

When it comes to load data, especially very large amounts of data – if Data Pump is available, use that. If you can create an External Table, do that. If you have access to SQL*Loader, use that.
But.
Not only is that a lot of IF’s, there’s also the question as to how developer-friendly those interfaces can be, especially if you don’t live in an Oracle Database each and every day.
As a quick aside, I recommend you read Tim’s latest rant. By the way, he calls his posts rants, that’s not me ascribing a pejorative to the good Doctor. His post title pretty much says it all, The Problem With Oracle : If a developer/user can’t do it, it doesn’t exist.
The TL/DR; take is pretty simple – if the interface isn’t readily available AND intuitive, a developer isn’t very likely to use it. Or bother to take the time to learn it.
If you’re still with me, what I wanted to talk about today is the LOAD command in SQLcl.
Yes, I know it’s not as fast as SQL*Loader. And I’ve extolled the virtues of SQL*Loader before! But maybe you don’t have an Oracle Client on your machine, and maybe you lack the patience to learn the CTL file syntax and yet another CLI.
So instead, if you’re already in SQLcl and you simply want to batch load some data to a table, I invite you to check out the latest and greatest we’ve introduced in version 20.2 of SQLcl.
New for 20.2
- set load – # of rows per batch, # of errors to allow, date format, truncate before we go?
- set loadformat – CSV? are there column names in line 0/1? what’s the delimiter? “strings” or ‘strings?’
So while the LOAD command isn’t new, the amount of flexibility you have now is very much new. You’re no longer ‘stuck with the defaults.’
Let’s load some funky data.
We’ll throw in a date column, some weird string enclosures, no column headers, a blank line to start things…here’s what one row looks like
4|^|"US"|^|"Much like the regular bottling from 2012, this comes across as rather rough and tannic, with rustic, earthy, herbal characteristics. Nonetheless, if you think of it as a pleasantly unfussy country wine, it's a good companion to a hearty winter stew."|^|"Vintner's Reserve Wild Child Block"|^|87|^|65|^|"Oregon"|^|"Willamette Valley"|^|"Willamette Valley"|^|"Paul Gregutt"|^|"@paulgwine?ÿ"|^|"Sweet Cheeks 2012 Vintner's Reserve Wild Child Block Pinot Noir (Willamette Valley)"|^|"Sweet Cheeks"|^|436|^|08-JUL-2020 13.54.37
Yes, I have some wine review data – thanks Charlie for the heads-up!
So let’s setup our config for the run, starting with the profile of the data itself.
Our defaults aren’t going to cut it.
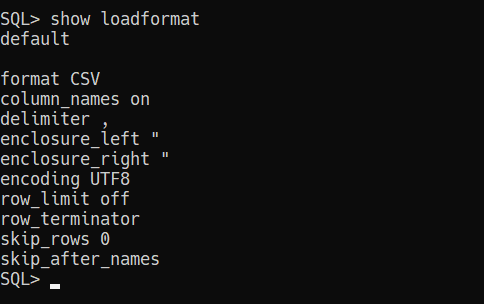
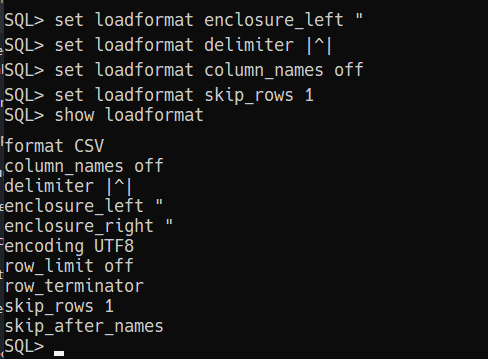
Now let’s look at the overall load settings.
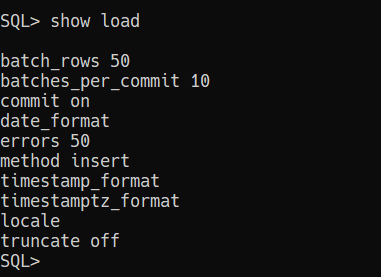
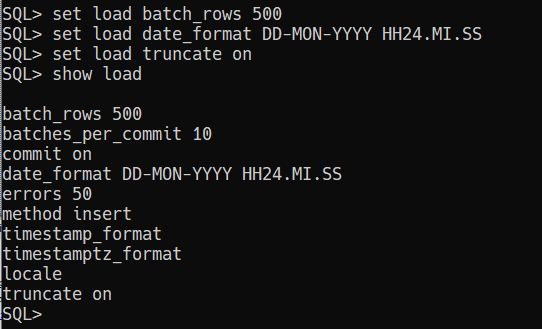
Let’s do this!
