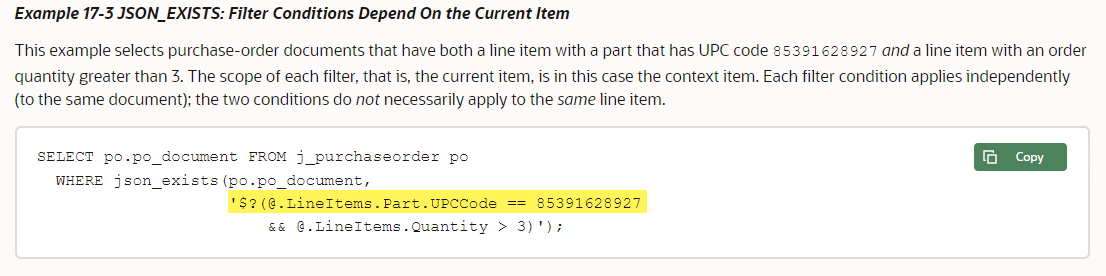
So for me, I’m using the entities.hashtags, again. But we’re looking into an array, and want to include all of the items, so [*] is appropriate. Now we’ll get a ‘hit’ so long as any of those items has a “text” attribute with a value of “sqldev”.
What about the ? and @ symbols? Beda explains in his blog post –
“The last query contains a predicate, this is expressed by using a question mark followed
by a Boolean condition in parentheses. The symbol’@’ denotes the current
context, i.e. the key/value pair selected by the path expression before the
predicate.”
Does it get more complicated than this? Maybe, but I’m guessing a majority of your use cases will fall into the simpler side of the bucket. And with practice, this becomes like second nature!
Why are you talking about this, Jeff?
Because I think it’s cool. Because I think I see a TON of customers using this technology, and I see lots of practical implementations of this with things like Oracle Database REST APIs!
I want more help with my JSON and SQL
Ok, how about some LiveLabs?