
The question:
We have big database with a lot of stuff and I want to use version control (Git) to manage changes. There are a lot of articles how to do it step by step but one piece is missing for me. Is there standard or recommended way for file structure of whole database (data excluded) and how it can be obtained from existing database?
So I’m not sure about standard or recommended, but we do have a few tools for you to take advantage of.
I realized I had ONLY talked about the Cart previously – which is good for taking a subset or handful of objects, and loading to scripts. But this person wants the entire schema.
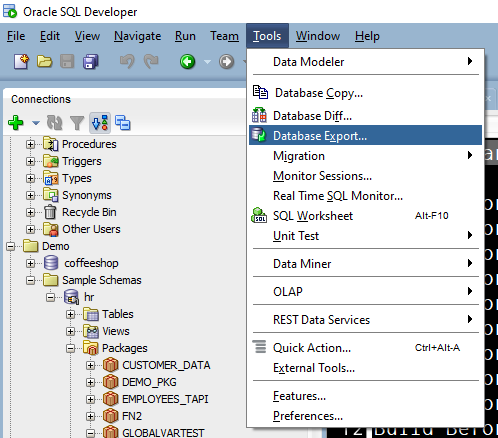
So let’s look at the Database Export Wizard, under the Tools menu.
Step 1: Your Connection
The easiest way to walk this is to login AS the schema you want to unload. I’m going with HR.
Then proceed to the tools menu.
Step 2: The Most Important Part, the Options
Two things to consider here – what types of objects do you want, and how do you want the output generated.
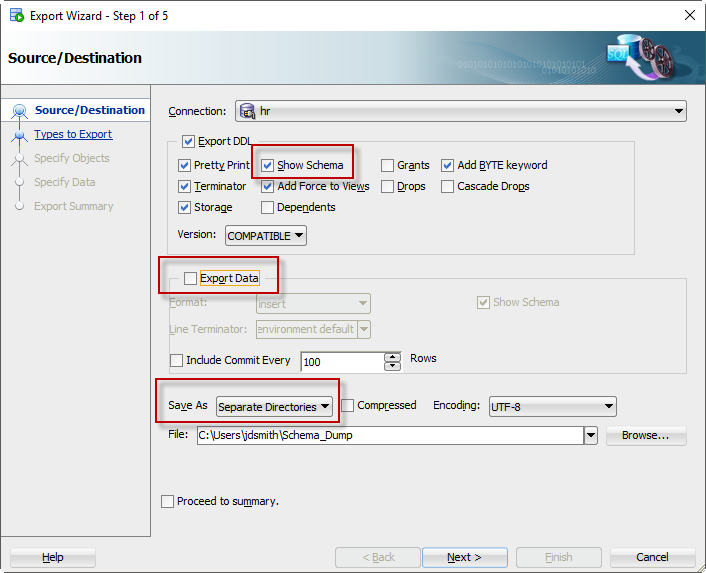
- Show Schema – do you want to see CREATE TABLE HR.TABLE1 or do you want to see CREATE TABLE TABLE1?
- Export Data – you probably do NOT want the data included as INSERT statements – unless these are lookup tables
- Save As – I have mine set to SEPARATE DIRECTORIES, so I will get a directory for each schema object type
Adjust according to your needs.
I could click ‘Finish’ here – as I am EXPORTING EVERYTHING in my schema. But if you don’t want everything, you could go to the next screen to use the Object Selector to say exactly what you want to export.
And GO!
The Results
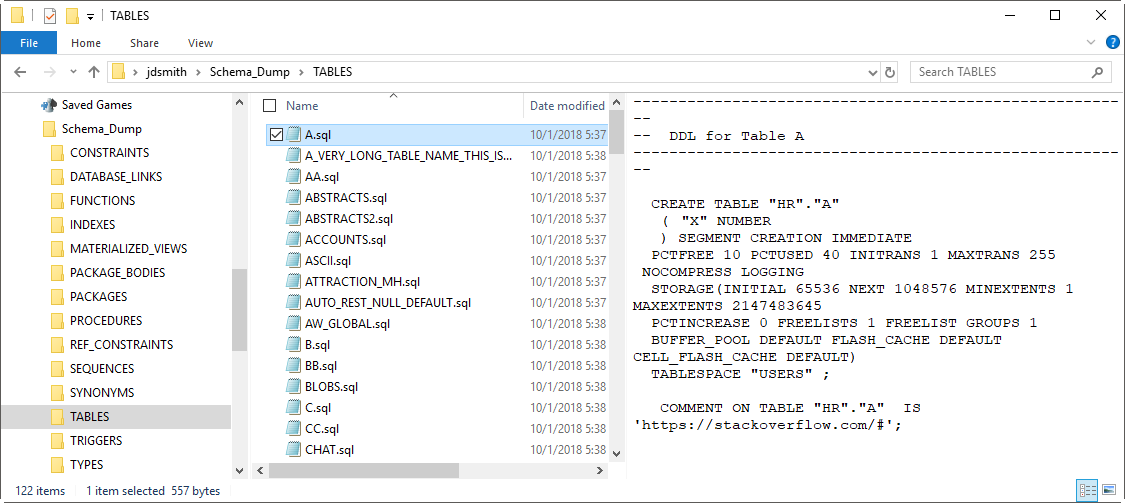
Let’s look at two files.
