
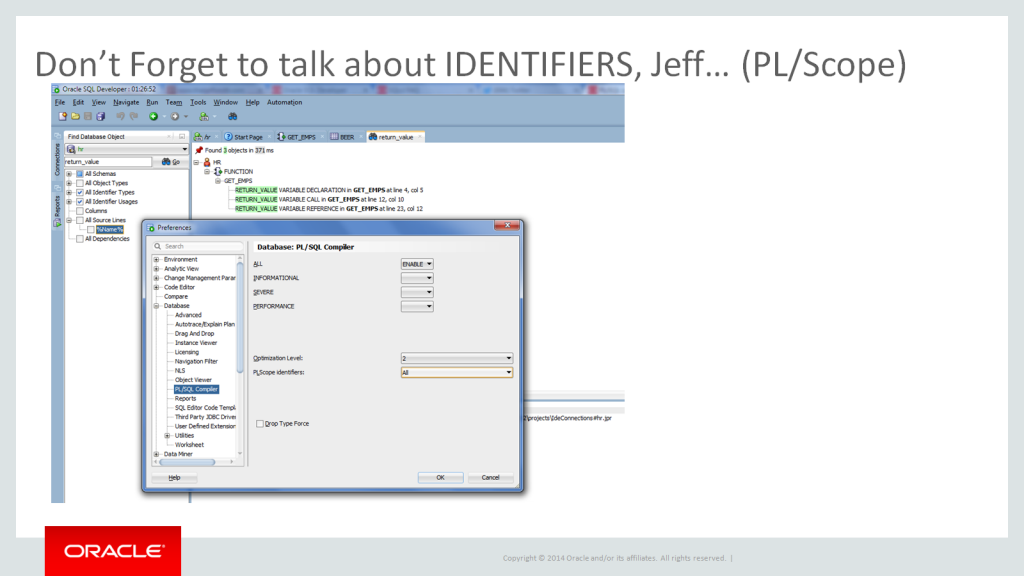
The PL/SQL team is always reminding me to talk about PL/Scope. And I got to the point where I needed to remind myself, so I added this slide in all of my PL/SQL themed talks. Yet, I have apparently forgotten to blog about it. Oops.
[Docs] PL/Scope is a compiler-driven tool that collects data about identifiers in PL/SQL source code at program-unit compilation time and makes it available in static data dictionary views. The collected data includes information about identifier types, usages (declaration, definition, reference, call, assignment) and the location of each usage in the source code.
PL/Scope lets you develop powerful and effective PL/Scope source code browsers that increase PL/SQL developer productivity by minimizing time spent browsing and understanding source code.
PL/Scope is intended for application developers, and is usually used in the environment of a development database.
So, the basic gist is, instead of searching your PL/SQL source code looking for every occurrence of ‘X’ – and having to parse the source code yourself, at compile time, PL/Scope will find your identifiers and put them in an easy place for you to query.
So, when someone decides to change what ‘X’ is, it’s very easy for you to see the impact of this change throughout all of your PL/SQL.
The other benefit is that it’s just plain faster to search the PL/Scope views than it is to go try to brute-force your way though ALL_SOURCE.
Of course, SQL Developer supports this.
Step One, make sure you’re asking for the PL/Scope information to be collected.
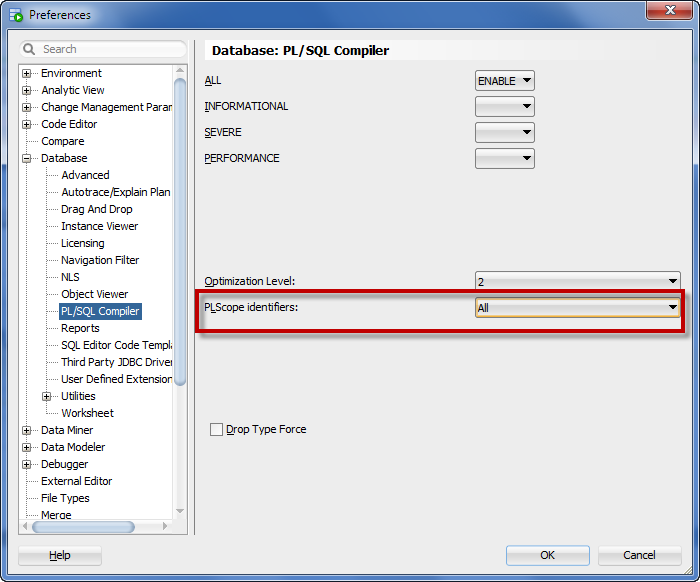
When you connect, we’ll enable this for your session so that when you compile, the PL/Scope info will be collected.
