
A VERY specific request this morning:
I want to generate scripts for all the tables available in schema.
I want to generate separate scripts for each table available in schema and each script must contains it’s dependent objects like indexes for that table or if triggers are available the this must include in the script.
I am using SQL developer 4.0.12 version. I tried with export option but separate scripts are generating for index,triggers,tables etc.
To get this exact formatting, we’re going to take advantage of a new option in the Data Modeler extension that’s available in Oracle SQL Developer:
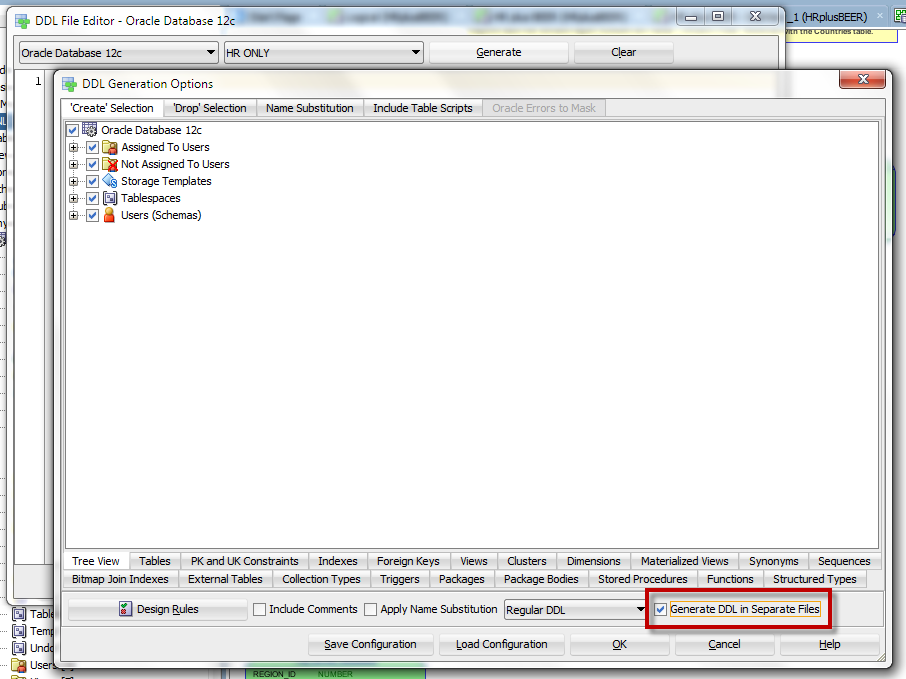
Once you import the data dictionary, you have a lot of control over exactly how the DDL is generated – and we can generate it very quickly as it’s now in the model instead of being queried/generated from the database.
Import the Data Dictionary
Do this, and walk the wizard.
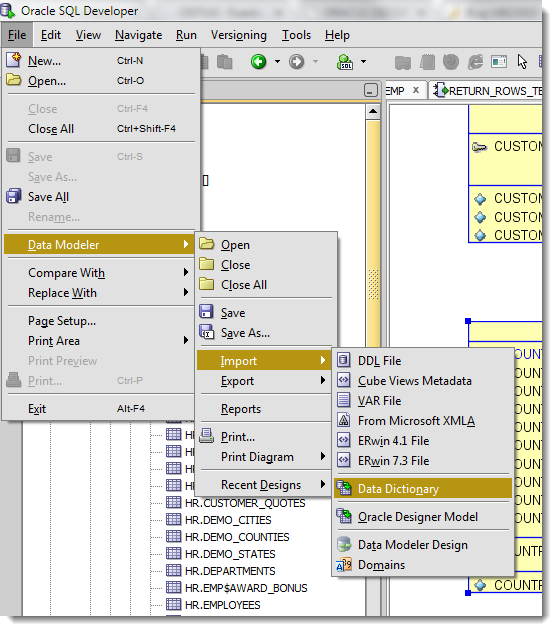
If you need some pointers, here’s a step-by-step post.
Generate the DDL
First, make sure you have the Physical Model open. This will ensure you get things like your storage parameters, triggers, etc.
Then, hit this button:

Make sure you have all of the objects selected, and then toggle the multiple files option. Then pick your output directory and go.