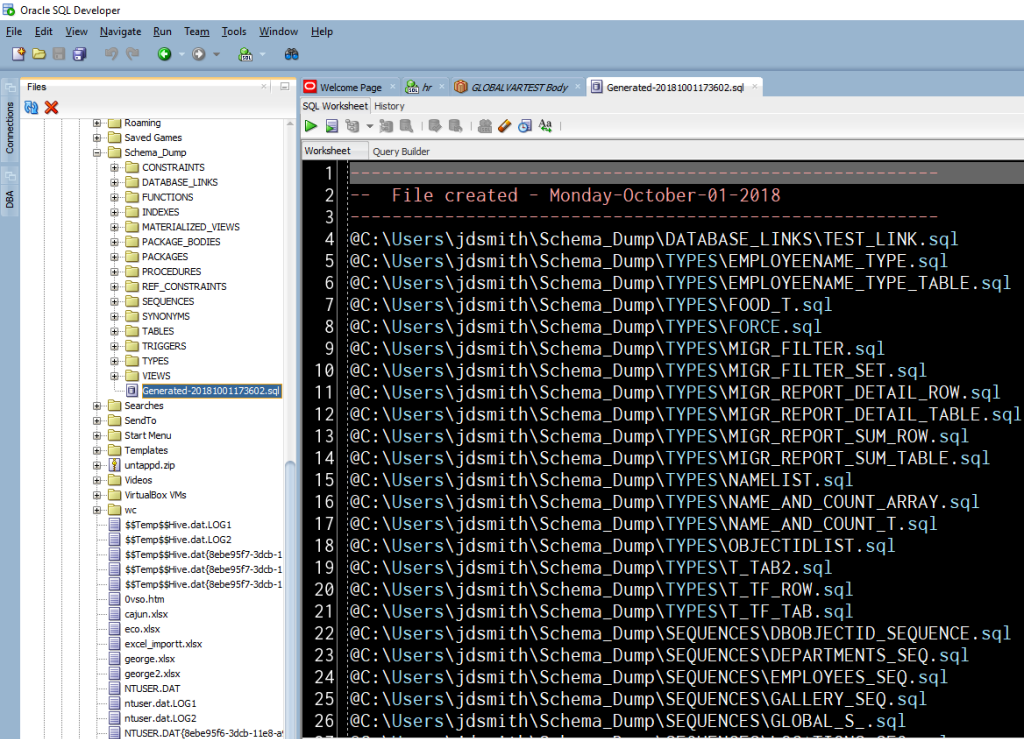
First a sample, generated file.
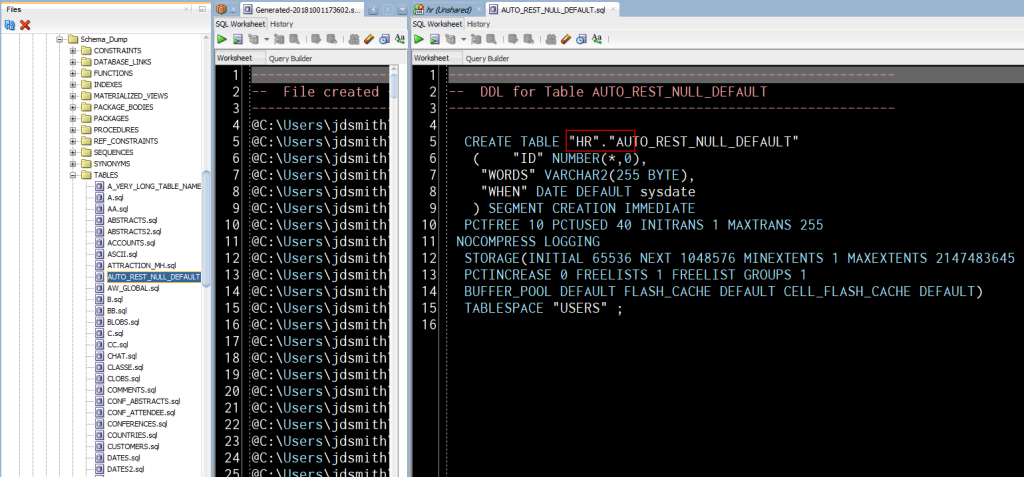
And there’s also a ‘master’ file in the root output directory.
You could run this script to kick off all of the generated files from our Wizard session.
Don’t Like GUIs?
You could do this in SQLcl with some JavaScript, courtesy @krisrice.




7 Comments
Hi,
sorry for responding to this old tip/manual.
Is there a preference where you can set the extension per object instead of all named .sql?
So all prodcedures .prc and functions .fun, etc.
Thank you
Great script with SQLcl . Strangely but I get only index, materialized view and materialized view exported. Why this? I see in the script there is a special treatment of packages and procedures, maybe that prevents exporting all object types? Sorry but my JavaScripts is very limited to understand what is wrong.
This is really well explained, but how can I manage DDL changes. Say I exported my database and my changes are pushed to remote repository. If I go and make some table changes, create a column or update a table in any way. How can we manage that through source control?
Do I have to export those changes from database again? Or is there a way source control detects those changes?
By the process mentioned here, I know we are manage source control in files and not directly the database itself. How is this achievable?
Most folks would take the opposite approach from what you’re describing.
They would go from doing development in their files, to pushing those to a database. Vs doing work in the database, and trying to get the work out as files.
We tried This approach however the insert script fails to load the lob data for a lob column
Also, we have to manually arrange the insert scripts to avoid referential constraints error
Please help with your suggestions for those issues
Source controlling application data is a thing, but LOBs makes everything more interesting.
You’ll need to switch your data format to SQL Loader, then you’ll be good to go.
This also means when you deploy the data, it’ll be done with SQL Loader.
Thanks.
We use this extensively. However, We need to modify further to make it re-runnable I.e. at the start add a check to see if table exists and drop (based on various conditions e.g. is table empty) .
Also, we have other parameters like “ENABLE ROW MOVEMENT” compression etc.
Also, as we use continuous deployment we also have a diff mechanism to generate alter scripts. We used schema comparator and are reviewing the same or this use case.
All in all a life saver feature.
Thanks,
Vikram R.