Step Two, how to go see the data.
Drumroll…
Find DB Objects, or the Object Search.
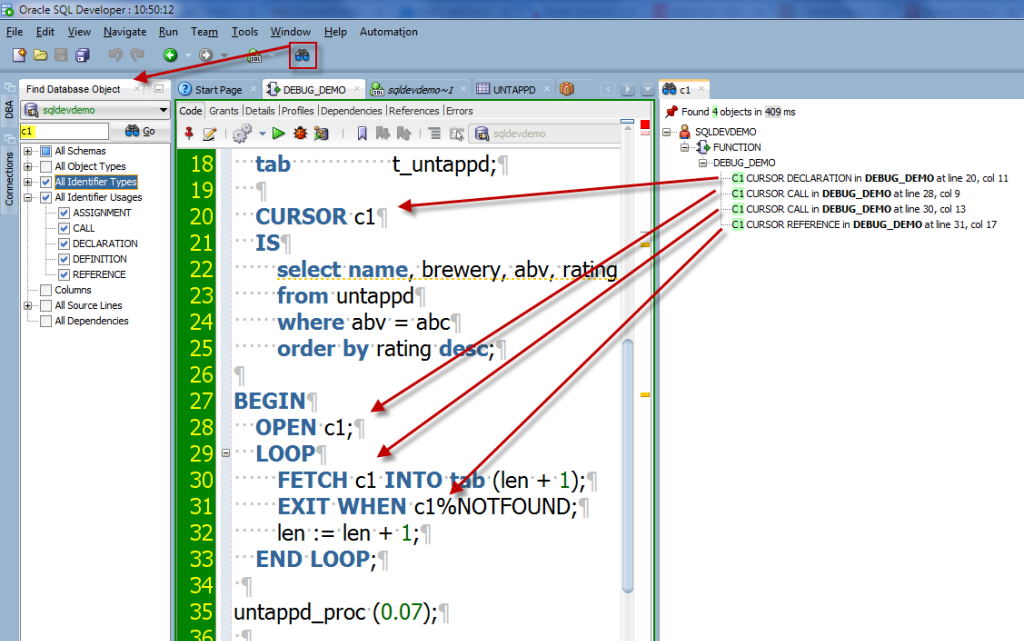
- open the search
- set your search string
- set your search depth – all schemas, your schema, a few schemas
- set your search type
- hit go
- see results
- click on result to open code editor and go to line:curpos
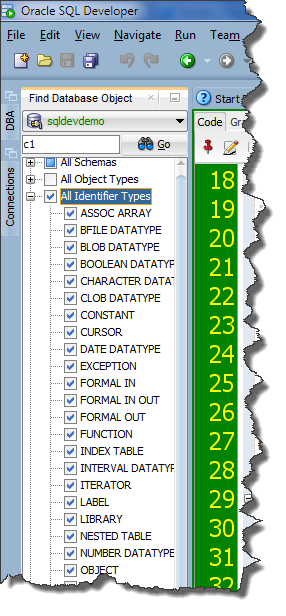
Note that there are MANY types of identifiers. The PL/SQL engine knows about ALL of them. I’ve searched across all types, but I could have easily said, Cursors only please.



17 Comments
How to delete plscope data? It is very slow when I import a schema using impdp.
change your compiler settings and re-compile the schema
Hi
If there is any possible way to get rid off from table plscope_identifier$ ?
I have similar issue and i can’t do anything to force to clean up this table.
BR
Dariusz
Hi Jeff
It would be super-helpful if settings such as this can be configured on a per-connection basis.
Hi Jeff, this is an interesting feature, by the way I’d like to point out a potential collateral effect. As you mentioned in this post, this feature is intended for development environments only and should never be used in acceptance nor production environments.
Said that, SQL Developer is a tool that is widely adopted even among DBAs and it is often used for maintenance task on PRODUCTION environments.
Recently, we used SQL Developer to compile all invalid objects on a schema and since that moment on, we’ve experienced a considerable increase of the time needed to compile source code. Even impdp tasks on schemas hosted in the same instance resulted ways slower.