When you’re done, you’ll have something like this:
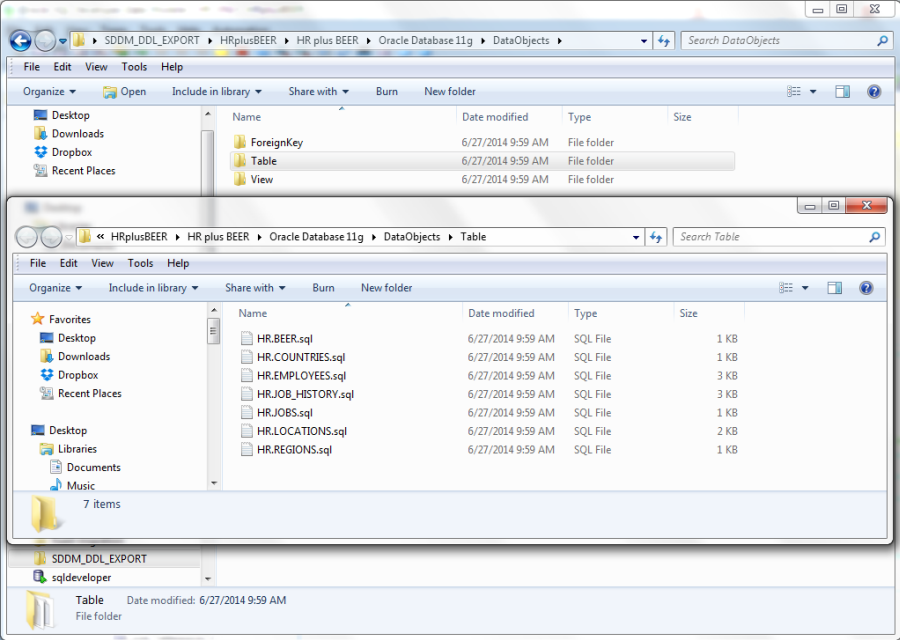
And if we open one of the table scripts:
CREATE TABLE HR.BEER ( BREWERY VARCHAR2 (100 BYTE) DEFAULT 'NOTBUD' NOT NULL , CITY VARCHAR2 (100 BYTE) , STATE VARCHAR2 (100 BYTE) , COUNTRY VARCHAR2 (100 BYTE) , ID NUMBER NOT NULL ) ; COMMENT ON TABLE HR.BEER IS 'Breweries of the world' ; COMMENT ON COLUMN HR.BEER.BREWERY IS 'Company name, appears on beer labels, often not as funny as they think they are' ; COMMENT ON COLUMN HR.BEER.CITY IS 'Corporate HQ' ; COMMENT ON COLUMN HR.BEER.STATE IS 'State or Province Corporate HQ' ; COMMENT ON COLUMN HR.BEER.COUNTRY IS 'Corporate HQ' ; COMMENT ON COLUMN HR.BEER.ID IS 'Generated by Sequence' ; CREATE INDEX HR.INDEX1 ON HR.BEER ( STATE ASC ) ; CREATE INDEX HR.BEER_COUNTRIES ON HR.BEER ( COUNTRY ASC ) ; CREATE UNIQUE INDEX HR.BEER_PK ON HR.BEER ( ID ASC ) ; ALTER TABLE HR.BEER ADD CONSTRAINT BEER_PK PRIMARY KEY ( ID ) ;
And there you go. As your database is updated, you can merge the updates into your model by using the compare feature.






14 Comments
Hi Jeff,
When I use the option “generate DDL in separate files” it doesn’t generate the trigger code for the sequence defined on columns. (I am using 4.1.5 however the same behaviour occurs with 19.2.0.182.1216)
Is this a setting that I have missed – or do I need to do some transformation scripting to generate this?
Why you guys try to invent something? Do you actually look at what other vendors doing? I think, sqldeveloper is a complete waste of time, it still can’t do formatting well, the ddl scripts are created separately. Why would I need to have keys and tables as separate statements? When yo start listening to the customers? Take a look at Pl/SQL Developer or to DataGrip. If you can’t think of better product then buy the company.
We do formatting extremely well.
Because constraints are a separate object from a table. You can’t define a foreign key constraint for a table until the other table(s) have been created. Also, we’re happy to put everything in one file if you want – you have to tell us if you want one file or many.
On this blog alone I have 15,000+ comments from users sharing feedback, collaboratively, making the product better almost every day. Plus, we have the forums, social media (Twitter and Facebook), and of course My Oracle Support – which we listen and act on all of those.
And to think, I almost lost your comment to my SPAM filter. Sorry for the late approval and reply.
Hi I note with quick ddl an interval partition is generated as it would have been when I first created it ie:
Greater than 1
When using data modeller it is extracting every partition which has been generated in production. Is there anyway to generate the ddl in the same way quick ddl does?
quick DDL in SQL Developer? data modeler doesn’t use the same mechanism as sqldev to generate DDL. The modeler does have about 100 options when it comes to generating DDL though, did you investigate them?
Hi All,
Is there is any Script or Code to do this process(with manually), if any pls help me.
I’d like a way to package together my procedures that operate on a table, along with its definition, so that all concerns for that table are in one location. I’m inclined to create a Kitchen.sql that contains them. But putting DDL in stored procedure isn’t allowed. I could wrap DDL in execute blocks. Not a great idea as it’s now runtime executed and no compile checking. But not a deal breaker. An alternative would be putting KitchenProc.sql along side with KitchenDDL.sql which meets “discovery of like things is easy because they are together” design characteristics.
Any other ideas or suggestions?
have you seen our cart feature? it allows you to build deployment packages of object scripts
Thanks! I’ll take a look. Cart sounds like it’s making the deployment part easy. What I’m really after is to get the source code organized in a sensible way so the later developer can see in the source directory (which is checked into source control):
src/database/Kitchen.sql, KitchenDDL.sql, KitchenUnitTest.sql
I thought about splitting DDLs from the procedures but that didn’t seem sensible as they all have a relationship together. To avoid being too flat in directory structure could do:
src/database/Kitchen/Kitchen.sql, …
src/database/LivingRoom/LivingRoom.sql, …
And maybe Kitchen.sql will be split into .pks and .pkg. (If I can find an advantage that outweighs the disadvantage of having them split. utPLSQL, for example can do some autocompile for me, but then in this case I’ll split the test code this way.)
In sql developer 4.0.3.16 version it still gives the trigger, index and create table script separately.
Hi Jeff
I am using sql developer 4.0.3.16, could you tell me where can I see the screen which you have in you first image. The selection ‘Generate DDL in separate files’ ??
Peter
I think, there is something missing. Which “Physical Model” are you meaning? I also didn’t get the seperate sql files for each object, I’m getting just one complete source code…
You only need to worry about the physical model if you want the physical DDL stuff like indexes, partitions, etc.
So, you checked the ‘Separate files’ box, generated the DDL and only got a single file? If so, what version of the Modeler are you running?
I dont seem to get a file explorer option to save the seperate .sql files.