
You may want to audit or ‘journal’ changes to your data.
As you update a record, add a record, or delete a record – log that change in a different table.
When doing your designs in the Data Modeler, you can ask at the time of DDL generation to have the journaling table and trigger created for one or more of your relational design tables.
Step One: Hit the DDL button.
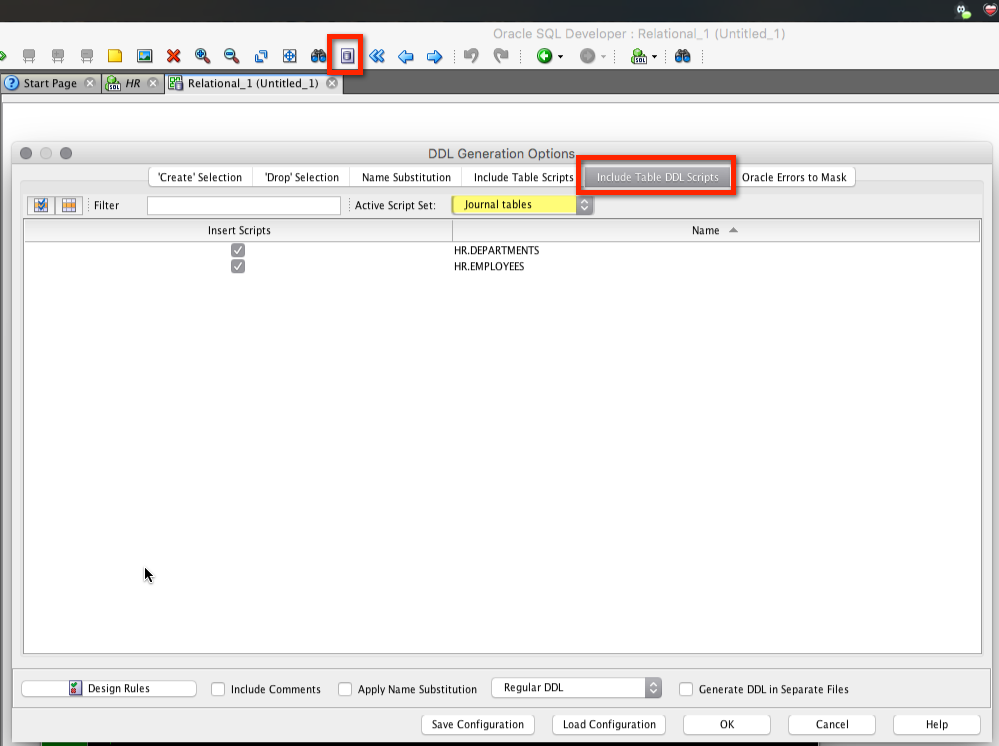
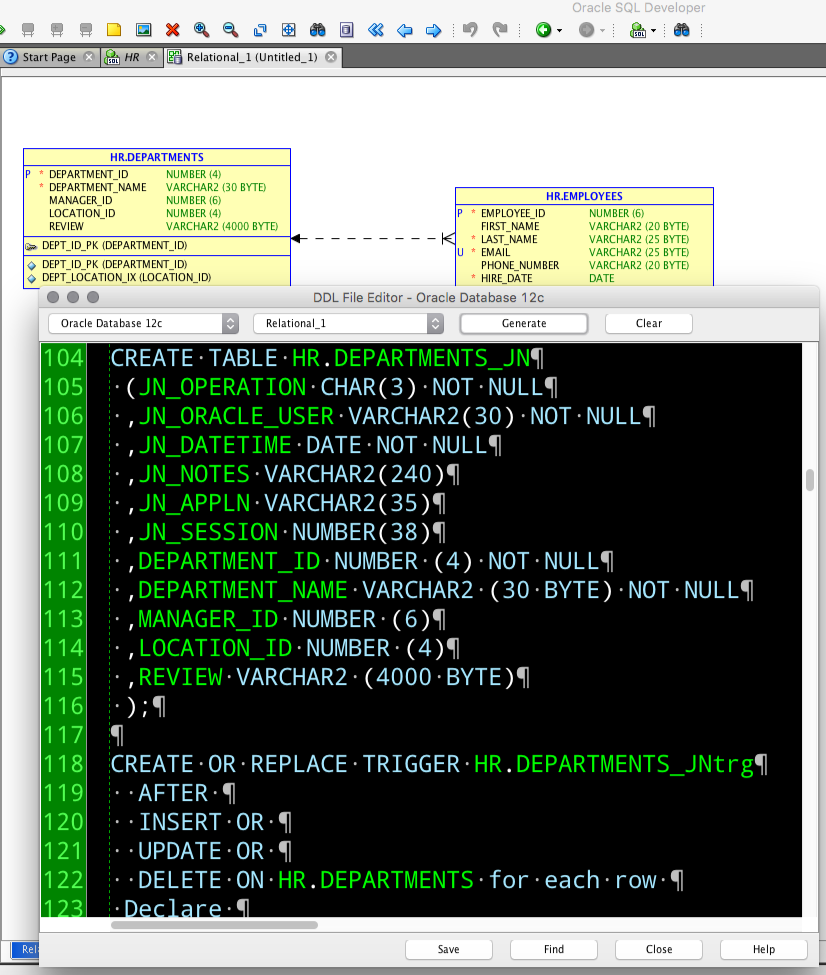
For each table, you’ll get the journal table and the trigger to populate said table.