The AWR report revealed the query here below was first ranked in the Top SQLs:
select pi.obj# from plscope_identifier$ pi where pi.type# in (20, 39, 55)
minus
select pi.obj# from plscope_identifier$ pi, plscope_action$ pa
where pa.signature = pi.signature
and pi.type# in (20, 39, 40, 55)
and pa.action = 4 and pa.obj# != :1
This query is run each time a package is compiled and the content of tables plscope_identifier$ and plscope_action$ comes from the feture you explained in this post. The more records we have in these tables, the longer will take to compile. Notice that gathering statistics on fixed objects didn’t solve the problem, it just gave a minimal benefit.
In conclusion, I was wondering if the idea of enabling this feature by default was actually a good one, considering that the actual use of SQL Developer is not derived by the name you gave to this great tool (I mean for development only). If I were you, I’d turn this feature off by default in order not to risk to accidentally slow down devops on non-development environment.
We assume you’re in a development environment – so things like compiling for debug are the default behaviors.
The problem with assuming is…we’re going to be wrong for a LOT of people.
So we have to figure out which group we want to help most – the n00bs, or the experts?
We’ve gone to helping the n00bs the most, because they need the most help. So things like automatic code insight is defaulted to ON.
The experts should be aware of exactly what their tools are doing, and should probably even be more acutely aware of what’s happening before they even consider touching a PRODUCTION system. As in, they’ve tested their changes in TEST first. They’ve documented said changes, and so on.
I hope there are not a bunch of people connecting to PROD with SQL Dev and just ‘clicking the buttons’ – in fact, it is somewhat rare that I find shoppes where DEVs are even allowed to connect to PROD, and if they are, it’s only with SQL*Plus. But of course there are folks like you, and that’s not ‘wrong’ – i’m not criticizing.
I’ve not investigated this before, but I wonder if it’s possible to PL/Scope at the database level…
Answering your question: yes, it is possible to PL/Scope at instance level issuing a ALTER SYSTEM.
I assume SQL Developer is either “ALTERING the SESSION” or issuing a “ALTER COMPILE” adding PL/Scope options.
If I may ask… Why are you wondering that?
I understand you position in helping the noobs, but please let me stress the point that Oracle has a plethora of settings, and it is very hard even for the most expert to monitor everything is taking place on the instances they manage.
That said, I just wanted to give this evidence on the collateral effects I experienced. The final choice is obviously yours, but I suggest to document somewhere all the Oracle defaults that are overridden by SQL Developer so that either noobs or experts can check in advance what they should expect in using this tool.
That said, I just wanted to give this evidence on the collateral effects I experienced.
Thanks for sharing, it’s valuable information of theory put in practice.
How one uses tools in production should be MUCH different than used in Dev/Test.
Hi Jeff,
in PL/SQL Developer, these reports are added as HINTS whenever you compile your source. They’re displayed along with the warnings and there’s a small option window where you can select various reports to be included as hints. That’s a nice solution and maybe a future change request for SQL Developer?
Best regards,
Jürgen
It looks pretty good, but doesn’t seem to work properly in Version 4.1.2.20. If I tick only CURSOR, I get references in comments, parameter values, table and variable names etc.
Maybe I need to download an update.
It’s working for me. For example, I can tell it to only look into variables, and we’re adding this predicate to the query on all_identifiers
AND TYPE in (‘VARIABLE’)
View > Log > Statements will show you the query the object search feature is using to bring back your results
To show the power of PL/Scope – maybe you can add some reports to the Data Dictionary Reports
– unused variables
– calling hierarchy
– check naming conventions
– …
See
https://community.oracle.com/thread/2438703
https://community.oracle.com/message/9856377
http://www.oracle.com/technetwork/issue-archive/2010/10-sep/o50plsql-165471.html
Marcus
yeah, looks nice. and of course you can always add them yourself as user defined reports
Saw you point this out at Kscope16. Very cool. Thanks!
Thanks for telling everyone in YOUR talk to come to my talk – that was very generous of you.
And your talk was the talk of the town 🙂
I didn’t know this existed, really cool.
I would only improve it by including a small preview of the line where this is used.
Lets say we have two packages – p1 and p2 – both with a function named ABC.
If I search for a function called ABC I get results where the functions for both packages are used.
If I search for p1.ABC I only get the invocations inside p1 for some reason.
Having a preview would help in this situation.
Other than that, fantastic tool!
Wow , this is cool feature .