
Have you heard of Oracle Designer? Perhaps you even still use it?
Designer incorporates support for business process modeling, systems analysis, software design and system generation.
I don’t want to get you too excited, because this technology is being phased out. You can read the official statement of direction here, but but going forward we’re recommending you use JDeveloper, Fusion, and our other middleware technologies to build your applications.
What I want to get to, is a very frequently asked question from Oracle Designer customers who are starting to use Oracle SQL Developer and Oracle SQL Developer Data Modeler:
How Can We Get Our Table APIs?
One of the Oracle Designer features was the ability to create PL/SQL packages that handled your SELECTs, INSERTs, UPDATEs, and DELETEs for your tables. My colleague Chris Muir had this to say a few years ago about the feature:
Not only can Oracle Designer generate Oracle Forms, but it can also create a set of packages to wrap specified schema tables, known as the Table Application Programming Interface (Table API). The packages allow the calling program to indirectly select, insert, update, and delete the relating table data through the Table API PL/SQL packages.
So, the good news is that we can mostly do this in SQL Developer, mostly.
Just find your table in the connection tree, right-click, and ask for the code to be generated.
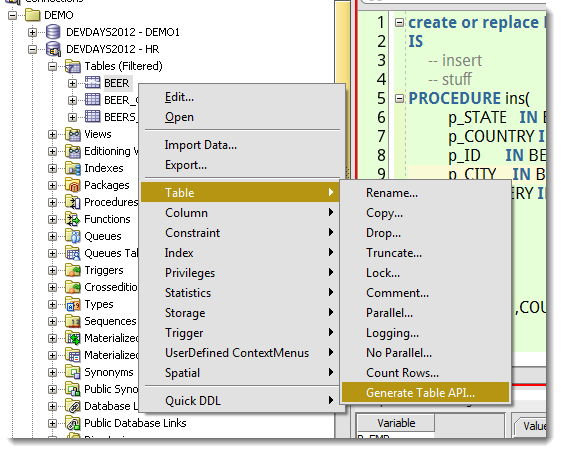
What gets ‘spit out’ is a PL/SQL package with 3 procedures:
- INS
- UPD
- DEL
Notice there’s no ‘SEL,’ hence my mostly qualifier.
Here’s the actual code generated for my BEER table:
CREATE OR REPLACE PACKAGE body BEER_tapi IS -- insert -- stuff PROCEDURE ins( p_STATE IN BEER.STATE%TYPE DEFAULT NULL , p_COUNTRY IN BEER.COUNTRY%TYPE DEFAULT NULL , p_ID IN BEER.ID%TYPE DEFAULT NULL , p_CITY IN BEER.CITY%TYPE DEFAULT NULL , p_BREWERY IN BEER.BREWERY%TYPE ) IS BEGIN INSERT INTO BEER ( STATE ,COUNTRY ,ID ,CITY ,BREWERY ) VALUES ( p_STATE ,p_COUNTRY ,p_ID ,p_CITY ,p_BREWERY ); END; -- update PROCEDURE upd ( p_STATE IN BEER.STATE%TYPE DEFAULT NULL , p_COUNTRY IN BEER.COUNTRY%TYPE DEFAULT NULL , p_ID IN BEER.ID%TYPE DEFAULT NULL , p_CITY IN BEER.CITY%TYPE DEFAULT NULL , p_BREWERY IN BEER.BREWERY%TYPE ) IS BEGIN UPDATE BEER SET STATE = p_STATE ,COUNTRY = p_COUNTRY ,CITY = p_CITY ,BREWERY = p_BREWERY WHERE ID = p_ID; END; -- del PROCEDURE del( p_ID IN BEER.ID%TYPE ) IS BEGIN DELETE FROM BEER WHERE ID = p_ID; END; END BEER_tapi;
A Final Word On Oracle Designer
While Oracle SQL Developer and Oracle SQL Developer Data Modeler will do many of the things Designer did, they will never do EVERYTHING Designer did. So we can help you move off Designer, but don’t expect the SQL Developer family to be complete replacement. In terms of the Designer ‘designs’ – these can be largely imported into new Oracle SQL Developer Data Modeler models. We’re always tweaking the import logic to add more and more support for Designer artifacts. Version 3.3 of the Modeler did quite a bit of work in this area specifically.



29 Comments
One of the Fashioner TAPI arrangement that gets neglected when taking a gander at SQL Developer is the capacity to rapidly and effectively produce Journal(audit) data on a table. It is safe to say that you are mindful of any answer for having the capacity to create review on tables like Fashioner enabled us to do before?
What is Fashioner?
And yes, we can do that, in the Modeler.
For crying out loud, Jeff. That “TAPI” that SQL Dev generates is nothing!
NOTHING! There was real, useful functionality in the Designer TAPI packages and triggers. I’d barely even call what SQL Dev produces a place to start. Oracle should be embarrassed, EMBARRASSED to provide that feature and ask us to think they’ve given us something.
It is a damned shame Oracle abandoned the Forms and Designer technology like they did. SQL Developer, as much as I like it, isn’t much more than a GUI for SQL*Plus. And JDeveloper doesn’t come much closer to replacing what was lost with Forms and Designer.
I’m glad I work on the back end with computers. If I had to pound away for 8 hours a day using some Java or ADF application, I’d go insane. The technology may (MAY) be useful for creating one-off applications, or consumer-facing apps that people use for 10 minutes at a time. But for making a tool to be used all day long? Shoot me before you make me work like that.
Yes, Designer is gone. I wouldn’t say that SQL Developer is a replacement for Designer, although with the modeling component there are several gaps being filled.