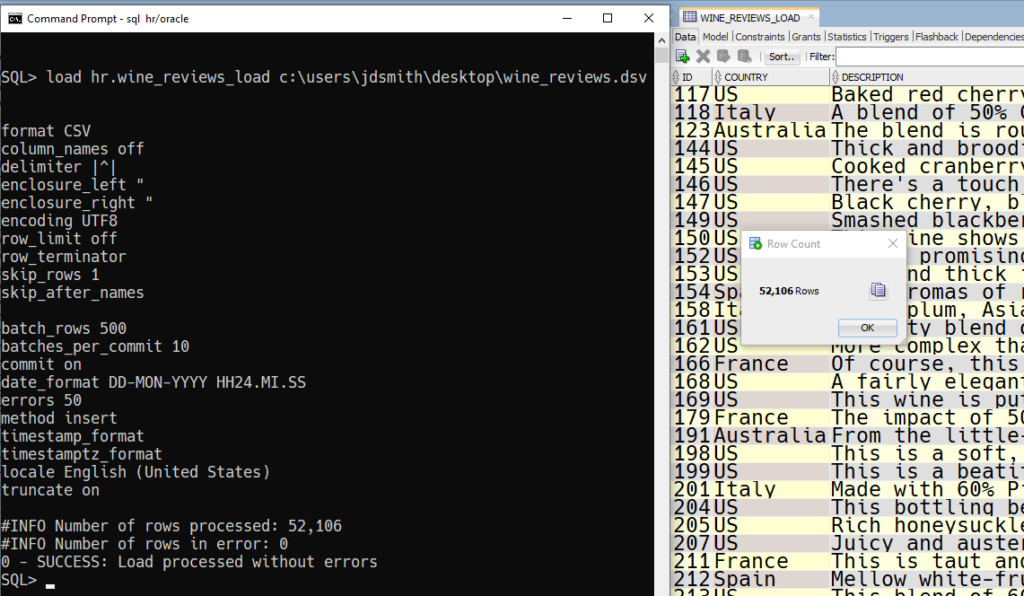
I actually got this to load the first time I tried! I’ll be having a cookie/beer later as a reward 🙂
Now, what if we did something stupid, like set batch_rows to 5? There may be a case where that makes sense, but not here, not for this scenario.
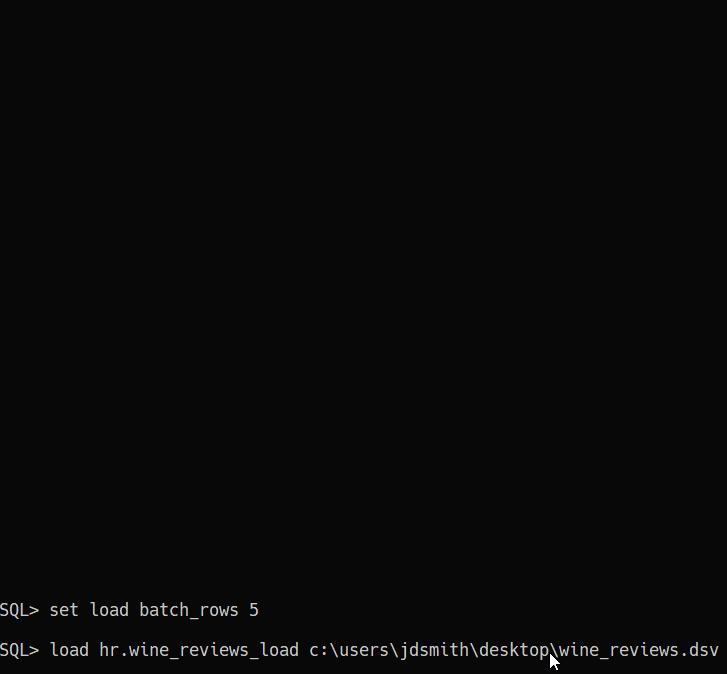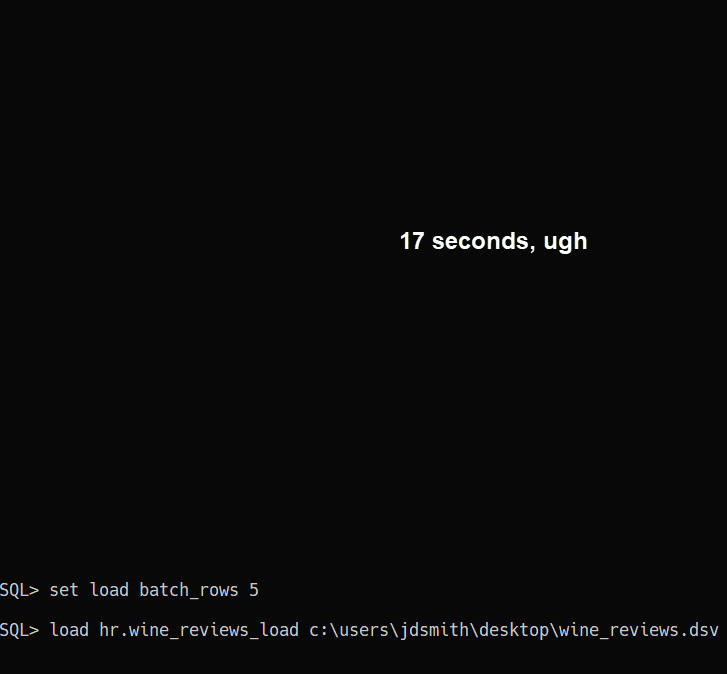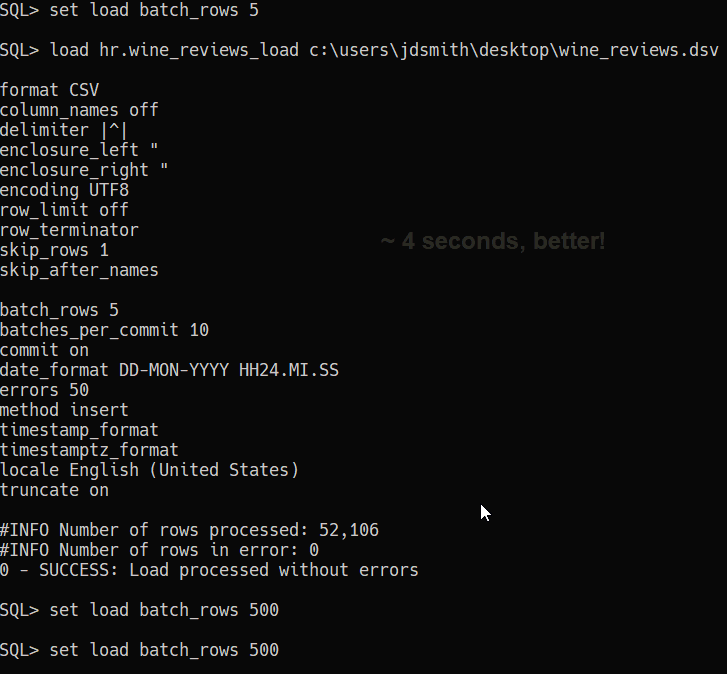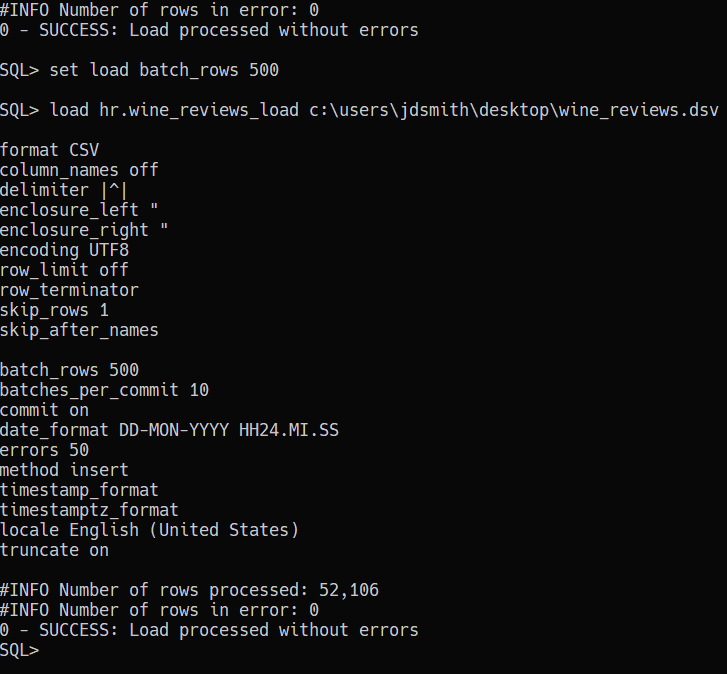
For quick and dirty data work, 50k rows in 4 seconds will do just fine. And nothing to install or configure, just unzip SQLcl and go. I’m pretty sure your average developer could use this interface and feature.
Trivia: This is the same code we use in…
…SQL Developer Desktop and ORDS. When you REST enable a table and use the batch loading POST endpoint, that’s running the same code SQLcl is using!