10 Comments
Hi , I need to generate Journal DDL s cript for the Oracle tables, I followed the instructions, however I am unable to see the Active Sript set now showing Journal tables, in my Oracle SDDM.
I am using Oracle SDDM Version 22.2.0.165 Build 165.1149
Is there any option to enable Active Sript Set, please let me know.
Thank you,
Mahalengam Arumugam
Please post your modeler question to the SQLDev forums
Two words, Total Recall.
Transparent, efficient & declarative (as opposed to triggers being programmatic).
Hi Jeff,
What’s the way to generate a trigger named with an other pattern ?
Typicaly, we’re working with naming convention waiting a ‘myTable_JN_TR ‘.
This point is available for other generated DDL’s : proc, functions and so one.
Thanks by advance.
Ernest.
It’s all based on templating. You can define them here
It is easier to manage. That table has flag column (TABLE_NAME). I just would like to get your inputs on this scenario.. especially it enable the end user to see old value next to the new value easily.
Not to mention that the code generated by SQL modeler saves too much info without a need.
If I change only one value e.g., password column, then the values of all columns of that record are going to be stored / logged. e.g.,
CREATE OR REPLACE TRIGGER USERS_JNtrg
AFTER
INSERT OR
UPDATE OR
DELETE ON emp2 for each row
Declare
rec USERS_JN%ROWTYPE;
blank USERS_JN%ROWTYPE;
BEGIN
rec := blank;
IF INSERTING OR UPDATING THEN
rec.ID := :NEW.ID;
rec.PARENT_ID := :NEW.PARENT_ID;
rec.USER_NAME := :NEW.USER_NAME;
rec.PASSWORD := :NEW.PASSWORD;
rec.FIRST_NAME := :NEW.FIRST_NAME;
rec.LAST_NAME := :NEW.LAST_NAME;
You could create your own template. We provide this one as an example. But having all tables share a journalling table seems more complex to me. And you’ll be storing data in non-native data types. I’d rather have my old dates stored as dates, not in a varchar2(4000) string, WHICH btw, might not be big enough to store your changes.
Nice, since this is auto generated, I suppose that this is the best practice. However, in case we need only to log the changes, how about having only one Journaling / History Table to track all updates e.g.,
———————————————————————
CREATE TABLE “HISTORY”
( “TABLE_NAME” VARCHAR2(300),
“COLUMN_NAME” VARCHAR2(30),
“OLD_VAL” VARCHAR2(4000),
“NEW_VAL” VARCHAR2(4000),
“UPDATED_BY” VARCHAR2(30),
“UPDATED” TIMESTAMP (6),
“ROW_ID” NUMBER
)
———————————————————————
——–To be populated through a trigger that calls a package. e.g.,
create or replace TRIGGER “AUD#CLIENT”
before update on CLIENT
for each row
begin
audit_pkg.check_val( ‘CLIENT’, ‘FIRST_NAME’, :old.id ,:new.FIRST_NAME, :old.FIRST_NAME);
audit_pkg.check_val( ‘CLIENT’, ‘LAST_NAME’, :old.id ,:new.LAST_NAME, :old.LAST_NAME);
audit_pkg.check_val( ‘CLIENT’, ‘MOBILE1’,:old.id , :new.MOBILE1, :old.MOBILE1);
audit_pkg.check_val( ‘CLIENT’, ‘DEPT_ID’,:old.id , :new.DEPT_ID, :old.DEPT_ID);
………
———————————————————————
—- The below is a procedure is within an overloading package based on the datatype.
procedure check_val(
l_tname in varchar2,
l_cname in varchar2,
l_row_id in number,
l_new in varchar2,
l_old in varchar2 )
is
begin
if ( l_new l_old or
(l_new is null and l_old is not NULL) or
(l_new is not null and l_old is NULL) )
then
insert into HISTORY
(TABLE_NAME, COLUMN_NAME, ROW_ID ,OLD_VAL, NEW_VAL,UPDATED , UPDATED_BY)
values
( upper(l_tname), upper(l_cname), l_row_id , l_old, l_new,LOCALTIMESTAMP , NVL(v(‘APP_USER’),USER) );
end if;
end;
———————————————————————
This way, we can easily see the old Vs new values for every change. But this requires a function for each FK column to return, in our case, the DEPT_NAME. e.g., the report query should include:
…..
Case when COLUMN_NAME = ‘DEPT_ID’ THEN GET_DEPT (OLD_VALUE) ELSE OLD_VALUE END AS OLD_VALUE ,
Case when COLUMN_NAME = ‘DEPT_ID’ THEN GET_DEPT (NEW_VALUE) ELSE OLD_VALUE END AS NEW_VALUE
…..
Where GET_DEPT is a simple function that retrieve s the DEPT_NAME .
Could you share your thoughts on that ?
Why only one table?
For inquiries as
What has been changed by a user/process ?
What has been changed at a time ?
Where has the value been used ?