
Summary from our Oracle Developer Coaching, June News Edition. Kris and I were back to talk more things Oracle Database and LiveSQL!




Summary from our Oracle Developer Coaching, June News Edition. Kris and I were back to talk more things Oracle Database and LiveSQL!
Fast-paced, 30-minute broadcasts, to stay in the know. Delivered newsroom-style, the monthly News Edition brings you rapid-fire updates, announcements, and insights from Oracle product teams.

Using Oracle SQLcl to execute scripts on multiple databases, concurrently, using the background command. The jobs command makes monitoring those tasks easy.
How to get started with SQLcl projects for implementing CI/CD practices for your Oracle Database by setting up your project and database for Git and Liquibase.

How to setup Oracle SQL Developer Extension for VS Code or Oracle SQLcl to authenticate your database connections using Kerberos – without an Oracle Client!
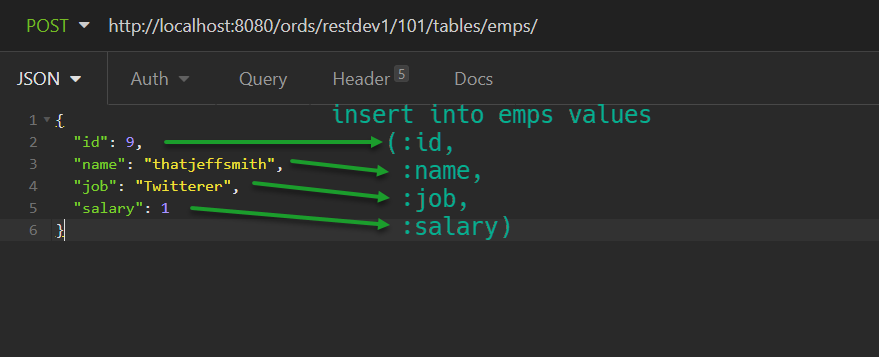
How to export all of the REST APIs across all of the schemas in your Oracle Database using Oracle REST Data Services (ORDS) version 25.1.

Oracle SQL Developer Extension for VS Code v25.1 is now available! This release includes the ability to organize your connections via folders (and subfolders!)
Easily setup your Internet of things (IOT) devices to share their telemetry data with your Oracle Database, via a secured REST API and a bit of Python.

Did you know Oracle REST Data Services now supports generating Pre-Authenticated Requests (PARs) for any of your Oracle Database REST APIs? Examples and code!
Using SQLcl to load ~29,000 records from Chicago’s open data portal to follow along with AI Vector Search PM Andy Rivenes’s getting started tutorial.






 for your Oracle REST APIs")
 with SQLcl")