You say that having a GUI for SQL*Plus isn’t much, but billions of dollars have been generated by companies making tools that are nothing but that – and they are used by millions of users around the world.
I hope they are at least happy.
You’re not. So, let’s work together to get you to happy.
Did you know you can build your OWN code in SQL Dev?
If you don’t like our table APIs, then build your own. You just need to know a little bit of XML and SQL, and away you go.
I won’t shoot you. But I am listening.
Show me what you’d like your table APIs to look at, and I’ll see what I can do.
One of the Designer TAPI solution that gets overlooked when looking at SQLDeveloper is the ability to quickly and easily generate Journal(audit) information on a table. Are you aware of any solution to being able to generate audit on tables like Designer allowed us to do in the past?
No, but if you look at the Flashback tab of your table editor, you can see all of the data changes – back however far you have Flashback configured.
Flashback if I understand it correctly is mainly used for recovery purposes. The situation I am talking about is Journalling on a table. It will show me all changes to a row of data. Flashback is also limited to the amount of Undo that you have… at some point flashback gets destroyed. The journal feature in Designer inserts a row whenever the table is inserted , updated or deleted. It is a mirror of the table and thus allows for a user interface to extract the data. Flashback requires DBA permission (at least in our org it does) which is not a viable option.
Yes, but check out Total Recall.
You could probably create a transformation script you can run to handle the table and trigger creation for your tables – you might want to create a classification type to label those tables you want journaled. It’s possible, you just need to code it.
So Build (tnansformation scripts) vs Buy (Total Recall). I’m betting someone out there has already built something along these lines too…
The order of the columns is not the same as the actual order in the table. How can I generated the code with all the columns in the order they appear in the table? My table has more than 100 columns and the generated code has these columns all over the place, not exactly in the order in which they appear in the table.
Thank you.
Why does it matter? You can make your package calls with the inputs in any order you want…
It does matter, I think. If the package is expecting for example, a date field as the first column and I send in some other field, it will fail. Also for trouble shooting, the table column order is a ready reference to go through all the values, esp. since there are more than 100 columns. Thanks for the immediate reponse albeit your busy schedule!
While you can send arguments to your package w/o naming them, letting the order define what is what, that’s not good practice. You should probably be sending it it via this style
[sql]
begin
package.procedure(arg1 => 25, arg2 => 35, extra => ‘ABCD’, … arg100 => sysdate);
end;
/
[/sql]
This way neither you nor the database has to guess what you’re trying to pass to the program!
Thank you.
It does matter when you’re executing the package using ODP.Net. The default behavior for adding parameters to the OracleCommand requires to be in a specifc column order, which in our case is by design the order of the fields in the table. When the table API creates the columns in a random order, we have to fix that positioning before we create the package.
Again, we love the tool, but to say it doesn’t matter is not accurate for many reasons.
It matters if you’re stuck with the default behavior for ODP.Net and OracleCommand I guess…
I’m guessing the order is determined by how they are returned when querying them from all_tab_cols – we don’t have an ORDER BY in the query to get the column list.
I think that’s correct. I watched the statments log during the generation and it looks like it’s just the select without the order by:
select * from all_tab_columns
where owner = :OBJECT_OWNER
and table_name = :OBJECT_NAME
Jeff,
Why not just use the Column Order to generate the TAPI in that order. Also, can you please point me to any links about how to write our own code to generate these TAPI’s.
Thanks
Sriram
easiest way to build your own, script it SQLcl with javascript and some SQL…see Kris’ blog to get an idea of what’s possible.
Why did Oracle freeze Designer in the first place? It was an OUTSTANDING tool.
You’re asking the wrong person, but ‘freeze’ is probably not a harsh enough word. End-of-life is more accurate. It’s dead. Time to move on.
Are you sure you are a “Manager” at Oracle?
You do not seem to be too “customer oriented”…
I try to be nice, but if you’re too nice, people don’t get the message. We get tons and tons of designer folks wanting us to be designer. We do our very best to help them. But we’re not designer.
Good information
So back to my question to Kris Rice at KScope11 – why is this API functionality not exposed in Data Modeler too? It could at least be an option on the DDL generator.
Nice, it saves lots of typing, especially for tables with lots of columns. However, there is no exception block. Kind of important for DML operations.
The problem is that these TAPIs are not as good as the TAPIs that were generated by Designer. See my blog entry at http://it.toolbox.com/blogs/jjflash-oracle-journal/on-table-apis-41918 for a more complete explanation of why. The main objections: This interface has one parameter per table column, making it inflexible for when you add a new column to the table. And it uses EVERY parameter in its inserts and updates – if a call doesn’t use a column, it defaults to NULL. This is not too bad for INSERT but terrible for UPDATE, when you might want to leave a column unchanged – NOT set it to NULL.
The main reason I blogged this topic today was that it’s been in the tool for a very long time, and I wanted to expose it and spark some dialog – so thanks for your feedback.
I mostly agree around the UPDATE and NULL stuff. Having a similar conversation with someone on Twitter now about that, although one could require/assume that the ‘user’ would always have/know those existing values when they make the UPD call. I don’t like that though – unnecessary & extra work for the database.
About extra columns – if your data model changes, I’m going to guess your application is going to have to change too. And if you’re using generated APIs, why not just re-generate them?
I don’t want to shut you down though, just thinking out loud. And I hope others respond and share their requirements. I think ‘fixing’ this would be pretty easy and straightforward.
To Jeff’s question about “if you’re using generated APIs, why not just re-generate them?”
Given how simple these are, I would expect to customize them. So regenerating would lose those customizations.
The APIs are certainly easier to call with explicit parameters for each table field vs having to create a record type in your calling procedure to hold the values. There’s definitely good points to both sides of the argument.
Cool! 🙂